|
|
OS/리눅스 & 유닉스 2012. 3. 20. 13:47
Sample File: position_list // sep=<TAB>

1. 파일 읽기
position_list파일에서 한 라인씩 데이터를 읽고 화면에 출력
while read line
do
echo $line
done < position_list
출력
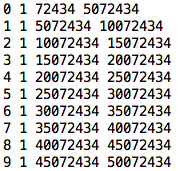
2. 파일에서 읽은 데이터를 특정 구분자에 의해 분할
$line변수에 저장 된 데이터에서 첫 번째 컬럼 정보를 가져온다. (awk를 설명하려면 내용이 많기 때문에 생략)
awk '{print $1}'은 첫 번째 컬럼만 출력 한다는 의미로 알고 넘어가면 될 것 같다. 많은 옵션들이 있지만 .. 파일의 데이터 구분자가 <TAB>으로 되어 있으면 저렇게만 써도 정상적으로 동작한다.
while read line
do
echo $line | awk '{print $1}'
done < position_list
출력
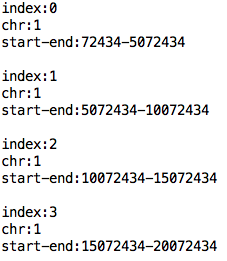
3. 2번에서 분할 된 문자를 변수에 저장해서 사용
아래 코드가 위에 꺼에 비해 조금 길어 보일 수도 있지만 .. 같은 문장이 계속 반복 되는 것을 알 수 있다.(변수명과 컬럼 번호만 다르다..)
위에서 분할 한 문자를 각 변수에 저장해 출력하는 것을 볼 수 있다...
while read line
do
index=$(echo $line | awk '{print $1}')
chr=$(echo $line | awk '{print $2}')
start_position=$(echo $line | awk '{print $3}')
end_position=$(echo $line | awk '{print $4}')
echo index:$index
echo chr:$chr
echo start-end:$start_position-$end_position
echo
done <position_list
출력
OS/리눅스 & 유닉스 2012. 3. 20. 13:45
text 데이터나 리포드를 작성 하는 데 사용 되는 프로그래밍 언어.
표준입력 으로 들어오는 데이타를 처리하여 , 표준 출력으로 출력 하는 프로그램
프롬프트상에서 간단히 입력 할 수도 있고, 복잡한 프로그램을 작성 할 수도 있다
awk 'pattern' filename
awk '{ action }' filename
awk 'pattern { action }' filename
ex>
$ awk '/닉스/' employees // 패턴검색
$ awk ' { print $1 }' employees // 파일의 모든 라인에 대해서 해당 명령 처리
$ awk '/닉스/{ print $1,$2 }' employees // 패턴검색 후 해당 라인에 대한 명령 처리
command | awk 'pattern' filename
command | awk '{ action }' filename
command | awk 'pattern { action }' filename
ex>
$ df | awk '$4 > 300000'
$ w | awk '/fith/{ print $1,$3 }'
$ date | awk '{print "현재 년도 :" $1 "\n현재 월 : " $2}'
- \b : 백 스페이스 - \f : form feed - \n : new line
- \r : carriage return - \t : tab - \x : escape caracter x
$ awk '/닉스/{print "\t\tHave a nice day," $1,$2 "!"}' employees
$ echo "UNIX" | awk '{ printf "|%-15s|\n",$1 }'
$ echo "UNIX" | awk '{ printf "|%15s|\n",$1 }'
$ awk '{ printf "The name is: %-15s ,ID is %8d\n", $1$2,$3 }' employees
- %c : ASCII 문자 하나. - %s : ASCII 문자열. - %f : 부동소수점.
- %d : 10 진수. - %o : 8 진수 . - %x : 16 진수 .
$ awk -f awkfile employees
| 변수 | 설명 |
| FILENAME |
현재파일명 |
| FS |
필드 구분자 |
| NF |
현재라인의 필드 수 |
| NR |
현재라인의 레코드 번호 |
| OFMT |
숫자 출력을 위한 포맷(예를 들어 %.6g) |
| OFS |
출력 필드 구분자(디폴트는 blank) |
| ORS |
출력 레코드 구분자(디폴트는 newline) |
| RS |
레코드 구분자(디폴트는 newline) |
| $0 |
전체 입력라인 |
| $n |
n번째 필드의 내용(각 필드는 FS로 구분된다.) |
$ awk '{ print $0 }' employees
$ awk '{ print }' employees
$ awk '{ print NR , $0 }' employees
$ awk -F: '/^root/{print $6 ,$7}' /etc/passwd
$ awk -F'[ :\t]' '{ print $1,$2,$3}' /etc/passwd
$ awk '/^[A-Z][a-z]+ /' employees
$ awk '$1 ~ /[Bb]ill/' employees
$ awk '$1 !~ /[Bb]ill/' employees
< , ⇐ , == , != , >=, > ,&& ,||,!
$ awk '$3 > 1234' employees
$ awk '$3 > 1234 && 4500 > $3' employees
$ awk '!($3 < 1234 || 4500 < $3)' employees
OS/리눅스 & 유닉스 2012. 3. 20. 13:32
Four Ways to Pass Shell Variables in AWK
As we all know, not everyone is equal. This applies to AWK too. AWK in Solaris is a very old implementation compared the GNU AWK. Here I am trying to show you 4 different ways to pass shell variable value to AWK
- This trick works on all flavours of AWK because it is taking advantage of shell substitution. Remember not to leave any space when you include a single quote, dollar variable, and a single quote in the AWK command
$ one=111
$ two=222
$ awk 'BEGIN{a='$one';b='$two'}END{print a,b}' /dev/null
111 222
- This works for all flavours of AWK too. AWK allows you to set their variable from the shell
$ one=111
$ two=222
$ awk 'END{print a,b}' a=$one b=$two /dev/null
111 222
- This will not work for Solaris awk. You have to use
nawk. The -v flag allows you to assign AWK variable.$ one=111
$ two=222
$ nawk -v a=$one -v b=$two 'END{print a,b}' /dev/null
111 222
- If your awk allows you to access the shell environment variables, you can use this trick. FYI, this will not work for Solaris awk.
$ one=111
$ two=222
$ a=$one b=$two awk 'END{print ENVIRON["a"],ENVIRON["b"]}' /dev/null
111 222
OS/리눅스 & 유닉스 2012. 3. 20. 13:12
How to read file line by line? (sh)
In general, use "while" to loop call "read" :
All example is in #!/bin/sh
1.
readline1 ()
{
inputFile=$1
cat $inputFile | while read LINE
do
echo $LINE
done
}
2.
readline2 ()
{
inputFile=$1
while read LINE
do
echo $LINE
done < $1
}
3.
readline3 ()
{
inputFile=$1
while line LINE
do
echo $LINE
done < $1
}
note: realine3 will echo 2 nowline, becase "line" will read the content include newline.
4.
readline4 ()
{
exec 3<&0
exec 0<$1
while read LINE
do
print $LINE
done
exec 0<&3
}
using fd redirection.
====================================================================
Using for loop -
for i in `cat TestFile`
do
echo $i
done
or
Using While loop -
while read line
do
echo $line
done < TestFile
=====================================================================
# User define Function (UDF)
processLine(){
line="$@"
echo $line
}
FILE=""
if [ "$1" == "" ]; then
FILE="/dev/stdin"
else
FILE="$1"
if [ ! -f $FILE ]; then
echo "$FILE : does not exists"
exit 1
elif [ ! -r $FILE ]; then
echo "$FILE: can not read"
exit 2
fi
fi
BAKIFS=$IFS
IFS=$(echo -en "\n\b")
exec 3<&0
exec 0<$FILE
while read line
do
processLine $line
done
exec 0<&3
IFS=$BAKIFS
exit 0
OS/리눅스 & 유닉스 2012. 3. 20. 12:52
read a
echo $a | awk '{printf("%s",a)}'
위의 코드에서 주의하셔야 할 것은
awk 외부의 a와 awk 내부의 a는 전혀 다른 것으로
awk 내부의 a에는 값이 할당되어 있지 않기 때문에 아무것도 출력되지 않는 것입니다
위의 코드는 read a때문에 표준입력으로 부터 값을 입력받고 그 값을 a에 저장합니다
awk는 a변수에 저장된 값을 표준입력으로부터 입력받습니다(echo $a |)
그리고 a라는 또 다른 awk 내부의 변수를 출력합니다 awk 내부의 a에는 어떤 값도
할당되어 있지 않기 때문에 아무것도 출력하지 않습니다
그렇다면 이렇게 한번 해보죠
1 read a
2 echo $a | awk '{a=1;printf("%s\n",a)}'
3 echo $a
abcd를 입력하면
결과는
1
abcd
라고 나옵니다
외부의 a에는 abcd가
내부의 a에는 1이 저장이 됩니다
각각의 변수를 awk외부에서 내부에서 참조해서 출력합니다
그렇다면 awk의 내부에서 외부 변수 a의 값을 참조하는 방법이 없을까요?
아닙니다 있습니다
awk에서 외부 변수 a에 접근하는 방법 세가지 방법
방법1
read a
echo | awk -v a="$a" '{printf("%s",a)}'
또는
read a
awk -v a="$a" '{printf("%s",a)}'
대신 위 스크립트를 실행할때
변수a에 값을 저장하고 엔터를 두번 눌러준다
첫번째 엔터는 a변수에 입력을 마치기 위해서
두번째 엔터는 awk에서 표준입력을 마치기 위해서 누르는 것입니다
방법2
read a
echo | awk '{printf("%s","'"$a"'")}'
방법3
read a
echo | awk '{printf("%s",a)}' a=$a
아래는 좀 다른데
이런 방법도 있습니다
read a
echo $a | awk '{printf "%s", $0}'
OS/리눅스 & 유닉스 2012. 3. 20. 11:29
쉘 프로그래밍 강좌
1 변수
- 쉘변수는 처음 사용될 때 만들어진다. 즉 미리 선언할 필요가 없다.
- 쉘변수는 유닉스 명령과 마찬가지로 대소문자에 구별이 있다.
- 쉘변수는 기본적으로 데이터를 문자열로 저장한다. 수치를 대입해도 실제 수치가 아닌 문자열이 저장된다. 계산이 필요할 경우는 자동으로 수치로 변환하여 계산후 다시 문자열로 저장된다.
- 쉘변수의 값을 사용할 때는 변수명앞에 "$" 를 붙여서 사용한다.
- 쉘변수에 값을 대입할때는 "$"를 사용하지 않는다.
- 쉘변수는 타입이 없다. 즉 아무 값이나 다 넣을 수 있다.
쉘을 기동하고나면 기본적으로 셋팅되어있는 변수들이다. 유닉스/리눅스에는 많은 환경변수들이 있고 필요한경우 이 변수들을 마치 일반변수처럼 값을 얻어오거나 셋팅할 수 있다. 여기서는 쉘과 직접적인 관련이 있는것만 설명한다.
- $0 - 실행된 쉘 스크립트 이름
- $# - 스크립트에 넘겨진 인자의 갯수
- $$ - 쉘 스크립트의 프로세스 ID
쉘스크립트에 인자를 넘겨줄때 그 인자들에 대한 정보를 가지고 있는 변수들.
- $1~ $nnn - 넘겨진 인자들
- $* - 스크립트에 전달된 인자들을 모아놓은 문자열. 하나의 변수에 저장되며 IFS 환경변수의 첫번째 문자로 구분된다.
- $@ - $*과 같다. 다만 구분자가 IFS변수의 영향을 받지 않는다.
2 일반변수
일반변수에 특별한 제약은 없다. 단 대소문자 구분만 정확하게 해주면 된다.
예제
#!/bin/sh
echo "This Script Executable File : $0"
echo "Argument Count : $#"
echo "Process ID : $$"
echo "Argument List \$* : $*"
echo "Argument List \$@ : $@"
echo "Argument 1 : $1"
echo "Argument 2 : $2"
echo "Argument 3 : $3"
echo "Argument 4 : $4"
실행$chmod 755 test1
$./test1 a1 a2 a3 a4
This Script Executable File : ./test1
Argument Count : 4
Process ID : 905
Argument List $* : a1 a2 a3 a4
Argument List $@ : a1 a2 a3 a4
Argument 1 : a1
Argument 2 : a2
Argument 3 : a3
Argument 4 : a4
변수의 산술 연산은 생각하는 것처럼 쉽지 않다. 위에서 언급했듯이 변수에는 모든 것이 문자열로 저장되기 때문에 연산이 불가능하다. 연산을 위해서는 좀 복잡한 절차를 거쳐야 한다. 변수 = $((산술식))
이것이 가장 단순한 연산 규칙이다. 산술식내에는 변수( $1, $a 와 같은) 도 들어갈 수 있다. 산술식 내에 숫자가 아닌 문자열, 또는 문자열이 담겨있는 변수가 들어가면 그것들은 계산에서 제외된다. (정확히 말하면 0 으로 간주되어 연산이 이루어 지지 않는다.)
2.2 매개변수 확장
매개변수 확장이란 변수의 값을 문자열 등으로 대체하는 것을 말한다. 단순한 대체뿐 아니라 변수내의 문자열을 조작하여 원하는 문자열만을 추출할 수도 있다.
형식:
- ${parm:-default} - parm이 존재하지 않으면 default로 대체된다.
- ${#parm} - parm의 길이를 참조한다.(가져온다)
- ${parm%word} - 끝에서부터 word와 일치하는 parm의 최소부분(첫번째 일치)을 제거하고 나머지를 반환한다.
- ${parm%%word} - 끝에서부터 word와 일치하는 parm의 최대부분(마지막 일치)을 제거하고 나머지를 반환한다.
- ${parm#word} - 처음부터 word와 맞는 parm의 최소부분(첫번째 일치)을 제거하고 나머지 부분을 반환한다.
- ${parm##word} - 처음부터 word와 맞는 parm의 최대부분(마지막 일치)을 제거하고 나머지를 반환한다.
word에는 와일드 카드를 사용할 수 있다.예를 보자. 1 #!/bin/sh
2
3 p="/usr/X11R6/bin/startx"
4
5 unset p
6 a=${p:-"Variable p Not found"}
7 echo $a
8
9 p="/usr/X11R6/bin/startx"
10 a=${p:-"Variable parm Not found"}
11 echo $a
12
13 a=${#p}
14 echo $a
15
16 a=${p%/*}
17 echo $a
18
19 a=${p%%/*}
20 echo $a
21
22 a=${p#*/}
23 echo $a
24
25 a=${p##*/}
26 echo $a
27
위 스크립트의 결과는 다음과 같다. Variable p Not found
/usr/X11R6/bin/startx
21
/usr/X11R6/bin
usr/X11R6/bin/startx
startx
- 6행 : 변수 p 가 제거 되었으므로 "Variable p Not found" 가 a에 들어간다.
- 10행 : 변수 p 가 있으므로 그대로 a에 들어간다.
- 13행 : a에는 변수 p의 길이가 들어간다.
- 16행 : p 에서 가장 오른쪽의 "/"부터 끝까지 지우고 나머지를 a에 넣는다.
- 19행 : p 에서 가장 왼쪽의 "/" 부터 끝까지 지우고 나머지를 a에 넣는다. (아무것도 없다)
- 22행 : p 의 처음부터 가장왼쪽의 "/" 까지 지우고 나머지를 a에 넣는다.
- 25행 : p 의 처음부터 가장 오른쪽의 "/"까지 지우고 나머지를 a에 넣는다.
3 조건 판단
쉘 스크립트에서 조건판단은 if 와 test 명령을 혼합하여 사용한다. 일반적인 예는 다음과 같다.
if test -f test1
then
...
fi
-f 는 주어진 인자가 일반 파일일 때 참이 된다.
test 명령은 [] 로 대체될 수 있다.
if [ -f test1 ]
then
...
fi
if [ -f test1 ]; then
...
fi
3.1 test 명령
test 명령의 조건은 다음과 같이 세 부류로 나누어진다.
- [ string ] - string이 빈 문자열이 아니라면 참
- [ string1 = string2 ] - 두 문자열이 같다면 참
- [ string1 != string2 ] - 두 문자열이 다르면 참
- [ -n string ] - 문자열이 null(빈 문자열) 이 아니라면 참
- [ -z string ] - 문자열이 null(빈 문자열) 이라면 참
- [ expr1 -eq expr2 ] - 두 표현식 값이 같다면 참 ('EQual')
- [ expr1 -ne expr2 ] - 두 표현식 값이 같지 않다면 참 ('Not Equal')
- [ expr1 -gt expr2 ] - expr1 > expr2 이면 참 ('Greater Than')
- [ expr1 -ge expr2 ] - expr1 >= expr2 이면 참 ('Greater Equal')
- [ expr1 -lt expr2 ] - expr1 < expr2 이면 참 ('Less Than')
- [ expr1 -le expr2 ] - expr1 <= expr2 이면 참 ('Less Equal')
- [ ! expr ] - expr 이 참이면 거짓, 거짓이면 참
- [ expr1 -a expr2 ] - expr1 AND expr2 의 결과 (둘다 참이면 참, 'And')
- [ expr1 -o expr2 ] - expr1 OR expr2 의 결과 (둘중 하나만 참이면 참, 'Or')
- [ -b FILE ] - FILE 이 블럭 디바이스 이면 참
- [ -c FILE ] - FILE 이 문자 디바이스 이면 참.
- [ -d FILE ] - FILE 이 디렉토리이면 참
- [ -e FILE ] - FILE 이 존재하면 참
- [ -f FILE ] - FILE 이 존재하고 정규파일이면 참
- [ -g FILE ] - FILE 이 set-group-id 파일이면 참
- [ -h FILE ] - FILE 이 심볼릭 링크이면 참
- [ -L FILE ] - FILE 이 심볼릭 링크이면 참
- [ -k FILE ] - FILE 이 Sticky bit 가 셋팅되어 있으면 참
- [ -p FILE ] - True if file is a named pipe.
- [ -r FILE ] - 현재 사용자가 읽을 수 있는 파일이면 참
- [ -s FILE ] - 파일이 비어있지 않으면 참
- [ -S FILE ] - 소켓 디바이스이면 참
- [ -t FD ] - FD 가 열려진 터미널이면 참
- [ -u FILE ] - FILE 이 set-user-id 파일이면 참
- [ -w FILE ] - 현재 사용자가 쓸 수 있는 파일(writable file) 이면 참
- [ -x FILE ] - 현재사용자가 실행할 수 있는 파일(Executable file) 이면 참
- [ -O FILE ] - FILE 의 소유자가 현재 사용자이면 참
- [ -G FILE ] - FILE 의 그룹이 현재 사용자의 그룹과 같으면 참
- [ FILE1 -nt FILE2 ] - : FILE1이 FILE2 보다 새로운 파일이면 ( 최근파일이면 ) 참
- [ FILE1 -ot FILE2 ] - : FILE1이 FILE2 보다 오래된 파일이면 참
- [ FILE1 -ef FILE2 ] - : FILE1 이 FILE2의 하드링크 파일이면 참
if 문은 조건을 판단하여 주어진 문장을 수행한다.
3.2.1 형식 1 (단일 if 문)
형식: if [ 조건 ]
then
문장1
문장2
fi
3.2.2 형식 2 (if-else 문)
형식: if [ 조건 ]
then
문장3
문장4
fi
3.2.3 형식 3 (if-elif 문)
형식: if [ 조건 ]
then
문장1
문장2
elif
문장3
문장4
else
문장5
문장6
fi
3.3 case 구문
'패턴'에는 * 문자, 즉 와일드카드를 사용할 수 있다.
형식: case 변수 in
패턴 [ | 패턴 ] ... ) 문장 ;;
패턴 [ | 패턴 ] ... ) 문장 ;;
....
* ) 문장 ;;
esac
여러 명령을 실행할때 앞의 명령의 결과에 의해서 다음행동이 결정되어야 할 경우가 있다. 이런경우에 AND나 OR조건을 사용해서 한번에 처리할 수 있다. 이것은 쉘 스크립트 뿐 아니라 명령행에서도 사용 가능하다. 물론 if 문을 이용해서 반환값을 검사하여 처리할 수 있지만 문장이 길어지고 복잡해진다.
statment1 && statment2 && statmentN && .....
위의 명령들은 각 명령이 거짓이 될 때 까지 명령을 수행해 나간다. 수행 도중 결과가 거짓이 되면 그이후의 명령은 수행되지 않는다.
statment1 || statment2 || statmentN || .....
위의 명령들은 각 명령이 거짓이 나오는 동안 계속된다. 즉 참이 나오면 실행을 멈춘다.
3.4.3 AND와 OR목록은 혼용이 가능하다.
[ 조건 ] && 문장1 || 문장2
위의 예는 조건이 참이면 문장1을 수행하고 거짓이면 문장2를 수행한다.
또한 위의 문장1이나 문장2에서 여러개의 문장을 수행하고 싶을 때는 {}를 사용하면 된다. [조건] && {
문장1
문장2
문장3
} || {
문장4
문장5
문장6
}
for 문은 지정된 범위안에서 루프를 수행한다. 범위는 어떤 집합도 가능하다.
형식: for 변수 in 값1, 값2, ...
do
문장
done
매 루프를 돌때마다 변수의 값은 in 이후의 값으로 대체된다.
예제: for str in "test1", "test2", "test3", "test4"
do
echo @str
done
출력: test1
test2
test3
test4
값에는 와일드 카드 확장을 사용할 수 있다. for file in $(ls -a | grep "^\.")
do
echo "$file is Hidden File"
done
위 예의 출력 결과는 현재 디렉토리에서 처음이 "." 으로시작하는 파일(히든파일)만을 출력한다.
for file in $(ls chap[345].txt); do
echo "--- $file ---" >> Books.txt
cat $file >> Books.txt
done
위의 예는 chap3.txt, chap4.txt, chap5.txt 파일을 Books.txt 라는 파일에 붙여 넣는다.
다음의 예를 보고 결과를 예측해보자. echo "\$* output"
for fvar in $*
do
echo $fvar
done
echo "\$@ output"
for fvar in $@
do
echo $fvar
done
for 명령의 경우는 횟수를 지정해서 루프를 수행하는 데는 문제가 있다. while 문은 실행 횟수가 지정되지 않았을 때 편리하다.
예제를 보자. 패스워드를 입력받고 맞는지 확인하는 프로그램이다. echo "Enter Password : "
read password1
echo "Retype Password : "
read password2
while [ "$password1" != "$password2" ]
do
echo "Password mismatch Try again "
echo "Retype Password : "
read password2
done
echo "OK Password Match complete"
until은 while문과 동일한 효과를 내지만 조건이 반대이다. 즉, while문은 조건이 참일동안 루프를 수행하지만 until은 조건이 거짓일 동안 루프를 수행한다.
다음 예를 보자. 이 예는 지정한 유저가 로그인하면 알려준다. #!/bin/sh
until who | grep "$1" > /dev/null
do
sleep 10
done
echo "User $1 just logged in ^_^"
4.4 select
select문은 원하는 리스트를 출력하고 그 중 선택된 것을 돌려주는 구문이다. 주의할 점은 select의 루프 내에서는 자동적으로 루프를 벗어날 수 없다. 반드시 break문을 사용해서 루프를 벗어나야 한다.
예: 간단한 퀴즈 #!/bin/sh
echo "다음중 스크립트언어 프로그래밍에 속하는 것은 ?"
select var in "쉘 프로그래밍" "C 프로그래밍" "자바 프로그래밍" "Exit"
do
if [ "$var" = "쉘 프로그래밍" ]
then
echo "정답입니다."
exit 0
elif [ "$var" = "Exit" ]
then
echo "종료합니다."
exit 1
else
echo "$var 을 선택하셨습니다. 오답입니다."
echo "다음중 스크립트언어 프로그래밍에 속하는 것은 ?"
fi
done
5 함수
쉘 스크립트 내부에 또는 다른 스크립트파일에 함수를 정의해 놓고 사용할 수 있다. 함수를 사용하면 코드를 최적화 할 수 있고, 코딩이 간결해지며,재사용이 가능하다. 그러나 다른 스크립트 파일을 호출해서 함수를 실행할 경우, 가능은 하지만 스크립트의 실행시간이 길어지고, 함수의 결과를 전달하는 것이 까다롭기 때문에 가급적이면 외부파일의 함수는 안쓰는 것이 좋다.
형식: 함수명 ()
{
문장
return 값
}
함수는 독립적으로 $#, $*, $0 등의 인자 변수를 사용한다. 즉 함수내의 $#과 본체의 $#은 다를 수 있다는 것이다.
다음의 예를 보자 #!/bin/sh
func()
{
echo ------ this is func --------
echo "This Script Executable File : $0"
echo "Argument Count : $#"
echo "Process ID : $$"
echo "Argument List \$* : $*"
echo "Argument List \$@ : $@"
echo "Argument 1 : $1"
echo "Argument 2 : $2"
echo "Argument 3 : $3"
}
echo ------ this is main --------
echo "This Script Executable File : $0"
echo "Argument Count : $#"
echo "Process ID : $$"
echo "Argument List \$* : $*"
echo "Argument List \$@ : $@"
echo "Argument 1 : $1"
echo "Argument 2 : $2"
echo "Argument 3 : $3"
echo "Argument 4 : $4"
func aa bb cc
본체와 함수에서 동일한 변수를 보여주지만 값은 틀린다는 것을 알 수 있다.
함수에서 값을 반환하기 - 함수에서 반환값은 반드시 정수값만을 반환할 수 있다. 이 값을 if 등으로 조건을 판단해서 사용할 수 있다. 반환값 중 0은 참으로 나머지 숫자는 거짓으로 판별된다.
6 명령어
쉘에서 쓸 수 있는 명령어는 두가지로 나누어진다. 명령 프롬프트 상에서 실행 시킬 수 있는 외부 명령어와 쉘 내부 명령이다. 내부 명령은 보통 쉘 내부나 쉘 구문상에서 쓰인다. 외부명령은 쉘에 관계없이 사용이 가능하다.
제어문이나 조건문의 루프를 빠져나갈때 사용한다.
예제 while [ $a -eq 10 ]
do
if [ $a -eq 5 ]; then
break
fi
done
6.2 continue
제어문이나 조건문의 처음으로 돌아가서 다시수행한다.
예제 while [ $a -eq 10 ]
do
if [ $a -eq 5 ]; then
continue
fi
done
의미없는 명령. 논리값 true를 대신해 쓰기도 한다.
. 명령을 사용하면 현재 쉘에서 명령을 실행시킨다 그러므로 실행된 명령의 결과를 본 프로그램에서 사용할 수 있다.
예를 들면 A 라는 스크립트에서 B라는 스크립트를 그냥 실행할 경우 B에서의 변화(환경변수 등)는 A에게 아무런 영향도 미치지 않는다. 그러나 . 명령을 사용해서 실행하면 B에서의 변화가 A에도 영향을 미친다.
문장을 출력한다. 자동으로 개행문자가 삽입된다. (다음 줄로 넘어간다)
인자의 실제 값을 구하는데 사용한다. foo=10
x=foo
y='$'$x
echo $y
이 예를 실행해 보면 $foo가 출력된다 foo=10
x=foo
eval y='$'$x
echo $y
이 예에서는 $foo의 값 즉 10 이 출력된다. eval명령은 원하는 문자열들을 조합해서 변수를 액세스 할 수 있다.
6.8 exit n
현재 쉘을 종료한다. 종료시 n 값을 리턴한다.
6.9 export
해당 쉘에서 파생된 자식 프로세스에서 export한 환경변수는 본래 쉘에서 관리한다.
표현식의 값을 구한다. x=`expr 1 + 2`
요즘은 expr보다는 $((계산식)) 구문을 많이 사용한다.
C 언어의 printf명령과 흡사하다.
형식: printf "Format String" arg1 arg2 arg3 ...
쉘 함수에서 값을 반환 할 때 쓰인다. 0은 성공을 1~125까지는 쉘 에러코드를 나타낸다.
쉘 내부에서 매개 인자를 설정한다. set의 인자로 쓰인 문자열은 공백에 의해 $1 부터 차례대로 대입된다.
예제 #!/bin/sh
echo $#
set $(ls)
echo $#
이다. (22는 필자의 ls 결과의 갯수이다.) 첫번째 0는 이 스크립트에 인수가 없으므로 0이고 set $(ls) 에 의해서 인수의 갯수가 22개로 늘었다.
쉘의 인자를 한자리씩 아래로(n -> 1 로) 이동시킨다.
예제 #!/bin/sh
echo $1
shift
echo $1
shift 5
echo $1
실행 #./myscript 1 2 3 4 5 6 7 8 9 0
1
2
7
쉘의 실행도중 시그널을 처리하는 시그널 처리기를 만드는 역할을 한다.
쉘 스크립트는 위에서 아래로 실행되므로 보호하려는 부분 이전에 trap 명령을 사용해야 한다. trap 조건을 기본으로 사용하려면 명령에 - 를 넣으면 된다. 신호를 무시하려면 '' 빈 문자열을 준다.
7 명령 실행
외부 명령의 실행 결과를 변수에 집어넣어 변수의 값으로 사용할 수 있다.
이렇게 변수에 결과를 넣은 후에는 이 변수를 일반문자열로 생각하고 원하는 가공을 해서 결과를 얻어낼 수 있다. 위에서 보았던 매개변수 확장이나 set명령을 이용해서 원하는 부분을 추출해 내면 그만이다.
8 쉘 스크립트 내부에서 명령에 입력 전달하기 (Here Documents)
이 기능은 쉘 내부에서 명령어에 입력을 전달하는 방법이다. 전달된 입력은 마치 키보드에서 눌려진 것처럼 반응한다.
형식: 명령 << 종료문자열
입력값.....
종료문자열
예제: 자동으로 메일을 보내는 스크립트 #!/bin/sh
mail $1 << myscript
This is Header
This is Body
.
myscript
9 디버깅 하기
쉘 프로그래밍 시 간단하게 디버깅하는 방법을 소개합니다.
- sh -n 스크립트 : 문법 에러만을 검사, 명령을 실행하지 않음
- sh -v 스크립트 : 명령을 실행하기 전에 에코
- sh -x 스크립트 : 명령줄에서 처리한 다음 에코
9.2 set 옵션
위의 쉘 옵션은 아래와 같이 set 옵션으로도 설정할 수 있다.
- set -o noexec 또는 set -n : 문법 에러만을 검사, 명령을 실행하지 않음
- set -o verbose 또는 set -v : 명령을 실행하기 전에 에코
- set -o xtrace 또는 set -x : 명령줄에서 처리한 다음 에코
- set -o nounset 또는 set -u : 정의되지 않은 변수가 사용되면 에러 메시지를 제공한다.
아래와 같이 set -x를 이용하여 손쉽게 실행과정을 추적할 수 있다. (참고로 set 옵션을 취소하려면 set +x를 입력하면 된다. 다른 옵션도 마찬가지) set -x
for str in "test1" "test2" "test3" "test4"
do
echo $str
done
결과 + for str in '"test1"' '"test2"' '"test3"' '"test4"'
+ echo @str
@str
+ for str in '"test1"' '"test2"' '"test3"' '"test4"'
+ echo @str
@str
+ for str in '"test1"' '"test2"' '"test3"' '"test4"'
+ echo @str
@str
+ for str in '"test1"' '"test2"' '"test3"' '"test4"'
+ echo @str
@str
OS/리눅스 & 유닉스 2012. 3. 20. 09:34
http://cafe.naver.com/q69/82482. apache의 환경 설정(1)
◎ ServerType standalone
서버의 실행 타입을 설정하는 부분이다. 타입은 standalone과 inetd 두가지 방식이 있다.
standalone은 데몬이 항상 떠 있어서 사용자의 요청이 있을 경우 바로 반응을 나타내지만, 항상 메모리를 차지하고 있다는 단점이 있다.
inetd는 inetd라는 프로세스에 의해 필요할 때만 apache 데몬이 불러들여지는 것이다. 따라서 반응은 느리지만 항상 떠 있지 않으므로 필요없는 메모리는 차지하지 않고 있다.
보통 웹서버는 많은 사람들의 요청이 계속 이어지는 데몬이므로 standalone을 많이 쓴다.
◎ ServerRoot "apache가 설치된 디렉토리"
아파치 서버의 루트디렉토리이다. 아파치 프로그램의 웹문서가 위치하는 DocumentRoot와 구분지을 필요가 있다.
◎ Timeout 300
서버나 클라이언트의 통신장애로 인해 클라이언트에서 완벽한 처리를 하지 못할때 연결을 해제하기 위한 설정시간이다.
◎ KeepAlive On
클라이언트가 서버에 접속 후 일정시간동안 접속을 유지할 것인지의 여부를 정하는 것이다. 일정시간 접속이 없으면 접속을 해제하며, 일정 시간내에 다른 요청이 있을 경우에는 접속을 계속 유지한다.
시간 설정은 KeepAliveTimeout 옵션으로 설정한다.
◎ MaxKeepAliveRequests 100
KeepAlive 최대 접속 수이다.
◎ KeepAliveTimeout 15
KeepAlive를 유지할 시간이다. 한번의 접속 후 이 시간동안 또 다른 접속이 없을 경우에는 접속은 끊어진다.
◎ MinSpareServers 5
최소 예비 프로세스이다. 아무리 접속이 없다 하더라도 여기에 설정한 개수만큼의 프로세스는 떠 있게 된다. Root 권한으로 떠 있는 것을 제외한 nobody 권한으로 떠 있는 것만을 가르킨다.
◎ MaxSpareServers 10
필요없이 아파치 프로세스가 많이 떠 있을 경우에는 이 설정값에 맞게 프로세스 개수를 줄인다. 이 역시 nobody 권한으로 되어 있는 프로세스만 해당한다.
◎ StartServers 5
아파치가 처음 실행 될 때 뜨게 되는 프로세스 개수이다. 만일 이 설정값이 MinSpareServers 값보다 작을 경우에는 실행 후 바로 MinSpareServers에서 설정한 개수 만큼 프로세스가 생성되므로 값을 MinSpareServers와 같거나 크게 설정하는 것이 좋다.
◎ MaxClients 150
최대 동시 접속자 수이다. 최대값은 255이며 더 늘리기 위해서는 아파치 소스의 httpd.h를 수정 후 다시 컴파일 해야 한다.
◎ MaxRequestsPerChild 0
아파치의 자식 프로세스가 처리할 수 있는 최대 요청 처리 건수이다. 0으로 설정해 두면 요청건수에 제한을 두지 않는다는 의미이다.
◎ Port 80
아파치가 사용할 포트이다.
◎ User nobody
◎ Group nobody
아파치가 자식 프로세스를 사용할 때 사용할 소유자와 소유그룹을 설정한다. 기본설정을 그대로 쓰는 것이 좋다.
◎ ServerAdmin webmaster@domain
아파치 서버관리자 이메일을 설정하는 곳이다.
◎ ServerName domain
서버의 이름을 설정한다.
◎ DocumentRoot "/usr/local/apache/htdocs"
웹문서가 위치할 경로를 절대경로러 써 넣는 곳이다.
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
시스템 루트 디렉토리 밑에 적용될 점들을 나열한다.
<Directory "/usr/local/apache/htdocs">
Options FollowSymLinks MultiViews
Order allow,deny
Allow from all
</Directory>
DocumentRoot 밑에 적용될 점들을 나열한다.
<Directory /home/*/public_html>
AllowOverride FileInfo AuthConfig Limit
Options MultiViews Indexes SymLinksIfOwnerMatch IncludesNoExec
<Limit GET POST OPTIONS PROPFIND>
Order allow,deny
Allow from all
</Limit>
<LimitExcept GET POST OPTIONS PROPFIND>
Order deny,allow
Deny from all
</LimitExcept>
</Directory>
각 계정별 디렉토리 밑에 적용될 점들을 나열한다.
◎ Options
- FollowSymLinks : 실볼릭 링크를 허용한다.
- SymLinksIfOwnerMatch : 링크를 허용하지만 링크 하고자 하는 사용자의 소유로 되어 있는 것만 링크 가능하다.
- ExecCGI : CGI 실행을 허용한다.
- Includes : SSI(Server Side Includes)를 허용한다.
- IncludesNOEXEC : SSI를 허용하지만 "#exec" 와 "include"로 정의한 CGI 실행은 거부한다.
- Indexes : 웹 서버의 디렉토리에 접근 했을 때 DirectoryIndex 지시자로 설정한 파일이 없을 경우 디렉토리안의 파일 목록을 보여준다. 이 옵션을 넣게 되면 해당 디렉토리안의 파일 목록이 보이게 되므로 보안상 보여주지 않는 것이 좋다.
- MultiViews : 클라이언트의 요청에 따라 적절하게 페이지를 보여준다.
- None : 모든 설정을 부정한다.
- All : MultiViews를 제외한 옵션을 의미한다.
◎ AllowOverride
AllowOverride는 클라이언트의 디렉토리 엑세스 제어에 관한 설정이다. AllowOverride 는 아래에 나올 AccessFileName 지시자와 관련이 있다.
AccessFileName에서 설정한 파일을 참고로 엑세스를 제어한다. ◎ DirectoryIndex index.html index.htm index.php index.php3
주소를 칠 때 디렉토리까지만 입력했을 경우 자동으로 찾아주는 페이지를 설정하는 부분이다. 위의 경우 index.html 파일이 없을 경우에는 index.htm을 index.htm 파일도 없을 경우에는 index.php를 찾아준다.
이 기능을 이용하면 메인페이지의 이름을 변경하지 않고 인트로 페이지를 생성할 수 있다.
◎ AccessFileName .htaccess
지난번에 다루었던 디렉토리 엑세스 관련 내용이다. 디렉토리 엑세스 권한에 관련된 파일의 이름을 설정하는 옵션이다.
◎ HostnameLookups Off
아파치의 로그 파일에 보면 어디서 접속했는지 아이피가 기록된다. 이 설정을 On으로 하게 되면 Dns에 질의를 한 후 아이피를 도메인으로 변환하여 기록하게 된다. 따라서 아파치의 속도가 느려질 수 있다.
◎ ErrorLog /usr/local/nanulHome/nanulCore/apache/logs/error_log
아파치의 에러 로그 기록파일 옵션이다.
◎ LogLevel warn
아파치 로그 레벨 설정 옵션이다. debug, info, notice, warn, error, crit, alert, emerg 중에 하나를 쓸 수 있다고 하네요.^^ 자세한 건 저도 잘 모르고 그냥 기본설정 쓰고 있습니다.^^
LogFormat "%h %l %u %t "%r" %>s %b "%{Referer}i" "%{User-Agent}i"" combined
LogFormat "%h %l %u %t "%r" %>s %b" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent
로그 기록 형식을 정의한다. 기본으로 4가지가 설정되어 있다. common은 일반적인 기록, referer는 이전 사이트의 주소, agent는 접속자의 OS, 브라우져 등을 기록한다.
◎ CustomLog /usr/local/nanulHome/nanulCore/apache/logs/access_log common
# If you would like to have agent and referer logfiles, uncomment the
# following directives.
#
#CustomLog /usr/local/nanulHome/nanulCore/apache/logs/referer_log referer
#CustomLog /usr/local/nanulHome/nanulCore/apache/logs/agent_log agent
아파치 엑세스 로그 파일에 대한 설정옵션이다. 주석문에서도 알 수 있듯이 접속자의 이전경로, 브라우져, OS 등을 알고 싶다면 common대신에 다른 로그기록 형식을 지정해 줄 수 있다.
◎ Alias /icons/ ""/usr/local/apache/icons/"
디렉토리를 alias 시켜준다. 만일 aaa.com이란 도메인 밑에 icons라는 디렉토리에 웹에서 접근할려고 한다면 apache는 /usr/local/apache/icons/라는 디렉토리로 alias 시켜 준다.
앞의 "/icons/"는 웹상에서의 경로 즉 Document Root이며 "/usr/local/apache/icosn/" 경로는 시스템 경로이다.
◎ ScriptAlias /cgi-bin/ "/usr/local/apache/cgi-bin/"
alias와 같은 형태이고 스크립트를 실행시킬 디렉토리를 alias 시켜준다.
◎ IndexOptions FancyIndexing
옵션에서 Indexes 옵션을 줄 경우 해당 디렉토리가 보인다고 지난번 강좌에서 이야기 했었다. 이때 이 옵션이 설정되어 있으면 파일의 크기, 생성날짜 등을 보여주게 된다.
물론 Indexes 기능을 사용하지 않을 경우에는 상관없다.
◎ DefaultIcon /icons/unknown.gif
디렉토리 내의 파일을 보여줄 때 해당 파일과 매칭되는 아이콘이 없을 경우 보여주는 아이콘이다.
◎ AddType application/x-httpd-php .php .inc .html .php3 .htm
확장자가 php가 아닌 파일도 php로 인식해서 실행시킬 수 있도록 확장자를 이곳에 등록시킬 수 있다. 참고로 db 커넥션 파일의 확장자를 inc로 하는 경우가 많으므로 inc 역시 웹상에서는 보이지 않도록 이곳에 등록해 주는 것이 좋다.
등록하지 않을 경우에는 웹브라우져에 해당 파일의 경로를 적어주면 브라우져 상에서 내용이 바로 보여지게 되므로 매우 위험하다.
ErrorDocument 500 "The server made a boo boo."
ErrorDocument 404 /missing.html
ErrorDocument 402 http://some.other_server.com/subscription_info.html
아파치 서버에러가 발생시에 보여줄 페이지를 설정할 수 있다. 기본은 주석처리 되어 있으므로 기본 페이지를 보여주게 된다. 하지만 이 옵션을 설정하게 되면 에러시 서버관리자가 원하는 페이지를 보여줄 수 있다.
보여주는 형식은 텍스트, 서버내 특정 html 또는 CGI 페이지, 다른 서버에 있는 페이지 등이 있다.
OS/리눅스 & 유닉스 2012. 3. 20. 09:28
HOW-TO Configuration httpd.conf(apache)
ServerType Standalone
# 서버 타입을 설정하는 지시자 이다.
# ServerType 에서 설정할 수 있는 것은 Standalone 과 inetd 두가지 설정이 있다.
ServerRoot /usr/local/apache
# 아파치 서버의 루트 디렉토리를 설정한다.
PidFile /usr/local/apache/logs/httpd.pid
# 아파치가 실행될 때 생성되는 httpd.pid 파일이 생성될 경로를 지정한다.
ScoreBoardFile /usr/local/apache/logs/httpd.scoreboard
#부모 프로세스가 자식 프로세스와 의사 소통을 할 때 사용되는 지시자와 그 파일을 지정한다.
Timeout 300
# Timeout은 클라이언트에서 서버로 접속할 때 클라이언트나 서버의 통신장애로 인해 300초 동안 클라이언트에서
# 완벽한 처리를 하지 못할 때 클라이언트와의 연결을 해제한다.
KeepAlive On
# 서버와의 지속적인 연결을 하도록 설정되어 있다. 즉 한번의 연결에 대해 한번의 요청만 처리하는 것이 아니라 또 다른
# 요청을 기다리게 된다. 하지만 지속적인 연결 시간은 KeepAliveTimeout 값에 설정한 만큼 유지된다.
# KeepAlive를 Off로 설정하게 되면 클라이언트로 부터 한번의 요청을 받은 후 바로 접속을 해제한다.
# 특별한 경우가 아니라면 On 상태로 유지하는 것이 좋다.
MaxKeepAliveRequests 100
# KeepAlive 상태에서 처리할 최대 요청 처리 건수를 설정한다.
# 보통의 웹 사이트에서는 설정값 100으로 충분하다.
KeepAliveTimeout 15
# KeepAlive 상태를 유지할 시간을 초 단위로 설정한다.
MinSpareServers 5
# 아파치가 실행될 때 최소 예비 프로세스 수를 설정한다. 이 값에 의해 현재 nobody 소유의 아파치 프로세스가 5보다
# 작을 경우 자동으로 부족한 만큼의 아파치 프로세스 생성한다.
# 8 정도 설정하는 것이 적당하다.
MaxSpareServers 10
# 아파치가 실행될 때 최대 예비 프로세스 수를 설정한다. 이 값에 의해 현재 nobody 소유의 아파치 프로세스가 10보다
# 클 경우 불필요한 프로세스를 제거한다.
# 20 정도 설정하는 것이 적당하다.
StartServers 5
# 아파치가 실행될 때 생성 시키는 자식 프로세스 수이다.
# 하지만 이 값이 MinSpareServers 값보다 작을 경우 아파치 실행 후에 바로 MinSpareServers 의 설정만큼 생성하기
# 때문에 아무런 의미가 없게 된다. StartServer 값과 MinSpareServers 값은 같은 값을 설정하는것이 바람직하다.
MaxClients 150
# 아파치 서버의 동시 접속자 수를 정의한다.
# 최대 값은 256이다.
# 256 이상의 값을 설정하고 싶을 때는 아파치 소스의 httpd.h 헤어 파일의 HARD_SERVER_LIMIT 부분을 수정하고
# 아파치를 다시 컴파일 해야 된다.
MaxRequestsPerChild 0
# 아파치의 자식 프로세스가 처리할 수 있는 최대 요청 처리 건수를 설정한다.
# 0 은 무제한을 뜻한다.
BindAddress *
# 가상 호스트를 지워한다. 기본적으로 주석 처리 되어 있지만 실제로는 가상 호스트에 영향을 주지 않았다.
Port 80
# 아파치가 사용할 기본 포트를 지정한다.
User nobody
Group nobody
# 자식 프로세스가 생성될 때 그 프로세스의 소유자와 소유그룹을 결정한다.
# 보안상 절대 root 로 설정하는 일은 없도록 한다.
ServerAdmin admin@rootman.co.kr
# 아파치 서버 관리자 e-mail을 설정하는 부분이다.
ServerName rootman.co.kr
# 아파치 서버가 작동중인 서버 이름을 설정한다. 기본적으로 주석 처리 되어 있다.
# 도메인이 아닌 IP 주소로 사용자의 홈페이지에 접속할 때 URL 끝에 /를 붙여야 접속이 되는 경우가 있는데 이럴 경우
# ServerName 지시자에 주석을 제거 하고 아이피 주소를 설정해 주면 된다.
DocumentRoot "/usr/local/apache/htdocs"
#아파치의 웹 문서들의 루트 디렉토리를 지정한다.
# 아래 부터 디렉토리 제어이다. Directory 구문에 대한 자세한 설명은 아래에 있다.
# 시스템 루트( / ) 디렉토리에 대한 제어
<Directory />
Options FollowSymLinks
AllowOverride None
</Directory>
# /usr/local/apache/htdocs 디렉토리에 대한 제어
<Directory " /usr/local/apache/htdocs">
Options Indexes FollowSymLinks MultiViews
AllowOverride None
Order allow,deny
Allow from all
</Directory>
# 사용자 홈 디렉토리인 public_html 디렉토리에 대한 제어
<Directory /home/*/public_html>
AllowOverride FileInfo AuthConfig Limit
Options MultiViews Indexes SymLinksIfOwnerMatch IncludesNoExec
<Limit GET POST OPTIONS PROPFIND>
Order allow,deny
Allow from all
</Limit>
<LimitExcept GET POST OPTIONS PROPFIND>
Order deny,allow
Deny from all
</LimitExcept>
</Directory>
디렉토리 제어와 관련된 설정과 옵션 설명 디렉토리 제어문의 시작은 <Directory DIR_Path> 로 시작해서 </Directory> 로 끝난다.
# -->> Options(옵션) 설명 ;
옵션 구문은 Options 라는 키워드로 시작된다.
FollowSymLinks : 실볼릭 링크를 허용한다.
SymLinksIfOwnerMatch : 링크를 허용하지만 링크 하고자 하는 사용자의 소유로 되어 있는 것만 링크 가능하다.
ExecCGI : CGI 실행을 허용한다.
Includes : SSI를 허용한다.
IncludesNOEXEC : SSI를 허용하지만 "#exec" 와 "include"로 정의한 CGI 실행은 거부한다.
Indexes : 웹 서버의 디렉토리에 접근 했을 때 DirectoryIndex 지시자로 설정한 파일이 없을 경우 디렉토리안의 파일 목록을
보여준다.
MultiViews : 클라이언트의 요청에 따라 적절하게 페이지를 보여준다. 쉽게 생각하면 HTTP 헤드 정보가 Accept-Language:ko 라면 Korea 언어에 맞게 데이터를 클라이언트에 전송한다.
None : 모든 설정을 부정한다.
All : MultiViews를 제외한 옵션을 의미한다.
# -->> AllowOverride 설명
AllowOverride는 클라이언트의 디렉토리 접근 제어에 관한 설정이다.
AllowOverride 는 AccessFileName 지시자와 밀접한 관계를 가지고 있다.
아래의 각 설정값들은 AccessFileName 지시자에서 설정한 파일에 적용된다.
None : AllowOverride를 off 한다는 것이다.
All : AccessFileName 지시자로 설정한 파일에 대해 민감하게 반응한다. 모든 지시자를 사용할 수 있다.
AuthConfig : AccessFileName 지시자에 명시한 파일에 대해서 사용자 인증 지시자 사용을 허락한다.
--> AuthDBMGroupFile, AuthDBMUserFile, AuthGroupFile, AuthName, AuthType, AuthUserFile, require등을 사용할 수 있다.
FileInfo : AccessFileName 지시자로 설정한 파일에 대해서 문서 유형을 제어하는 지시자 사용을 허락한다.
--> AddEncoding, AddLanguage, AddType, DefaultType, ErrorDocument, LanguagePriority등을 사용할 수 있다.
Indexes : AccessFileName 지시자로 설정한 파일에 대해서 디렉토리 Indexing을 제어하는 지시자 사용을 허락한다.
--> AddDescription, AddIcon, AddIconByEncoding, AddIconByType, DefaultIcon, DirectoryIndex, FancyIndexing, HeaderName, IndexIgnore, IndexOpions, ReadmeName등을 사용할 수 있다.
Limit : AccessFileName 지시자로 설정한 파일에 대해서 호스트 접근을 제어하는 지시자 사용을 허락한다.
--> Allow, Deny, order 등을 사용할 수 있다.
Options : AccessFileName 지시자에 명시한 파일에 대해서 Options 그리고 XBiHack 등과 같은 지시자 사용을 허락한다.
--> Options, XBitHack등을 사용할 수 있다.
AloowOverride와 AccessFileName에 설정한 파일을 이용해서 아파치 인증 기능을 사용할 수 있다.
아파치 인증에 관한 자세한 설명은 "아파치 인증" 강좌를 참고하길 바란다.
################################################################################################################
DirectoryIndex index.html
# 파일 이름을 명시하지 않고 디렉토리에 접근할 경우 자동으로 보여줄 파일 이름을 설정한다.
# 여러개의 파일 이름을 설정할 수 있다. 파일 이름에 대한 구분은 Space 키, 즉 빈 공간으로 구분한다.
AccessFileName .htaccess
# 특정 디렉토리의 접근 제어를 할 파일 이름을 정의한다.
# 단, 해당 디렉토리의 AllowOverride 에서 None으로 설정되어 있지 않아야 된다.
# 자세한 설명은 "아파치 인증" 강좌 참고
CacheNegotiatedDocs
# 프록시 서버에 문서를 캐시하도록 설정한다. 기본적으로 주석 처리 되어 있다.
HostnameLookup Off
# 아파치의 로그 파일에는 기본적으로 클라이언트의 IP 주소 정보가 기록되는데 이 설정을 On 하면 호스트 네임(도메인)
# 이 기록된다. 하지만 DNS 질의를 해야 되므로 속도가 느리다는 단점이 있다.
# 그냥 Off로 사용하는것을 추천한다.
ErrorLog /usr/local/apache/logs/error_log
# 아파치 서버 접속 에러 로그를 기록할 결로와 파일 이름을 설정한다.
LogLevel warn
# 에러 로그 내용의 레벨을 설정한다.
LogFormat "%h %l %u %t "%r" %>s %b "%{Referer}i" "%{User-Agent}i"" combined
LogFormat "%h %l %u %t "%r" %>s %b" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent
# 사용자 접속을 기록할 로그 포멧을 정의한 부분이다. 위와 같이 4가지 형식의 로그 포멧이 기본적으로 설정되어 있다.
common : 가장 일반적인 로그 기록
referer : 현재 아파치 서버에 접속하기 전에 머물렀던 URL으 기록한다.
agent : 접속자의 웹 브라우저(OS 포함) 종류를 기록한다.
combined : 위의 3가지 로그 포멧을 모두 조합한 것이다.
접속자에 대한 많은 정보를 기록하길 원한다면 combined으로 설정하면 된다.
# %h %I 등과 같은 아파치 로그 포멧을 알고 싶으면 아파치 메뉴얼를 참고 하기 바란다.
CustomLog /usr/local/apache/logs/access_log common
# 로그 파일의 경로와 파일 이름, 그리고 로그의 포맷을 설정한다.
# common 이외에 위에서 정의한 로그 포멧을 지정할 수 있다.
ServerSignature On
# apache 서버가 생성하는 Error 페이지와 Ftp 디렉토리 목록, mod_status, mod_info 등에 apache 서버 버젼과 가상 호스트
# 네임을 추가적으로 표시해 준다.(On 설정시) Email 설정시 ServerAdmin의 E-mail 주소를 페이지에 링크해 준다.
# On, Off, Email을 설정해서 사용할 수 있다.
Alias /icons/ "/usr/local/apache/icons/"
# 특정 디렉토리를 alias 한다. 위의 경우는 /usr/local/apache/icons/ 디렉토리를 icons 라는 이름으로 alias 한것이다
# icons 디렉토리 앞의 /(슬래쉬)는 DocumentRoot를 의미한다.
ScriptAlias /cgi-bin/ "/usr/local/apache/cgi-bin/"
# Alias와 같은 형식이고 실행할 스크립트 디렉토리를 alias할 때 사용한다.
Redirect old-URL new-URL
# old-URL을 new-URL로 코딩해준다. 하지만 HTML태그로 위의 기능을 대신할 수 있기때문에 사용할 일이 거의 없을것이다.
IndexOptions Fancy Indexing
# 디렉토리에 DirectoryIndex에 설정된 파일명이 없을경우 아파치서버는 디렉토리목록을 보여주는데 Fancy Indexing을 설정
# 할 경우 파일의 크기, 생성날짜 등을 같이 출력해준다.
DefaultIcon /icons/unknown.gif
# 아이콘이 설정되어 있지 않은 파일 확장자들의 아이콘을 대신한다
AddDescription "GZIP compressed document" .gz
AddDescription "tar archive" .tar
AddDescription "GZIP compressed tar archive" .tgz
# 아파치가 디렉토리 목록을 보여줄 경우 파일 확장자에 대해 간략한 설명을 할 수 있게 한다. 단, IndexOptions에서
# FancyIndexing이 적용되어 있어야 된다.
ReadmeName README
HeaderName HEADER
# 아파치가 디렉토리가 목록을 보여줄 경우 페이지 위(HEADER)와 아래(README)에 추가로 출력할 텍스트들을 설정할 수 있다.
# 각 디렉토리에 README, HEADER 라는 이름으로 텍스트 파일을 만들면 된다.
ErrorDocument 500 "The server made a boo bo"
ErrorDocument 404 /missing.html
ErrorDocument 402 http://some.other_server.com/subscription_info.html
# 클라이언트의 요구에 의해 발생하는 아파치 서버의 에러페이지에 출력할 텍스트나 문서를 정의할 수 있다.
# 각 페이지는 에러 코드별로 설정할 수 있으며 외부의 URL을 지정할 수도 있다.
# 문자열을 설정을 경우네는 " "안에 문자열을 설정하면 되고 내부 html 문서를 지정해줄 경우에는 문서의 경로를 지정해
# 주면 된다. 단, (/)최상위 경로는 DocumentRoot를 의미한다.
<Location /server-status>
SetHandler server-status
Order deny,allow
Deny from all
Allow from .your_domain.com
</Location>
<Location /server-info>
SetHandler server-info
Order deny,allow
Deny from all
Allow from .your_domain.com
</Location>
# 위의 설정을 함으로써 웹 브라우저에서 아파치 서버의 상태와 정보를 볼수 있다. 보안상 특정 호스트에서만 볼 수 있게
# 설정할 수 있으며 기본적으로 주석 처리되어 있다.
<Location /cgi-bin/phf*>
Deny from all
ErrorDocument 403 http://phf.apache.org/phf_abuse_log.cgi
</Location>
# 아파치 1.1 이전 버젼의 버그를 악용하는 경우가 있는데 이 설정에 해 두면 이러한 공격을 phf.apache.org의 로깅 스키립
# 트로 리다이렉트 시켜준다. 요즘은 필요없는 설정이고 위의 URL에 cgi스크립트가 존재하지도 않는다.
DefaultType text/plain
# 아파치가 처리할 기본 문서들을 정의한다. 위의 설정은 html과 text 파일을 포함시킨 것이다.
# 위의 설정 때문에 text 파일도 웹 브라우저에 표시해 줄수 있는 것이다.
출처 : http://flashcafe.org
OS/리눅스 & 유닉스 2012. 3. 20. 09:23
리눅스에서 현재 시간의 동시접속자수를 알아내는 방법은 여러가지 방법이 있는것 같습니다. 하지만 많은 분들이 netstat 명령을 사용하여 동시접속자수를 알아내시는것 같은데요, 제가 사용하는 방식을 기억용으로 정리해 두도록 하겠습니다.현재 접속 커넥션 수 알아내기이 명령을 실제로 연결되어있는 커넥션 수를 알아내기에 적합합니다. 서버상에서 실제로 처리해야 하는 수를 의미합니다.netstat -an | grep :80.*ESTABLISHED | wc -l 현재 접속 사용자(머신/디바이스) 수 알아내기이 명령은 현재 동시 접속중인 사용자수를 알아내기에 적합합니다. 하나의 사용자가 동시에 여러개의 커넥션을 사용할 수 있는데 이것을 하나로 처리를 합니다.netstat -an | grep :80.*ESTABLISHED | awk '{print $5}' | awk -F: '{print $1}' | sort | uniq | wc -l
출처 - http://theeye.pe.kr/491
OS/리눅스 & 유닉스 2012. 3. 16. 19:37
|


![[-]](http://wiki.kldp.org/imgs/plugin/arrup.png "[-]")