|
|
OS/리눅스 & 유닉스 2012. 5. 18. 18:05
추가할 내용nm을 이용하면 라이브러리에 포함된 오브젝트와 함수명까지 확인할 수 있습니다. # nm libproc.a
alloc.o:
nm: alloc.o: no symbols
compare.o:
nm: compare.o: no symbols
devname.o:
nm: devname.o: no symbols
ksym.o:
nm: ksym.o: no symbols
이 문서는 library 의 사용방법에 대한 내용을 담고 있다. 왜 라이브러리가 필요한지, 라이브러리는 어떤 종류가 있으며, 어떻게 작성할수 있는지, 그리고 어떻게 사용하는지에 대해서 얘기하도록 할것이다. 그리고 중간중간에 이해를 돕기 위한 실제 코딩역시 들어갈 것이다. 라이브러리에 대한 이러저러한 세부적인 내용까지 다루진 않을것이다. 좀더 이론적인 내용을 필요로 한다면 Program Library HOWTO 를 참고하기 바란다. 이 문서에서는 라이브러리를 만들고 활용하는 면에 중점을 둘것이다. 그러므로 위의 문서는 이문서를 읽기전에 대충이라도 한번 읽어보도록 한다. 정적 라이브러리와 공유라이브러리는 일반적인 내용임으로 간단한 설명과 일반적인 예제를 드는 정도로 넘어갈 것이다. 그러나 동적라이브러리에 대해서는 몇가지 다루어야할 이슈들이 있음으로 다른 것들에 비해서 좀더 비중있게 다루게 될것이다.
라이브러리란 특정한 코드(함수 혹은 클래스)를 포함하고 있는 컴파일된 파일이다. 이러한 라이브러리를 만드는 이유는 자주 사용되는 특정한 기능을 main 함수에서 분리시켜 놓음으로써, 프로그램을 유지, 디버깅을 쉽게하고 컴파일 시간을 좀더 빠르게 할수 있기 때문이다. 만약 라이브러리를 만들지 않고 모든 함수를 main 에 집어 넣는다면, 수정할때 마다 main 코드를 수정해야 하고 다시 컴파일 해야 할것이다. 당연히 수정하기도 어렵고 컴파일에도 많은 시간이 걸린다. 반면 라이브러리화 해두면 우리는 해당 라이브러리만 다시 컴파일 시켜서 main 함수와 링크 시켜주면 된다. 시간도 아낄뿐더러 수정하기도 매우 쉽다.
라이브러리에도 그 쓰임새에 따라서 여러가지 종류가 있다(크게 3가지). 가장 흔하게 쓰일수 있는 "정적라이브러리"와 "공유라이브러리", "동적라이브러리" 가 있다. 이들 라이브러리가 서로 구분되어지는 특징은 적재 시간이 될것이다. - 정적라이브러리
정적라이브러리는 object file(.o로 끝나는) 의 단순한 모음이다. 정적라이브러린느 보통 .a 의 확장자를 가진다. 간단히 사용할수 있다. 컴파일시 적재되므로 유연성이 떨어진다. 최근에는 정적라이브러리는 지양되고 있는 추세이다. 컴파일시 적재되므로 아무래도 바이너리크기가 약간 커지는 문제가 있을것이다. - 공유라이브러리
공유라이브러리는 프로그램이 시작될때 적재된다. 만약 하나의 프로그램이 실행되어서 공유라이브러리를 사용했다면, 그뒤에 공유라이브러리를 사용하는 모든 프로그램은 자동적으로 만들어져 있는 공유라이브러리를 사용하게 된다. 그럼으로써 우리는 좀더 유연한 프로그램을 만들수 잇게 된다. 정적라이브러리와 달리 라이브러리가 컴파일시 적재되지 않으므로 프로그램의 사이즈 자체는 작아지지만 이론상으로 봤을때, 라이브러리를 적재하는 시간이 필요할것이므로 정적라이브러리를 사용한 프로그램보다는 1-5% 정도 느려질수 있다. 하지만 보통은 이러한 느림을 느낄수는 없을것이다. - 동적라이브러리
공유라이브러리가 프로그램이 시작될때 적재되는 반면 이것은 프로그램시작중 특정한때에 적재되는 라이브러리이다. 플러그인 모듈등을 구현할때 적합하다. 설정파일등에 읽어들인 라이브러리를 등록시키고 원하는 라이브러리를 실행시키게 하는등의 매우 유연하게 작동하는 프로그램을 만들고자 할때 유용하다.
예전에 libz 라는 라이브러리에 보안 문제가 생겨서 한창 시끄러웠던적이 있다. libz 라이브러리는 각종 서버프로그램에 매우 널리 사용되는 라이브러리였는데, 실제 문제가 되었던 이유는 많은 libz 를 사용하는 프로그램들이 "정적라이브러리" 형식으로 라이브러리를 사용했기 때문에,버그픽스(bug fix)를 위해서는 문제가 되는 libz 를 사용하는 프로그램들을 다시 컴파일 시켜야 했기 때문이다. 한마디로 버그픽스 자체가 어려웠던게 큰 문제였었다. 도대체 이 프로그램들이 libz 를 사용하고 있는지 그렇지 않은지를 완전하게 알기도 힘들뿐더러, 언제 그많은 프로그램을 다시 컴파일 한단 말인가. 만약 libz 를 정적으로 사용하지 않고 "공유라이브러리" 형태로 사용한다면 bug fix 가 훨씬 쉬웠을것이다. 왜냐면 libz 공유라이브러리는 하나만 있을 것이므로 이것만 업그레이드 시켜주면 되기 때문이다. 아뭏든 이렇게 유연성이 지나치게 떨어진다는 측면이 정적라이브러리를 사용하지 않는 가장 큰 이유가 될것이다. 프로그램들의 덩치가 커지는 문제는 유연성 문제에 비하면 그리큰문제가 되지는 않을것이다.
이번장에서는 실제로 라이브러리를 만들고 사용하는 방법에 대해서 각 라이브러리 종류별로 알아볼 것이다.
라이브러리의 이름은 libmysum 이 될것이며, 여기에는 2개의 함수가 들어갈 것이다. 하나는 덧셈을 할 함수로 "ysum" 또 하나는 뺄셈을 위한 함수로 "ydiff" 으로 할것이다. 이 라이브러리를 만들기 위해서 mysum.h 와 mysum.c 2개의 파일이 만들어질것이다. mysum.h int ysum(int a, int b);
int ydiff(int a, int b);
|
mysun.c #include "mysum.h"
int ysum(int a, int b)
{
return a + b;
}
int ydiff(int a, int b)
{
return a - b;
}
|
정적라이브러리는 위에서 말했듯이 단순히 오브젝트(.o)들의 모임이다. 오브젝트를 만든다음에 ar 이라는 명령을 이용해서 라이브러리 아카이브를 만들면 된다. [root@localhost test]# gcc -c mysum.c
[root@localhost test]# ar rc libmysum.a mysum.o
|
아주아주 간단하다. 단지 ar 에 몇가지 옵션만을 이용해서 libmysum 이란 라이 브러리를 만들었다. 'r' 은 libmysum.a 라는 라이브러리 아카이브에 새로운 오브젝트를 추가할것이라는 옵션이다. 'c' 는 아카이브가 존재하지 않을경우 생성하라는 옵션이다. 이제 라이브러리가 실제로 사용가능한지 테스트해보도록 하자. 예제 : print_sum.c #include "mysum.h"
#include <stdio.h>
#include <string.h>
int main()
{
char oper[5];
char left[11];
char right[11];
int result;
memset(left, 0x00, 11);
memset(right, 0x00, 11);
// 표준입력(키보드)으로 부터 문자를 입력받는다.
// 100+20, 100-20 과 같이 연산자와 피연산자 사이에 공백을 두지 않아야 한다.
fscanf(stdin, "%[0-9]%[^0-9]%[0-9]", left, oper, right);
if (oper[0] == '-')
{
printf("%s %s %s = %d\n", left, oper, right,
ydiff(atoi(left), atoi(right)));
}
if (oper[0] == '+')
{
printf("%s %s %s = %d\n", left, oper, right,
ysum(atoi(left), atoi(right)));
}
}
|
위의 프로그램을 컴파일 하기 위해서는 라이브러리의 위치와 어떤 라이브러리를 사용할것인지를 알려줘야 한다. 라이브러리의 위치는 '-L' 옵션을 이용해서 알려줄수 있으며, '-l' 옵션을 이용해서 어떤 라이브러리를 사용할것인지를 알려줄수 있다. -l 뒤에 사용될 라이브러리 이름은 라이브러리의 이름에서 "lib"와 확장자 "a"를 제외한 나머지 이름이다. 즉 libmysum.a 를 사용할 것이라면 "-lmysum" 이 될것이다. [root@localhost test]# gcc -o print_sum print_num.c -L./ -lmysum
|
만약 우리가 사용할 라이브러리가 표준 라이브러리 디렉토리경로에 있다면 -L 을 사용하지 않아도 된다. 표준라이브러리 디렉토리 경로는 /etc/ld.so.conf 에 명시되어 있다. 정적라이브러리 상태로 컴파일한 프로그램의 경우 컴파일시에 라이브러리가 포함되므로 라이브러리를 함께 배포할 필요는 없다.
print_sum.c 가 컴파일되기 위해서 사용할 라이브러리 형태가 정적라이브러리에서 공유라이브러리로 바뀌였다고 해서 print_sum.c 의 코드가 변경되는건 아니다. 컴파일 방법역시 동일하며 단지 라이브러리 제작방법에 있어서만 차이가 날뿐이다. 이제 위의 mysum.c 를 공유라이브러리 형태로 만들어보자. 공유라이브러리는 보통 .so 의 확장자를 가진다. [root@localhost test]# gcc -fPIC -c mysum.c
[root@localhost test]# gcc -shared -W1,-soname,libmysutff.so.1 -o libmysum.so.1.0.1 mysum.o
[root@localhost test]# cp libmysum.so.1.0.1 /usr/local/lib
[root@localhost test]# ln -s /usr/local/lib/libmysum.so.1.0.1 /usr/local/lib/libmysum.so
|
우선 mysum.c 를 -fPIC 옵션을 주어서 오브젝트 파일을 만들고, 다시 gcc 를 이용해서 공유라이브러리를 제작한다. 만들어진 라이브러리를 적당한 위치로 옮기고 나서 ln 을 이용해서 컴파일러에서 인식할수 있는 이름으로 심볼릭 링크를 걸어준다. 컴파일 방법은 정적라이브러리를 이용한 코드의 컴파일 방법과 동일하다. [root@coco test]# gcc -o print_sum print_sum.c -L/usr/local/lib -lmysum
|
공유라이브러리는 실행시에 라이브러리를 적재함으로 프로그램을 배포할때는 공유라이브러리도 함께 배포되어야 한다. 그렇지 않을경우 다음과 같이 공유라이브러리를 찾을수 없다는 메시지를 출력하면서 프로그램 실행이 중단될 것이다. [root@coco library]# ./print_sum
./print_sum: error while loading shared libraries: libmysub.so: cannot open shared object file: No such file or directory
|
위와 같은 오류메시지를 발견했다면 libmysub.so 가 시스템에 존재하는지 확인해 보자. 만약 존재하는데도 위와 같은 오류가 발생한다면 이는 LD_LIBRARY_PATH 나 /etc/ld.so.conf 에 라이브러리 패스가 지정되어 있지 않을 경우이다. 이럴때는 LD_LIBRARY_PATH 환경변수에 libmysub.so 가 있는 디렉토리를 명시해주거나, /etc/ld.so.conf 에 디렉토리를 추가시켜주면 된다. 만약 libmysub.so 가 /usr/my/lib 에 복사되어 있고 환경변수를 통해서 라이브러리의 위치를 알려주고자 할때는 아래와 같이 하면된다. [root@localhost test]# export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/my/lib
|
그렇지 않고 ld.so.conf 파일을 변경하길 원한다면(이럴경우 관리자 권한을 가지고 있어야 할것이다) ld.so.conf 에 라이브러리 디렉토리를 추가하고 ldconfig 를 한번 실행시켜주면 된다. [root@localhost test]# cat /usr/my/lib >> /etc/ld.so.conf
[root@localhost test]# ldconfig
|
ldconfig 를 실행시키게 되면 /etc/ld.so.conf 의 파일을 참조하여서 /etc/ld.so.cache 파일이 만들어지고, 프로그램은 ld.so.cache 의 디렉토리 경로에서 해당 라이브러리가 있는지 찾게 된다.
동적라이브러리라고 해서 동적라이브러리를 만들기 위한 어떤 특별한 방법이 있는것은 아니다. 일반 공유라이브러리를 그대로 쓰며, 단지 실행시간에 동적라이브러리를 호출하기 위한 방법상의 차이만 존재할 뿐이다. 정적/공유 라이브러리가 라이브러리의 생성방법과 컴파일방법에 약간의 차이만 있고 코드는 동일하게 사용되었던것과는 달리 동적라이브러리는 코드자체에 차이가 있다. 그럴수밖에 없는게, 동적라이브러리는 프로그램이 샐행되는 중에 특정한 시점에서 부르고 싶을때 라이브러리를 적재해야 하므로, 라이브러리를 적재하고, 사용하고 해제(free) 하기 위한 코드를 생성해야 하기 때문이다. linux 에서는 이러한 라이브러리를 호출하기 위한 아래와 같은 함수들을 제공한다. 아래의 함수들은 solaris 에서 동일하게 사용될수 있다. #include <dlfcn.h>
void *dlopen (const char *filename, int flag);
const char *dlerror(void);
void *dlsym(void *handle, char *symbol);
int dlclose(void *handle);
|
dlopen 은 동적라이브러리를 적재하기 위해서 사용된다. 첫번째 아규먼트인 filename 은 /usr/my/lib/libmysum.so 와 같이 적재하기 원하는 라이브러리의 이름이다. 만약 적재시킬 라이브러리의 이름이 절대경로로 지정되어 있지 않을경우에는 LD_LIBRARY_PATH 에 등록된 디렉토리에서 찾고, 여기에서도 찾지 못할경우 /etc/ld.so.cache 에 등록된 디렉토리 리스트에서 찾게 된다. dlopen(3) 이 성공적으로 호출되면 해당 라이브러리에 대한 handle 값을 넘겨 준다. flag 는 RTLD_LAZY와 RTLD_NOW 중 하나를 정의할수 있다. RTLD_LAZY는 라이브러리의 코드가 실행시간에 정의되지 않은 심볼을 해결하며, RTLD_NOW 는 dlopen 의 실행이 끝나기전에(return 전에) 라이브러리에 정의되지 않은 심볼을 해결한다. dlerror 는 dl 관련함수들이 제대로 작동을 수행하지 않았을경우 에러메시지를 되돌려준다. dleooro(), dlsym(), dlclose(), dlopen(3)중 마지막 호출된 함수의 에러메시지를 되돌려준다. dlsym 은 dlopen(3) 을 통해서 열린라이브러리를 사용할수 있도록 심볼값을 찾아준다. 심볼이라고 하면 좀 애매한데, 심볼값은 즉 열린라이브러리에서 여러분이 실제로 호출할 함수의이름이라고 생각하면 된다. handle 는 dlopen(3) 에 의해서 반환된 값이다. symbol 은 열린라이브러리에서 여러분이 실제로 부르게될 함수의 이름이다. dlsym 의 리턴값은 dlopen 으로 열린 라이브러리의 호출함수를 가르키게 된다. 리턴값을 보면 void * 형으로 되어 있는데, void 형을 사용하지 말고 호출함수가 리턴하는 형을 직접명시하도록 하자. 이렇게 함으로써 나중에 프로그램을 유지보수가 좀더 수월해진다.
동적라이브러리는 실행시간에 필요한 라이브러리를 호출할수 있음으로 조금만(사실은 아주 많이겠지만 T.T) 신경쓴다면 매우 확장성높고 유연한 프로그램을 만들수 있다. 동적라이브러리의 가장 대표적인 예가 아마도 Plug-in 이 아닐까 싶다. 만약에 모질라 브라우저가 plug-in 을 지원하지 않는 다면 우리는 새로운 기능들 이 추가될때 마다 브라우저를 다시 코딩하고 컴파일하는 수고를 해야할것이다. 그러나 동적라이브러리를 사용하면 브라우저를 다시 코딩하고 컴파일 할필요 없이, 해당 기능을 지원하는 라이브러리 파일만 받아서 특정 디렉토리에 설치하기만 하면 될것이다. 물론 동적라이브러리를 사용하기만 한다고 해서 이러한 기능이 바로 구현되는 건 아니다. Plug-in 의 효율적인 구성을 위한 표준화된 API를 제공하고 여기에 맞게 Plug-in 용 라이브러리를 제작해야만 할것이다. 우리가 지금까지 얘로든 프로그램을 보면 현재 '+', '-' 연산을 지원하고 있는데, 만약 'x', '/' 연산을 지원하는 라이브러리가 만들어졌다면, 우리는 프로그램의 코딩을 다시해야만 할것이다. 이번에는 동적라이브러리를 이용해서 plug-in 방식의 확장이 가능하도록 프로그램을 다시 만들어 보도록 할것이다.
동적라이브러리를 이용해서 main 프로그램의 재코딩 없이 추가되는 새로운 기능을 추가시키기 위해서는 통일된 인터페이스를 지니는 특정한 형식을 가지도록 라이브러리가 작성되어야 하며, 설정파일을 통하여서 어떤 라이브러리가 불리어져야 하는지에 대한 정보를 읽어들일수 있어야 한다. 그래서 어떤 기능을 추가시키고자 한다면 특정 형식에 맞도록 라이브러리를 제작하고, 설정파일을 변경하는 정도로 만들어진 새로운 라이브러리의 기능을 이용할수 있어야 한다. 설정파일은 다음과 같은 형식으로 만들어진다. 설정파일의 이름은 plugin.cfg 라고 정했다. +,ysum,libmysum.so
-,ydiff,libmysum.so
|
'-' 연산에대해서는 libmysum.so 라이브러리를 호출하며, ydiff 함수를 사용한다. '=' 연산에 대해서는 libmysum.so 라이브러리를 호출하고 ysum 함수를 사용한다는 뜻이다. 설정파일의 이름은 plugin.cfg 로 하기로 하겠다. 다음은 동적라이브러리로 만들어진 print_sum 의 새로운 버젼이다. 예제 : print_sum_dl.c #include <stdlib.h>
#include <stdio.h>
#include <dlfcn.h>
#include <string.h>
struct input_data
{
char oper[2];
char func[10];
char lib[30];
};
int main(int argc, char **argv)
{
char oper[2];
char left[11];
char right[11];
char buf[50];
char null[1];
int data_num;
struct input_data plug_num[10];
void *handle;
int (*result)(int, int);
int i;
char *error;
FILE *fp;
// 설정파일을 읽어들이고
// 내용을 구조체에 저장한다.
fp = fopen("plugin.cfg", "r");
data_num = 0;
while(fgets(buf, 50, fp) != NULL)
{
buf[strlen(buf) -1] = '\0';
sscanf(buf, "%[^,]%[,]%[^,]%[,]%[^,]", plug_num[data_num].oper,
null,
plug_num[data_num].func,
null,
plug_num[data_num].lib);
data_num ++;
}
fclose(fp);
printf("> ");
memset(left, 0x00, 11);
memset(right, 0x00, 11);
fscanf(stdin, "%[0-9]%[^0-9]%[0-9]", left, oper, right);
// 연산자를 비교해서
// 적당한 라이브러리를 불러온다.
for (i = 0; i < data_num ; i++)
{
int state;
if ((state = strcmp(plug_num[i].oper, oper)) == 0)
{
printf("my operator is : %s\n", plug_num[i].oper);
printf("my call function is : %s\n", plug_num[i].func);
break;
}
}
if (i == data_num)
{
printf("--> unknown operator\n");
exit(0);
}
handle = dlopen(plug_num[i].lib, RTLD_NOW);
if (!handle)
{
printf("open error\n");
fputs(dlerror(), stderr);
exit(1);
}
// 연산자에 적당한 함수를 불러온다.
result = dlsym(handle, plug_num[i].func);
if ((error = dlerror()) != NULL)
{
fputs(error, stderr);
exit(1);
}
printf("%s %s %s = %d\n",left, oper, right, result(atoi(left), atoi(right)) );
dlclose(handle);
}
|
위의 예제 프로그램은 다음과 같이 컴파일되어야 한다. 라이브러리 파일의 위치는 /usr/my/lib 아래에 있는것으로 하며, 라이브러리 찾기 경로에 등록되어 있다고 가정하겠다. [root@localhost test]# gcc -o print_sum_dl print_sum_dl.c -ldl
|
이 프로그램을 실행하면 사용자의 입력을 기다리는 "> "가 뜨게 되고, 여기에 계산하기 원하는 값을 입력하면 된다. 현재는 '+'와 '-' 연산만을 지원하며, 연산자와 피연산자들 간에 간격이 없어야 한다. 다음은 실행결과 화면이다.
[root@localhost test]# ./print_sum_dl
> 99+99
my operator is : +
my call function is : ysum
99 + 99 = 198
[root@localhost test]#
|
사용자가 프로그램을 실행하면 프로그램은 사용자의 입력을 받아들이고 sscanf 를 이용해서 연산자와 피연산자를 구분하게 된다. 그리고 피연산자를 값으로 하여, 설정파일에 설정된 라이브러리를 불러들이고(dlopen) 해당 함수를 가져와서(dlsym) 실행시키게 된다. 자 이렇게 해서 우리는 '+', '-' 연산이 가능한 프로그램을 하나 만들게 되었다. 그런데 A 라는 개발자가 '*','/' 연산도 있으면 좋겠다고 생각해서 아래와 같은 코드를 가지는 '*', '/' 연산을 위한 라이브러리를 제작하였다. 예제 : mymulti.h int multi(int a, int b);
int div(int a, int b);
|
예제 : mymulti.cint multi(int a, int b)
{
return a * b;
}
int div(int a, int b)
{
return a / b;
}
|
A 라는 개발자는 이것을 다음과 같이 공유라이브러리 형태로 만들어서 간단한 라이브러리의 설명과 함께 email 로 전송했다. [root@localhost test]# gcc -c -fPIC mymulti.c
[root@localhost test]# gcc -shared -W1,-soname,libmymulti.so.1 -o libmymulti.so.1.0.1 mymulti.o
|
라이브러리를 받았으므로 새로운 라이브러리가 제대로 작동을 하는지 확인을 해보도록 하자. 우선 libmymulti.so.1.0.1 을 /usr/my/lib 로 복사하도록 하자. 그다음 설정파일에 다음과 같은 내용을 가지도록 변경 시키도록 하자.
+,ysum,libmystuff.so
-,ydiff,libmystuff.so
*,ymulti,libmymulti.so.1.0.1
/,ydiv,libmymulti.so.1.0.1
|
이제 print_sum_dl 을 실행시켜보자. [root@localhost test]# ./print_sum_dl
> 10*10
my operator is : *
my call function is : ymulti
10 * 10 = 100
[root@localhost test]# ./print_sum_dl
> 10/10
my operator is : /
my call function is : ydiv
10 / 10 = 1
|
print_sum_dl.c 의 원본파일의 아무런 수정없이 단지 설정파일만 변경시켜 줌으로써 기존의 print_sum_dl 에 "곱하기"와 "나누기"의 새로운 기능이 추가 되었다. 위에서도 말했듯이 이러한 Plug-in 비슷한 기능을 구현하기 위해서는 통일된 함수 API가 제공될수 있어야 한다.
여기에 있는 내용중 동적라이브러리에 대한 내용은 솔라리스와 리눅스에서만 동일하게 사용할수 있다. Hp-Ux 혹은 윈도우에서는 사용가능하지 않는 방법이다. 이에 대한 몇가지 해법이 존재하는데, 이 내용은 나중에 시간이 되면 다루도록 하겠다. 어쨋든 솔라리스와 리눅스 상에서 코딩되고 윈도우 혹은 다른 유닉스로 포팅될 프로그램이 아니라면 위의 방법을 사용하는데 있어서 문제가 없을것이다.
OS/리눅스 & 유닉스 2012. 5. 18. 18:04
1. 소개 : 프로그램을 제작하는 과정 근래의 프로그램 제작 과정은 오랜 시간동안 고통받으면서 쌓아올려진 프로그래머들과 디자이너들의 노력의 산물이다. 이러한 프로그램 제작 과정은 다음과 같은 순서를 따른다. 우선 텍스트 편집기로 고급 언어를 사용한 소스 코드를 만든다. 매우 큰 프로그램 같은 경우는 하나의 파일에 담기 매우 힘들기 때문에 소스 코드 자체가 기능적 모듈별로 그 기능을 수행하는데 적합한 프로그래밍 언어가 다를 수 있기 때문에 앞에서 나뉘어진 소스 코드들이 다 같은 프로그래밍 언어를 사용해야 하는 것은 아니다. 소스 코드들을 생성한 후, 각각의 코드들은 기계(컴퓨터)에 의해 실행가능한 코드로 변환되어야 한다. 이렇게 기계에 의해 실행 가능한 코드를 목적 코드(object code)라고 한다. 이 코드는 기계에 의해 실행 가능하다는 것만 빼고는 앞에서의 소스코드와 똑같은 기능을 수행하게 된다. 소스코드를 목적 코드로 변환하는 과정을 일반적으로 컴파일(compile)이라고 부른다. 컴파일은 대개의 경우 앞에서 나눈 각각의 소스 파일들에 대해 따로따로 적용된다. 컴파일된 목적 코드들은 프로그램이나 서브 루틴, 변수 등 다음 단계에서 필요한 대부분의 요소들을 포함하고 있다. 프로그램을 생성하는데 필요한 목적 코드들이 생성된 후, 링커(linker)라고 불리우는 프로그램에 의해 앞에서 생성된 목적 코드들을 한데 묶고 연결하는 과정이 진행된다. 이 과정에서는 각각의 모듈(목적 코드)들에 포함되어 있는 다른 모듈을 가리키는 메모리 주소들이 결정되게 된다(예를 들어 한 모듈에서 다른 모듈에 들어있는 변수를 가리키게 되는 경우 링크 과정에서 각 모듈들을 합한 후 최종적으로 결정되는 절대 주소를 변수 부분에 넣어 주게 된다.) 이렇게 해서 생성되는 제품이 일반적으로 메모리에 로딩되고 실행되는 실행 파일이다. 프로그램 실행은 운영 체제에 포함된 특별한 소프트웨어에 의해 이루어지며 예를 들자면 리눅스의 시스템 콜exec()등이 있다. 이 시스템 콜은 실행 파일을 찾은 후, 프로세스에게 메모리를 할당하고, 파일의 특별한 부분(실행코드와 변수들)을 메모리에 적재하고 실행파일의 '텍스트'라는 부분에서 제어권을 CPU에게 넘긴다.
2. 프로그램 제작 과정의 간략한 역사 프로그램 제작 과정은 좀더 나은 실행 성능과 시스템 리소스 사용을 위해 지속적인 개혁을 해왔다. 초기에 개발자들은 직접적으로 기계어 코드를 이용하여 프로그램을 개발하였다. 이후에 프로그램을 고급 언어로 개발한 후 기계어로 번역하는 것이 자동화됨으로써 프로그램의 생산성은 비약적으로 증가하게 되었다. 프로그램 컴파일이 가능해진 후, 프로그램 제작 과정은 소스 파일들을 생성하고, 컴파일하고, 최종적으로 실행 파일을 실행하는 일련의 과정을 포함하게 되었다. 그러나 컴파일 과정에 CPU 시간을 포함한 상당히 많은 자원이 투자되고 컴파일을 통하여 생성된 많은 프로그램들이 계속 재 사용되는 부분을 포함하고 있다는 것을 차츰 깨닫게 되었다. 더욱이 누군가가 소스의 한 부분을 고치게 되면 그 소스 코드를 포함한 모든 소스코드를 다시 컴파일해야만 하는 불편함이 있다는 사실도 깨닫게 되었다. 위와 같은 이유 때문에 컴파일을 모듈별로 따로 하는 방식이 나오게 되었다. 이 방식은 메인 부분과 자주 재 사용되는 함수 부분을 따로 분리하여 재 사용되는 함수 부분을 특별한 장소에 미리 컴파일하여 놓아 두는 것이다. (후에 이를 라이브러리라고 부르게 된다.) 이로써 개발자는 재 사용되는 코드 부분을 다시 작성할 필요없이 위에 미리 컴파일된 목적 코드의 도움을 받으면서 프로그램을 제작할 수 있게 되었다. 그럼에도 불구하고, 이러한 과정 또한 프로그래머가 각각의 모듈들을 링크시킬 때 다 알고 있어야 한다는 점 때문에 복잡하기는 마찬가지였다.(또한 이러한 과정은 프로그래머가 알고 있는 함수만 쓸 수 있다는 제약점을 낳게 되었다.)
3. 라이브러리란 무엇인가? 위에서 이야기한 여러 가지 불편함 때문에 사람들은 라이브러리를 만들게 되었다. 라이브러리란 링커가 이해할 수 있는 파일 포맷을 가지며 개발자가 라이브러리를 지정하면 링커가 알아서 프로그램에 필요한 모듈만 링크 시켜 주는 특수한 파일 형태일 뿐이다. 일 라이브러리를 통해 개발자는 거대한 라이브러리에 있는 함수들의 어떠한 종속성에도 신경쓰지 않고 라이브러리 내의 모든 함수를 마음껏 사용할 수 있게 되었다. 우리가 지금까지 이야기한 라이브러리는 현재에도 별로 변화하지 않고 있다. 다만 라이브러리 파일의 포맷이 조금 바뀌었는데 새로 바뀐 포맷에서는 파일 맨 앞에 그 라이브러리에 대한 정보와 링커가 모든 라이브러리 파일을 풀지 않고도 라이브러리 내부의 함수들을 알 수 있게 해주는 식별자를 가지고 있다. 리눅스에서는 ranlib(1)이라는 명령어가 이러한 기능(라이브러리 파일에 심볼 테이블을 더하는 작업)을 수행해 준다. 위에서 설명한 라이브러리를 정적 라이브러리(Static Library)라고 한다. 최초로 멀티 태스킹 시스템이 소개된 후 라이브러리에도 '코드의 공유'라는 변화가 몰려오게 된다. 만약 같은 시스템에서 같은 코드를 가진 두 개의 프로그램이 동시에 실행된다면, 두 프로그램의 코드는 공유될 수 있다.(프로그램실행 시, 프로그램이 코드를 전혀 바꾸지 않기 때문에 가능한 것이다.) 이러한 아이디어는 복수개의 중복된 코드를 메모리에 로드할 필요를 없애 주었고 거대한 다중 사용자 시스템에서 많은 양의 메모리를 절약할 수 있게 되었다. 위의 개혁에서 한 발짝 앞으로 더 나아가, 많은 프로그램들이 같은 라이브러리를 사용한다는 사실을 생각해보자. 비록 각각의 프로그램들이 같은 라이브러리를 사용한다고 해도, 그들이 라이브러리에서 사용하는 코드의 양은 각기 다를 것이다. 더욱이 메인 코드는 서로 마다 다 다를 것이다. 더욱이 메인 코드는 서로 마다 다 다를 것이고 따라서 그들의 텍스트 또한 공유할 수 없을 것이다. 여기서 만약 하나의 라이브러리를 사용하는 각기 다른 프로그램들이 라이브러리 코드를 공유할 수 있다고 가정한다면 상당한 메모리를 절약할 수 있을 것이다. 자 그럼 서로 다른 프로그램 텍스트를 가지며 동일한 라이브러리를 공유하는 서로 다른 프로그램이 있다고 가정해 보자. 그러나 프로세스의 입장에서 보면 일은 조금 복잡해 진다. 실행 가능한 프로그램은 완전히 링크된 것이 아니라, 라이브러리의 식별자들의 주소 값을 가지는데 그것도 프로그램의 프로세스로의 적재 때문에 지연된다. 링커는 자신이 공유 라이브러리를 취급하고 있다고 인지하고 프로그램에 공유된 코드를 포함시키지 않는다. 커널의 경우 exec() 함수를 통해 프로그램을 실행시킬 때 자신이 공유 라이브러리를 로딩하기 위한 특별한 프로그램을 실행시킨다.(이 프로그램은 그 자신의 텍스트에 대한 공유 메모리를 할당하고 라이브러리의 변수들을 위한 개인 메모리를 할당하는 등의 작업을 한다.) 실행 파일을 로딩할 때 이 프로세스는 실행되고 모든 프로시져는 더더욱 복잡하다. 물론 링커가 일반적인 라이브러리를 만났을 때에는 원래대로 행동한다. 공유 라이브러리는 목적 코드를 포함한 파일들의 집합이라기보다는 목적 코드를 포함한 파일 그 자체라고 볼 수 있다. 공유 라이브러리를 링킹하는 동안에 링커는 어떤 모듈이 프로그램에 첨가되고, 어떤 모듈은 빠져야 되는가에 대한 정보를 라이브러리로부터 얻어내지 않는다. 링커는 단지 할당되지 않은 주소 값이 제대로 할당되도록 보장만 하고 라이브러리를 포함함으로써 어떠한 것이 반드시 리스트에 추가되어야 하는가를 검사한다. 모든 공유 라이브러리들의 묶음을 만들 수도 있지만 대개의 경우 공유 라이브러리는 여러 다양한 모듈이 링크된 결과이고 따라서 라이브러리는 추후 실행시간에 필요하기 때문에 라이브러리들을 한 묶음으로 만드는 일은 드물다. 아마도 공유 라이브러리라는 말 보다도 공유 객체라는 말이 더 어울릴 것이다.(그럼에도 불구하고 공유 객체라는 용어를 사용하지 않는다.)
4. 라이브러리의 형태 앞에서 미리 언급했지만, 리눅스에는 정적 라이브러리와 공유 라이브러리, 두 가지의 형태의 라이브러리가 존재한다. 정적 라이브러리들은 ar(1)이라는 유틸리티를 이용해 여러 모듈들을 하나의 파일에 모아놓고 ranlib(1) 이라는 유틸리티를 이용해 각 모듈들을 색인해 놓은 형태를 지니고 있다. 이러한 모듈들은 대개 파일의 이름이 .a로 끝나는 파일에 저장되어 있다. 링커는 파일의 이름이 .a로 끝나는 라이브러리를 만나게 되면 파일의 앞에 수록되어 있는 모듈들의 리스트를 뒤져서 라이브러리를 사용하는 프로그램 코드의 아직 정해지지 않은 주소 값들을 사용하는 모듈들의 주소 값으로 바꾸고 본 프로그램에 사용되는 모듈들을 더하게 된다. 반대로, 공유 라이브러리의 경우는 하나의 파일이라기 보다는 특수한 코드로 표시된 재 할당가능한 객체라고 볼 수 있다. 앞에서도 언급했듯이 링커 ld(1)는 프로그램 코드에 직접 모듈을 더하지 않고 라이브러리에서 제공하는 식별자를 골라서 프로그램 코드에 삽입하게 된다. 이대 모듈의 코드는 본 프로그램에 삽입되지 않으며 마치 본 프로그램에 이미 삽입되어 있는 척 하게 된다. 링커 ld(1)는 파일의 끝이 .so로 끝나는 것을 보면 공유 라이브러리로 인식한다.
5. 리눅스에서의 링크 작업 모든 프로그램은 실행시키기 위해 연결된 목적 모듈들로 이루어져 있다. 이렇게 모듈들을 연결하는 역할을 수행하는 프로그램을 리눅스 링커 ld(1) 이라고 한다. ld(1) 은 실행시 여러 가지 옵션을 제공하는데 본 기사에서는 편의를 위해 라이브러리 사용에 관한 옵션만을 다루도록 하겠다. ld(1) 은 사용자가 직접 실행시킬 수는 없으며 gcc(1) 와 같은 컴파일러가 컴파일의 마지막 단계에서 실행시키게 된다. ld(1)의 실행 방식을 이해함으로써 리눅스에서 라이브러리를 사용하는 방식을 좀 더 쉽게 이해할 수 있을 것이다. ld(1)은 그 자체의 적합한 수행 조건으로 프로그램에 링크될 오브젝트파일의 리스트를 필요로 한다. 우리가 앞에서 이야기한 조건(공유 라이브러리는 .so로 끝나고 정적 라이브러리는 .a로 끝난다.)을 따르기만 한다면 ld(1)은 어떠한 순서로라도 리스트에 있는 오브젝트파일들을 읽어들일 수 있다. 그러나 실제로 '어떠한 순서로라도' 라는 용어가 꼭 맞지는 않는다. ld(1)은 라이브러리를 포함하는 순간에 주소 값을 결정하는데 필요한 모듈만을 포함하기 때문에 뒤에 포함되는 모듈에 의해 결정되어야 할 주소 값은 그대로 결정이 되지 않은 상태로 남게 된다. 따라서 실제로 어떠한 순서로라도 모듈을 읽어 들일 수 있는 것은 아니다. 반면에 ld(1)은 옵션 -I 과 -L을 이용하여 표준 라이브러리를 포함할 수도 있다. 그러나 표준 라이브러리라고 해서 다른 것은 별로 없다. 단지 표준 라이브러리의 경우는 미리 정해진 장소에서 모듈을 찾는 다는 것만이 다를 뿐이다. 라이브러리는 기본적으로 /lib 이나 /usr/lib 디렉토리에 위치한다. -L 옵션은 사용자가 기본 디렉토리 이외에 다른 디렉토리를 기본 디렉토리(기본적으로 라이브러리를 찾는 디렉토리) 목록에 추가시켜 준다. 사용법은 다음과 같다. < -L 추가하고자 하는 디렉토리 이름 > 표준 라이브러리는 < -I 적재될 라이브러리의 이름 > 과 같은 방식으로 결정된다. 그러면 ld(1)은 순서대로 해당되는 디렉토리에서 libName.so 파일을 찾는다.(적재될 라이브러리의 이름이 libName 이라고 가정) 만약 찾지 못한다면 그 다음으로 libName.a를 찾게 된다. 만약 ld(1) 이 libName.so 파일을 찾게 되면, ld(1)은 지정된 라이브러리를 링크 시키게 된다. 그러나 libName.so는 찾지 못하고 libName.a를 찾았을 경우는 여기서 얻은 모듈로 주소 값을 결정하게 된다.
6. 공유 라이브러리의 동적 링킹과 로딩 동적 링킹은 실행 파일을 메모리에 적재하는 순간에 /lib/ld-linux.so 라는 특수한 모듈에 의해 수행된다.(사실 이 자체도 공유 라이브러리이다.) 실제로 동적 라이브러리와 링크하기 위해서 두 개의 모듈이 있다. /lib/ld.so(예전 a.out 형식의 실행포맷에서 사용한다.) 와 /lib/ld-linux.so(이것은 EFL 실행포맷에서 사용한다.)이다. 이러한 모듈들은 프로그램이 동적으로 링크될 시기에는 반드시 로딩되어 있어야 한다. 이것들의 이름은 표준적인 것이다. (그래서 이것들을 /lib 디렉토리에서 옮기면 안되고 이것들의 이름도 변경되면 안된다.) 만약 /lib/ld-linux.so 라는 이름을 변경한다면 이 공유 라이브러리는 사용하는 어떠한 프로그램도 자동적으로 실행이 멈추게 된다. 왜냐하면 이 모듈은 실행시에 아직 해석되지 않은 모든 참조 위치를 해석하는 일을 맡고 있기 때문이다. /lib/ld.so 모듈은 /etc/ld.so.cache 파일을 사용한다. 이 파일은 해당 라이브러리를 포함하는 대부분의 실행파일을 가리키고 있다. 이것에 대해서는 나중에 다시 말할 것이다.
7. soname, 공유 라이브러리의 버전, 호환성 이제부터 공유 라이브러리에 대한 이해하기 어려운 주제에 대해서 이야기하려고 한다. 버전이 바로 그것이다. 이 기사를 읽은 분들은 종종 'library libX11.so.3 not found' 라는 에러메세지를 발견하곤 했을 것이다. 그러나 현재 자신의 라이브러리 버전을 libX.so.6 인 것을 보고 매우 당혹했을 것이고 이러한 에러 메시지에 대해서 어떻게 처리해야 할지 난감해 하는 경우가 있을 것이다. 어째서 ld.so(8)이 libpepe.so.45.0.1과 libpepe.so.45.22.3 은 서로 교환할 수 있는 버전으로 이해하지만 libpepe.so.46.22.3 은 그렇지 못하다고 인식하는 것일까? 리눅스에서(물론 다른 모든 ELF 형식을 가지는 운영체제에서도 마찬가지이지만) 라이브러리들은 이것들을 구별하는데 연속된 문자를 사용한다. 이것이 soname 이다. soname은 라이브러리 내부에 포함되어 있고 연속된 문자들은 라이브러리들을 구성하는 대상이 링크될 때 결정된다. 공유 라이브러리가 만들어질 때 우리는 ld(1) 에 -soname 옵션을 넘겨주어야 한다. 물론 -soname 다음에는 이 문자열을 값으로 주어야 한다. 동적 로더는 어떠한 실행파일이 실행될 때 로드 되어지고 인식되어야 하는 공유 라이브러리를 인식하기 위해서 이 문자열을 사용한다. 이 과정은 다음과 같다. 먼저 ld-linux.so 는 프로그램이 어떠한 라이브러리가 필요하고 해당 soname 이 뭔지 결정한다. 그런 다음 해당 이름을 가지고 /etc/ld.so.cache에서 그 라이브러리를 포함하고 있는 파일의 이름을 얻어온다. 그리고 라이브러리 안에 존재하는 이름과 요청된 soname을 비교한다. 만약 서로 동일하다면 그것으로 끝이다. 그러나 만약 그렇지 않다면 발견될 때까지 검색을 하고 그래도 발견되지 않는다면 에러를 낸다. 만약 라이브러리가 로드되기에 적절한 것이라면 soname을 발견할 수 있을 것이다. 왜냐하면 ld-linux.so는 요청되어진 soname이 요구되어질 파일과 일치한다고 확신하기 때문이다. 만약 일치하지 않는 경우라면 보통 눈에 익은 'library libXXX.so.Y not found'가 나타날 것이다. 찾아야 하는 것이 soname이고 해당 soname을 참조할 때 주어지는 에러메세지인 것이다. 여기에서 우리는 라이브러리 이름이 변경되거나 지속성에 문제가 발생할 대에는 혼돈을 일으킬 소지를 가지고 있다. 그러나 Linux 사회에는 soname을 할당하는데 관례가 있기 때문에 soname을 접근하거나 soname을 변경하는 것을 좋은 생각이 아니다. 관례상 라이브러리의 soname은 반드시 적절한 라이브러리와 동일해야 하고 그러한 라이브러리에 대한 인터페이스여야 한다. 만약 라이브러리가 변경되어진다면 그것은 단지 내부적으로 일어나는 변화에 그쳐야 하지 전체적인 인터페이스에 영향을 미쳐서는 안되는 것이다. 즉 그 라이브러리에 대한 함수나 변수 그리고 함수에 대한 인자의 수 등에 영향을 안된다는 것이다. 이럴 경우에 구버전과 신버전 사이에 상호교환적이 되어야 한다. 즉 전체적으로는 변함이 없고 변경된 것은 적은 부분에서 이루어짐으로써 서로간에 교환 즉 호환성이 보장된다는 것이다. 적은 부분의 변화로 minor 숫자의 변경이 이루어지는 경우가 많다. 즉 이것은 soname 자체적으로는 변화가 없다는 것이다. 그리고 해당 라이브러리는 어떠한 중대한 문제없이 교체할 수 있게 되는 것이다. 그러나 함수를 더하거나 제거하거나 하는 경우 등과 같은 인터페이스가 변경되는 경우에는 상호 교환이 불가능하다는 것을 쉽게 짐작할 수 있을 것이다. 예를 들면 libX11.so.3 과 libX11.so.6 사이를 보면 알 수 있다. X11R5 에서 X11R6 로 업그레이드 되면서 새로운 많은 함수들이 정의되어졌고 인터페이스에도 변경이 가해졌는데 이것들 사이에 상호교환이라는 것은 큰 문제를 유발할 수 있게 될 것이다. X11R6-v3.1.2에서 X11R6-v3.1.3과 같은 변화는 인터페이스에는 변화가 없고 그 라이브러리도 같은 soname을 가지고 있다. 이 경우도 구 버전을 유지하기 위해서는 다른 이름을 주어야 하는 것은 당연하다.(이러한 이유로 라이브러리의 이름에 soname 에 보여지는 주어진 번호가 있고 그 외에 전체적인 버전 숫자가 나타나는 것이다.)
8. ldconfig(8) /etc/ld.so.cache 라는 파일을 언급한 것이 있는데 이것은 라이브러리가 어떠한 파일에 포함되어져 있는지에 대한 정보를 가지고 있는 것이다. 이것은 표율성을 위해서 바이너리 파일로 만들어지고 ldconfig(8) 유틸리티에 의해서 만들어진다. ldconfig(8)은 /etc/ld.so.conf에 지정된 디렉토리를 찾아다니면서 발견된 각각의 동적 라이브러리들에 대해서 그 라이브러리의 soname 에 의해서 불리어지는 심볼릭 링크들을 만들어낸다. ld.so가 파일의 이름을 얻으려고 할 때 이것은 soname을 발견한 파일의 디렉토리를 선택하는 그러한 일을 한다. 그리고 이렇게 함으로서 우리가 라이브러리를 추가할 때마다 ldconfig(8)를 수행할 필요는 없게 되는 것이다. ldconfig는 리스트에 새로운 디렉토리를 만들어 널때만 실행시키면 된다.
9. 동적 라이브러리 만들기 동적 라이브러리를 만들기 전에 고려할 사항이 있다. 그것은 바로 이렇게 동적 라이브러리로 만들었을 때 유용한가 하는 것이다. 동적 라이브러리는 여러 가지 이유로 시스템에 부하를 주게 된다. 프로그램의 로딩중에는 여러 가지 단계가 있다. 첫째는 메인 프로그램을 로딩하는 것이고 그 외에 프로그램에서 사용하는 각 동적 라이브러리를 로딩한다. 동적 라이브러리는 재할당이 가능한 코드로 만들어져야 한다. 이것은 당연한 것으로 프로세스를 위해서 가상 주소 공간 안에 할당된 주소가 해당 프로그램이 로드될 때까지 알 수 없기 때문이다. 컴파일러는 라이브러리의 로딩위치를 유지하기 위해서 레지스터를 예약해 놓아야 한다. 그리고 결과적으로 코드 최적화에서 이것 때문에 레지스터 하나를 사용할 수 없게 된다. 이러한 경우는 사소하다고 볼 수 있다. 왜냐하면 이러한 것 때문에 나타나는 시스템의 부하는 대부분의 경우 다른 부하들의 5%이하이기 때문이다. 동적 라이브러리가 적절한 것이 되려면 다른 여러 프로그램에서 자주 사용되어야 한다. 즉 이렇게 하면 시작한 프로세스가 없어진 이후에도 그 라이브러리에 대한 TEXT가 다시 로딩되는 것을 방지할 수 있다. 다시 로딩이 안되는 이유는 해당 라이브러리는 다른 프로그램에서 사용하고 있기 때문에 메모리에서 없애 버리면 안되기 때문에 항상 메모리가 남아있어서 다시 불러들일 필요가 없어진다. 동적 라이브러리의 좋은 예는 C 표준 라이브러리이다. (이 라이브러리들은 대부분의 C 프로그램을 작성하는데 사용 되어진다.)평균적으로 모든 함수들이 자주 사용되어진다. 정적 라이브러리의 경우에 좀처럼 드물게 사용하는 함수를 포함할 때 유리하다. 즉 해당 함수는 이것을 포함하고 있는 모듈에 있기 때문에 내가 필요하지 않으면 링크를 시키지 않으면 된다.
9.1 소스코드의 컴파일 소스의 컴파일은 한 가지만 제외하고는 대부분의 소스를 컴파일하는 경우와 같은 형식으로 수행된다. 차이점이라면 프로세스의 가상 주소 공간 안의 다른 지역에 로드될 수 있도록 하는 코드를 만들기 위해서 '-f PIC' -PIC(Position Independent Code)- 라는 옵션을 사용해야 한다는 것이다. 동적 라이브러리에서 이 단계는 반드시 필요한 것이다. 왜냐하면 정적으로 링크된 프로그램에서는 라이브러리 오브젝트의 위치가 링크시에 결정되고 그래서 고정된 시간이 되어 버리기 때문이다. 예전의 a.out 실행형식에서는 이러한 단계가 불가능했다. 왜냐하면 각 공유 라이브러리가 가상주소의 공간 안에 고정된 위치를 가지게 만들어졌기 때문이다. 결과적으로 가상메모리의 오버래핑된 지역에 로드된 두 라이브러리는 사용하길 원하는 프로그램에서는 어떠한 경우에는 충돌이 발생하게 되었다. 이것은 라이브러리들의 리스트를 유지해야만 하는 결과를 만들었다. 즉 동적 라이브러리로 만들기를 원한다면 해당 라이브러리가 어디에서 어디까지 사용한다는 것을 선언하는 부분이 반드시 필요하게 되어진 것이고 이 영역을 다른 사람들이 사용하면 안되게 된 것이다. 그렇다면 우리가 이전에 언급한 것에 따르면 공식적인 리스트에 동적 라이브러리를 등록하는 것이 필요없게 된 것이다. 왜냐하면 라이브러리는 로딩이 되어질 때 로드될 위치를 결정하게 되기 때문이다. 이것은 코드를 위치조정이 가능하게 만들었기 때문에 가능한 일이다. 9.2 라이브러리의 오브젝트를 링크하기 모든 객체를 컴파일 한 후에 동적인 로딩이 가능한 오브젝트파일로 만들기 위한 특별한 옵션이 필요하다. gcc -shared -o libName.so.xxx.yyy.zzz -Wl, -soname, libName.so.xxx 짐작할 수 있듯이 공유 라이브러리를 만들어내는 옵션이 보이는 것을 제외하고는 보통의 링크과정처럼 보인다.
하나하나 확인해보자. -shared 이것은 공유 라이브러리를 만들어라 하는 옵션이다. 그래서 라이브러리에 관련된 출력파일에 실행 가능한 형태가 되는 것이다. -o libName.so.xxx.yyy.zzz 최종적인 출력파일이름이다. 이름을 짓는데는 보통의 관례를 따를 필요는 없지만 이것은 표준적으로 개발에 사용되기를 원한다면 관례를 따르는 것이 좋다. Wl, -soname, libName.so.xxx 이 -W1옵션은 gcc(1)가 콤마로 부분된 다음 옵션들을 링커에게 알려주기 위한 것이다. 이것은 gcc(1)가 ld(1)에게 옵션을 넘겨주기 위한 방법이다. 이 예에서는 링커에게 다음과 같은 옵션을 넘겨준 것이다. -soname libName.so.xxx 이 옵션은 라이브러리에 대한 soname을 고정시키는 것이다. 그리고 필요한 다른 프로그램에서는 이 soname을 사용해야만 한다. 9.3 라이브러리를 설치하기 이미 관련된 실행파일을 가지고 있게 되었다. 이제는 이것을 적절한 장소에 설치하고 사용하기만 하면 된다. 새로운 라이브러리를 원하는 프로그램을 컴파일하기 위해서 다음과 같이 하면 된다. gcc -o program libName.so.xxx.yyy.zzz 또는 만약 라이브러리가 /usr/lib에 설치되어 있다면 단순히 다음과 같이 하는 것만으로 충분하다. gcc -o program -lName (만약 /usr/local/lib에 있다면 '-L/usr/local/lib'라는 것을 추가 시켜주면 된다.) 라이브러리를 설치하기 위해서는 다음과 같이 한다. 라이브러리를 /lib 난 또는 /usr/lib 에 복사한다. 만약 다른 장소에 복사하기로 했다면(예를 들면 /usr/local/lib) 링커인 ld(1)가 자동적으로 링크할 수는 없을 것이다. libName.so.xxx.yyy.zzz로부터 libName.so.xxx 라는 심볼릭링크를 만들기 위해서 ldconfig(1)을 수행한다. 이 단계에서 만약 이전단계가 확실히 수행되어졌다면 이 라이브러리는 동적 라이브러리로 인식이 될 것이다. 링크된 프로그램들은 이 단계에서는 영향을 받지 않는다. 이것은 실행시에 라이브러리가 로딩될 때 영향을 받는 것이다. libName.so.xxx.yyy.zzz(또는 soname 인 libName.so.xxx)로부터 libName.so 라는 심볼릭 링크를 만들어야 한다. 이렇게 해야만 하는 이유는 링커가 -1옵션으로 라이브러리를 발견할 수 있게 하기 위해서이다. libName.so 라는 형식에 맞추어진 라이브러리의 이름이 필요한 경우를 위해서 고안된 작동방법이다.
10. 정적 라이브러리 만들기 만약에 위와는 반대로 정적 라이브러리를 만드려고 한다면(또는 정적으로 링크된 것과 동적으로 링크된 것 둘 다를 원한다면) 다음과 같은 과정을 따른다.
주의 : 라이브러리를 발견하는데 있어서 링커는 libName.so 라는 파일을 먼저 찾고 그 다음에 libName.a를 찾는다. 만약 두 개의 라이브러리(정적인 버전과 동적인 버전)를 같은 이름으로 부른다면 일반적으로 각각의 경우를 링크(동적인 것이 항상 먼저 링크되기 때문에)하는 것을 결정하는 것은 불가능하게 된다. 이러한 이유로 항상 만약에 두 개의 라이브러리가 필요한 버전이 있다면 정적인 것은 libName_s.a 라고 이름을 붙여주고 동적인 것은 그냥 libName.so 라고 이름 붙여줄 것을 권하고 싶다. 링크할 때에는 그래서 다음과 같이 하면 될 것이다. gcc -o program -lName_s 이 경우는 정적인 경우이고 동적인 것을 만들 때면 다음과 같이 한다. gcc -0 program -lName 10.1 소스를 컴파일하기 소스를 컴파일하기 위해서는 특별한 방법은 없다. 위에서 말한 대로 링크단계에서 결정해야 한다. 필요하다면 -f PIC 옵션을 사용하는 것이다. 10.2 라이브러리를 객체에 링크하기 정적 라이브러리의 경우에는 링크 단계가 필요없다. 모든 객체는 ar(1) 명령어의 해서 라이브러리 파일들을 만들 수 있다. 그런 다음 심볼들을 빠르게 해석해내기 위해서 라이브러리에 대한 ranlib(1) 명령을 수행하는 것이 좋다. 비록 반드시 필요한 것은 아니지만 이 명령을 실행하지 않으면 실행파일에 대한 모듈에 대한 링크가 지워질지도 모른다. 10.3 라이브러리의 설치 정적 라이브러리는 만약 오로지 정적 라이브러리 형태로만 사용하려고 한다면 libName.a 형태로 되어있는 이름을 가지고 있을 것이다. 그러나 두 가지 형태의 라이브러리를 모두 가지고 있기를 바란다면 libName_s.a 라고 이름을 지어줄 것을 권하고 싶다. 이것은 정적이나 또는 동적으로 로딩하는 것을 쉽게 제어하기 위해서 이다. 링크단계에서 -static 옵션을 줄 수 있다. 이 옵션은 /lib/ld-linux.so 모듈의 로딩을 제어하는 것이다. 그러나 이것은 라이브러리의 검색 순서에 영향을 미치지는 않는다. 그래서 만약에 -static 으로 지정하고 ld(1)이 동적 라이브러리를 발견한다면 ld(1)는 발견된 동적 라이브러리를 가지고 작업을 할 것이다. 즉 -static 이라고 지정했다고 해서 계속적으로 정적으로 되어 있는 것을 찾지는 않는다는 것이다. 이것은 실행시에 라이브러리 루틴을 호출할 때 에러를 발생시킬 수 있다. 왜냐하면 동적 라이브러리는 실제 자신의 프로그램에는 해당 라이브러리가 있지 않기 때문이다. -자동적으로 동적인 로딩을 위한 모듈이 링크되어지지 않았고 그래서 이 단계가 수행될 수 없으므로 에러를 내는 것이다. 그래서 사용할 때 -static이 주어지면 링커가 정확한 라이브러리를 찾도록 해주어야 한다.
11.정적 링크하기와 동적 링크하기 잘 알려진 라이브러리를 사용한 프로그램을 배포하는 경우를 생각해보자.(아마 모티프라이브러리를 사용한 것이 적절한 예가 될 것이다.) 이런 종류의 소프트웨어를 만들기 위해서는 세가지 선택 사항이 있다.
첫 째는 실행파일을 정적으로 링크시켜 만드는 것이다.(오직 .a 라이브러리만을 사용한다.) 이러한 종류의 프로그램은 오직 한번만 로드되어지고 시스템 안에 있는 어떠한 라이브러리도 가지고 있을 필요가 없다.(심지어 /lib/ld-linux.so 까지도) 그러나 이것은 바이너리 파일 안에 해당 소프트웨어에 필요한 모든 것들을 가지고 다녀야 하는 단점이 있다. 그리고 대부분 프로그램의 크기가 매우 크다.
두 번째는 동적으로 만드는 것이다. 이것은 즉 우리의 소프트웨어가 실행되기 위해서는 연관된 모든 동적 라이브러리들이 모두 제공되어져야 한다는 것을 의미한다. 실행파일은 매우 작지만 모든 라이브러리를 모두 가지고 다니는 것은 쉽지 않은 일일 것이다.(예를 들면 Motif를 가지고 있지 않은 사람도 있다.)
세 번째 선택 사항이 있다. 이것은 두 가지 형태를 서로 합치는 것이다. 즉 어떠한 라이브러리는 동적으로 또 어떤 라이브러리는 정적으로 해서 두 개의 장점을 모두 취하는 것이다. 이러한 형태의 소프트웨어가 배포에는 가장 편한 방법이 된다. 예를 들면, 세가지 다른 라이브러리 포함 형태는 다음과 같다. gcc -static -o program.static program.o -lm_s -lXm_s -lXt_s -lX11_s -lXmu_s -lXpm_s gcc -o program.dynamic program.o -lm -lXm -lXt -lX11 -lXmu -lXpm gcc -o program.mixed program.o -lm -lXm_s -lXt -lX11 -lXmu -lXpm 세 번째 경우에 Motif 라이브러리인 Motif(-lXm_s)는 정적인 결과를 얻고 그리고 다른 것들은 동적인 결과를 얻게 된다. 프로그램이 실행되기 위해서는 적당한 버전을 위한 라이브러리들이 필요하게 된다. 여기에서는 libm.so.xx, libXt.so.xx, libX11.so.xx, libXmu.so.xx, libXpm.so.xx 등이 필요에 따라서 사용될 것이다.
OS/리눅스 & 유닉스 2012. 5. 16. 21:12
#include <stdio.h> #include <stdlib.h> #include <procinfo.h> #include <sys/types.h>
int main(argc, argv) int argc; char *argv[]; { struct procentry64 psinfo; struct psinfo ps; char filename[64]; pid_t pid; int fd; int count;
if (argc > 1) pid = atoi(argv[1]); else pid = getpid();
printf("My pid: %d\n", pid);
sprintf(ps.pr_psargs, "data missing", 12); sprintf(filename, "/proc/%d/psinfo", pid); fd=open(filename, O_RDONLY); if(fd == -1) { perror("open failure"); } else { count = read(fd,&ps,sizeof(struct psinfo)); if(count != sizeof(struct psinfo)) { perror("read failure"); printf("count was %d expected %d\n", count, sizeof(struct psinfo)); } close(fd); }
if (getprocs64(&psinfo, sizeof(struct procentry64), NULL, sizeof(struct fdsinfo64) , &pid, 1) > 0) { printf("%d,%0.0f,%d,%d,%d,%d,%d,%s,%s\n", (int)psinfo.pi_pid, (double) (TIMED(pi_ru.ru_utime) +TIMED(pi_ru.ru_stime)), (int)psinfo.pi_size*4, /* convert pages to KBytes */ (int)psinfo.pi_thcount, (int)psinfo.pi_state, (int)psinfo.pi_start, (int)psinfo.pi_uid, psinfo.pi_comm, ps.pr_psargs ); } else { perror("getproc64"); return 1; } }
OS/리눅스 & 유닉스 2012. 5. 15. 14:23
-
http://stackoverflow.com/questions/1251999/sed-how-can-i-replace-a-newline-n
sed ':a;N;$!ba;s/\n/ /g' file
- :a create a label 'a'
- N append the next line to the pattern space
- $! if not the last line, ba branch (go to) label 'a'
- s substitute, /\n/ regex for new line, / / by a space, /g global match (as many times as it can)
sed will loop through step 1 to 3 until it reach the last line, getting all lines fit in the pattern space where sed will substitute all \n characters
OS/리눅스 & 유닉스 2012. 4. 26. 17:45
gcc 계열 컴파일러에서 많이 발생하며 해당 lib 함수 사용시 헤더 파일을 포함하지 않았을 경우 발생한다.
OS/리눅스 & 유닉스 2012. 4. 26. 10:33
프로세스가 존재할 경우에 0을 리턴하고, 그렇지 않을 경우에 1을 리턴한다.
Example
chris@chris-laptop:~$ sleep 60 &
[1] 1316
chris@chris-laptop:~$ kill -0 1316 # process id of the sleep command
chris@chris-laptop:~$ echo $?
0
chris@chris-laptop:~$ kill -0 65535 # process does not exist
bash: kill: (65535) - No such process
chris@chris-laptop:~$ echo $?
1
chris@chris-laptop:~$ sudo kill -0 27835 # a kernel process
chris@chris-laptop:~$ echo $?
0
OS/리눅스 & 유닉스 2012. 4. 6. 17:31
Contents- 1 프로세스에 대해서
- 2 프로세스의 상태
- 3 프로세스의 모드
- 4 프로세스의 실행
- 5 멀티.다중 - 프로세스
- 5.1 fork를 이용한 자식프로세스 생성
- 5.2 fork와 exec를 이용한 새로운 프로세스의 생성
- 6 프로세스 관계
- 6.1 부모프로세스와 자식프로세스 init 프로세스
- 6.2 프로세스의 identify와 관계에서의 위치
- 6.3 고아 프로세스
- 6.4 Daemon 프로세스
|
1 프로세스에 대해서리눅스 운영체제가 하는 가장 중요한 일중의 하나는 프로그램을 실행시키는 것이다. 프로그램은 컴퓨터가 이해할 수 있는 명령어들과 명령을 수행하기 위한 데이터를 포함한 실행가능한 객체다. 이들 프로그램은 하드디스크와 같은 보조기억장치에 위치하는데 실행하면, 운영체제는 이들을 읽어서 주기억장치에 복사 한다. 프로그램이 복사된 이미지가 올라가는 것이라고 볼 수 있는데, 이러한 프로그램의 실행 된 객체를 프로세스혹은 프로그램의 실행 이미지라고 말한다. 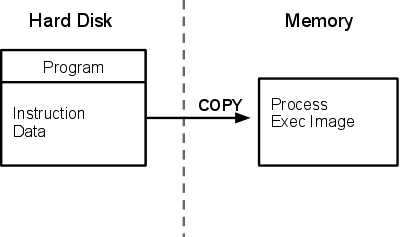 이렇게 프로그램을 직접실행시키지 않고, 메모리로 이미지를 카피해서 실행시키는 데에는 다음과 같은 이유가 있다. - 서로 완전히 독립적인 프로그램의 실행 가능
- 여러개의 이미지를 만들 수 있으므로, 멀티프로세스/멀티쓰레딩 지원
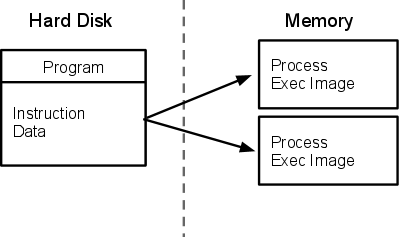 2 프로세스의 상태앞서 살펴봤듯이, 프로세스는 프로그램의 실행이미지로 동시에 수많은 동일한 혹은 다른 프로그램들이 실행될 수 있다. 동시란 말에 주목할 필요가 있는데, 여기에서 말하는 동시는 같은 시간에 실행되는 것을 의미하지 않는다. 리눅스 운영체제에서 동시라는 것은 여러개의 프로세스를 짧은 시간동안 switching하면서 실행하는 것을 의미한다. A, B, C 4개의 프로그램이 있다면, A프로그램이 끝날때까지 기다렸다가 B를 실행하는 것이 아닌, A실행을 잠깐 중단시키고, B로 스위칭해서 실행을 하고 다시 중단시키고, C를 실행 하는 방식이다. C를 실행한 후에는 다시 짧은 시간에 A로 넘어가서 이전의 중단된 시점에서 다시 프로세스를 수행한다. 이러한 switching 시간은 매우 짧기 때문에, 실제로는 동시에 실행되지 않지만 동시에 실행되는 것처럼느껴진다. 이것을 time sharing 혹은 시분할 방식이라고 한다. 이 기술은 Unix에 기본적인 기능인데, 애초에 Unix가 시분할 시스템 - time sharing system- 개발 프로젝트에서 잉태된 운영체제이기 때문이다. 이렇게 (완벽한 동시는 아니지만)동시에 프로세스를 실행하는 것을 멀티태스킹 운영체제라고 하며, 시간을 쪼개는 방식으로 멀티태스킹을 구현하는 것을 시분할 방식 멀티태스킹이라고 한다. 리눅스 운영체제는 시분할 방식 멀티태스킹환경을 지원한다. 아래 그림은 시분할 방식에서의 프로세스가 실행되는 방식을 보여주고 있다.  프로세스가 한번에 실행되지 않고, 시간을 기준으로 switching 됨으로써, 프로세스의 현재 상태가 중요해진다. 프로세스가 중단된 상황인지, 실행되고 있는지등의 정보를 알고 있어야만 올바른 시간에 switching이 가능하기 때문이다. 프로세스는 다음과 같은 4가지의 상태중 하나를 가지게 된다. - running 상태 : 실행가능한 상태를 말한다.
- waiting 상태 : 어떤 조건을 기다리는 상태.
- stopped 상태 : 실행이 중단된 상태.
- zombie 상태 : 실행이 끝나고, 메모리 상에서 프로세스의 이미지가 제거 되었으나 운영체제의 커널은 여전히 프로세스의 정보를 가지고 있는 상태. zombie에 대해서는 뒤에서 자세히 다루도록 하겠다.
3 프로세스의 모드프로세스는 유저모드와 커널모드의 두가지 모드를 오가면서, 실행이 된다. - 유저모드 : 사용자 연산을 위한 모드로 사칙연산과 같은 연산작업으로 사용자 권한으로 각정 명령이 실행된다.
- 커널모드 : 주로 컴퓨터의 자원인 메모리, 하드디스크등의 장치에 접근하기 위한 모드로, 커널권한으로 실행된다.
 굳이 귀찮게 커널모드라는 걸 두는 이유는 자원에 대한 보안의 목적이 가장 크다. 리눅스는 다중사용자 운영체제이다. 만약 메모리, 사운드카드, 하드디스크와 같은 자원에 아무런 제한없이 접근이 가능해진다면, 심각한 보안문제가 발생할 수 있을 것이다. 리눅스는 커널모드라는 것을 두어서 이문제를 해결하는데, 만약 프로세스가 시스템자원을 사용하길 원한다면, 커널에서 제공하는 API를 이용해서, 커널에 자원을 사용하겠음을 요청해야만 한다. 이렇게 되면, 운영체제 차원에서 자원에 대한 접근을 제어할 수 있게 될 것이다. 이렇게 커널에서 커널로 요청을 하기 위해서 제공하는 함수를 시스템콜이라고 부른다. 우리는 이미 몇개의 시스템콜을 사용해 봤는데, read(2), write(2), open(2)등이 대표적인 시스템콜이다. 예컨데, 프로세스는 malloc(2)함수를 호출해서 커널에 메모리의 사용을 요청할 수 있다. 요청을 받은 커널은 사용 가능한 연속적인 메모리 공간를 만든 다음, 이 메모리 공간의 주소 값을 가지는 포인터를 반환한다. 4 프로세스의 실행리눅스에서 새로운 프로세스를 실행시키는 유일한 방법은 execl(2)을 이용하는 것이다. 이 함수는 다음과 같이 사용할 수 있다. #include <unistd.h>
int execl(const char *path, const char *arg, ...);
- path : 실행되는 프로그램의 완전한 경로다.
- arg : 이것은 프로그램이 실행될때, 넘겨질 실행인자들로, 여러 개가 정의될 수 있다. 더이상 넘겨질 실행인자가 없다는 것을 분명하 하기 위해서, 마지막에 NULL을 입력해줘야 한다. 간단히 ls(1)를 실행시키는 프로그램을 만들어 보자.
#include <unistd.h>
int main(int argc, char **argv)
{
execl("/bin/ls", "ls", "-al", NULL);
}
execl 함수는 프로그램을 실행시켜서 새로운 프로세스를 실행하면, 현재의 프로세스 이미지를 덮어써 버린다. 예를들어 위의 프로그램이름이 execTest이라고 가정해보자. execTest 프로그램을 실행시키면, execTest의 실행이미지인 execTest 프로세스가 생성될 것이다. 여기에 execl을 이용해서 /bin/ls 를 실행시키면, /bin/ls의 실행이미지로 완전히 대체되어 버린다. 아래의 프로그램을 실행시켜 보자. 001 #include <unistd.h>
002 #include <stdio.h>
003
004 int main(int argc, char **argv)
005 {
006 printf("Start\n");
007 execl("/bin/ls", "ls", "-al", NULL);
008 printf("End\n"); // 실행되지 않는다.
009 }
010 다음은 실행결과다. $ ./execTest
Start
drwxr-xr-x 2 yundream yundream 4096 2008-02-29 00:08 .
drwxr-xr-x 60 yundream yundream 4096 2008-02-29 00:08 ..
-rwxr-xr-x 1 yundream yundream 6585 2008-02-29 00:08 execTest
-rw-r----- 2 yundream yundream 81 2007-12-17 23:59 hello.txt
-rw-r--r-- 1 yundream yundream 12 2007-11-26 23:58 test.txt
-rw-r--r-- 1 yundream yundream 489 2007-11-26 23:53 write.c
$
우선 6번째 코드인 printf가 실행된건 분명히 확인할 수 있을 것이다. 그다음 7번째 줄인 execl이 호출되어서 /bin/ls -al 이 실행되었다. 그런데, 8번째 줄은 실행되지 않았다 ? 앞에서 말했다 시피, execl이 호출되면서 프로세스의 이미지 자체가 /bin/ls 로 덮어써져 버렸기 때문에, 8번째 코드가 아예 실행이 되지 않기 때문이다. execl을 호출하면 프로세스의 이미지를 완전히 덮어쓰게 된다는 점을 이해하는건 그리 어렵지 않을 것이다. 그렇다면, 새로운 프로세스를 호출하고 나서, 원래의 프로그램으로 되돌아 오려면 어떡해야 하나 라는 고민이 생겨날 것이다. 새로운 프로세스를 실행시키고 나서, 프로세스가 종료되면 원래 상태로 되돌아오는 가장 대표적인 프로그램은 shell일 것이다. 쉘의 프롬프트에서 ls 를 입력하면, ls 실행된 후 다시 쉘상태로 되돌아 와서 프롬프트가 떨어지는 것을 확인할 수 있다. execl 함수는 프로세스를 덮어써 버리기 때문에, 쉘과 같은 프로그램의 제작이 불가능하다. 어떻게 쉘 같은 프로그램을 만들 수 있을까 ? 이 문제는 fork(2)를 이용한 다중 프로세스 생성기법으로 해결할 수 있는데, 이에 대한 내용은 조금 뒤에 알아보도록 할 것이다. 5 멀티.다중 - 프로세스유닉스 운영체제는 다중 프로세스를 지원한다고 알고 있다. 그런데 앞에서 프로세스를 생성하는 유일한 방법은 execl 함수를 이용하는 것이라고 배웠다. 문제는 execl 함수는 원본 프로세스의 이미지를 덮어써 버린다는 것으로, 이렇게 되면 운영체제는 동시에 단지 하나의 프로세스만을 가질 수 있게 될 것이다. 유닉스 운영체제는 fork라는 프로세스 복사 함수를 이용해서 이 문제를 해결할 수 있다. fork는 원본프로그램의 복사판을 만드는 함수다. fork와 execl 함수는 분명히 다르다는 점을 인지하도록 하자. execl은 다른 프로세스를 생성하지만 fork는 자기자신을 복제한다. 즉 유닉스 운영체제에서 새로운 프로세스를 생성시키는 유일한 방법은 여전히 execl 함수를 사용하는 것이다. +---------+ +--------------+
| Process |----+---| Copy Process |
+---------+ | +--------------+
| +--------------+
+---| Copy Process |
| +--------------+
|
+--- ...
프로세스를 복사하는게 포크와 비슷하다고 해서 fork라는 이름을 붙이게 되었다. 이때 원본 프로세스를 부모 프로세스라고 하고, 부모 프로세스로 부터 복사 되어서 새로 생성된 프로세스를 자식 프로세스라고 한다. 이들 프로세스의 관계에 대해서는 뒤에 따로 살펴보도록 하겠다. 이제 fork함수를 이용함으로써, execl이 가지는 원본 프로세스 이미지를 덮어쓰는문제를 해결할 수 있다. fork를 해서 원본프로세스의 복사본을 만들고, 여기에서 execl을 이용해서 새로운 프로세스를 실행시키는 것이다. 이러한 식으로 프로그램을 생성시키는 가장 대표적인 프로그램이 바로 shell 프로그램이다. shell 에서 ls 프로그램을 실행시키면, 다시 shell로 되돌아오는 것을 확인할 수 있을 것이다. 이는 shell 이 ls 명령을 받으면 fork함수를 이용해서 자식 프로세스를 만들고, 이 자식 프로세스에서 execl을 이용해서 ls를 실행시키기 때문에 가능해진다. 이렇게 fork & execl 을 이용하면, 진정한 멀티 프로세스 환경이 가능해 지게 된다. 유닉스 운영체제는 fork & execl 을 통해서 생성된 수많은 프로세스를 시분할방식으로 동시에 수행함으로써, 멀티 프로세스 환경을 제공한다. 5.1 fork를 이용한 자식프로세스 생성fork 는 자기자신을 복사해서 프로세스를 생성하는 운영체제에서 제공하는 함수로, 그 분기되는 모습이 포크와 비슷하다고 해서 fork라고 이름지워졌다. 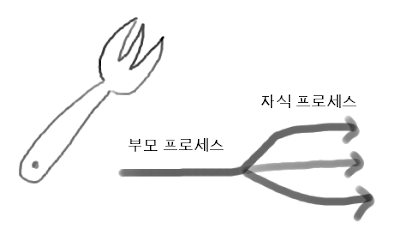 fork 함수는 다음과 같이 선언되어 있다. #include <unistd.h>
pid_t fork(void);
코드내에서 fork(2)함수를 호출하면, 자식프로세스가 생성이 된다. 이 과정은 자식이 부모의 유전학적 정보를 상속받는 것과 비슷한데, 실제 자식프로세스는 부모로 부터 많은 정보들을 그대로 상속받는다. 예를들자면, 부모프로세스의 정보들, 열려있는 파일, signal정보, 메모리에 있는 많은 정보들이다. fork함수가 성공적으로 수행되어서 자식 프로세스가 생성되면, 부모프로세스에게는 새로 생성된 자식프로세스의 PID가 리턴이 되고, 자식프로세스에게는 0이 리턴된다. 다음은 fork를 이용해서 자식프로세스를 생성시킨 프로그램이다. 프로그램의 이름은 forktest.c 로 하자. #include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
int main()
{
int pid;
int i;
i = 1000;
pid = fork();
if (pid == -1)
{
perror("fork error ");
exit(0);
}
// 자식프로세스가 실행시키는 코드
else if (pid == 0)
{
printf("자식 : 내 PID는 %d\n", getpid());
while(1)
{
printf("-->%d\n", i);
i++;
sleep(1);
}
}
// 부모프로세스가 실행시키는 코드
else
{
printf("부모 : 내가 낳은 자식의 PID는 %d\n", pid);
while(1)
{
printf("==>%d\n", i);
i += 4;
sleep(1);
}
}
}
컴파일 한 후 실행시켜 보기 바란다. 부모프로세스와 자식프로세스가 동시에 주어진 코드를 실행시키는 것을 확인할 수 있을 것이다. ps 를 이용하면 이들 프로세스와의 관계를 명확하게 확인할 수 있다. $ ps -ef | grep forktest
UID PID PPID C STIME TTY TIME CMD
yundream 12119 8557 0 17:33 pts/0 00:00:00 ./forktest
yundream 12120 12119 0 17:33 pts/0 00:00:00 ./forktest
우리는 PID 12120을 가지는 자식프로세스가 생성되었음을 확인할 수 있다. PID 12120인 프로세스가 자식프로세스인 것은 PPID값을 이용해서 확인가능 하다. PPID 는 parent Process ID의 줄임말이다. PID, PPID 등에 대한 것은 이 문서의 후반부에 자세히다루도록 할 것이다. 5.2 fork와 exec를 이용한 새로운 프로세스의 생성그럼 예제 코드를 이용해서 fork & execl의 작동방식에 대해서 알아보도록 하겠다. 여기에서 만들고자 하는 프로그램은 간단한 shell 프로그램이다. 001 #include <stdlib.h>
002 #include <string.h>
003 #include <unistd.h>
004 #include <stdio.h>
005 #include <sys/wait.h>
006 #include <sys/types.h>
007
008 #define chop(str) str[strlen(str)-1] = 0x00;
009
010 int main(int argc, char **argv)
011 {
012 char buf[256];
013 printf("My Shell\n");
014 int pid;
015 while(1)
016 {
017 // 사용자 입력을 기다린다.
018 printf("# ");
019 fgets(buf, 255, stdin);
020 chop(buf);
021
022 // 입력이 quit 라면, 프로그램을 종료한다.
023 if (strncmp(buf, "quit", 4) == 0)
024 {
025 exit(0);
026 }
027
028 // 입력한 명령이 실행가능한 프로그램이라면
029 // fork 한후 execl을 이용해서 실행한다.
030 if (access(buf, X_OK) == 0)
031 {
032 pid = fork();
033 if (pid < 0)
034 {
035 fprintf(stderr, "Fork Error");
036 }
037 if (pid == 0)
038 {
039 if(execl(buf, buf, NULL) == -1)
040 fprintf(stderr, "Command Exec Error\n\n");
041 exit(0);
042 }
043 if (pid > 0)
044 {
045 // 부모 프로세스는 자식프로세스가 종료되길 기다린다.
046 int status;
047 waitpid(pid, &status, WUNTRACED);
048 }
049 }
050 else // 만약 실행가능한 프로그램이 아니라면, 에러메시지를 출력
051 {
052 fprintf(stderr, "Command Not Found\n\n");
053 }
054 }
055 }
056 이 프로그램은 아주 간단한 shell으로, 프로그램의 인자를 처리하지도 못하지만, fork 와 execl을 설명하는데에는 부족함이 없을 것이다. 다음은 실행시킨 예이다. 프로그램이름은 myshell 로 했다. MY Shell
$ myshell
# /usr/bin/w
01:15:32 up 2:58, 4 users, load average: 0.47, 0.50, 0.62
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
yundream :0 - 00:05 ?xdm? 14:20m 0.05s /bin/bash /usr/
yundream pts/1 :0 00:06 9.00s 1.47s 1.24s w3m -F http://w
yundream pts/3 :0 00:54 0.00s 0.22s 0.00s ./myshell
yundream pts/4 :0.0 00:53 22:13m 0.40s 0.27s BitchX irc.nuri
# ll
Command Not Found
# quit
$
6 프로세스 관계6.1 부모프로세스와 자식프로세스 init 프로세스위에서 fork와 exec 함수를 이용해서 프로세스를 실행시키는 방법에 대해서 알아보았다. 여기에서 우리는 프로세스가 전혀 독립적으로 생성되는게 아닌, 부모 프로세스에서 생긴다는 것도 덤으로 배우게 되었다. 부모프로세스가 있다면, 자식뻘이 되는 프로세스가 있을 것이다. 부모프로세스로 부터 fork되어새 생성된 프로세스를 자식 프로세스라고 부른다. 부모프로세스와 자식프로세스의 관계는 쉽게 이해되었을 것이다. 그렇다면, 부모의 부모의 부모의 부모의 프로세스가 있을 것이고, 최초의 아담격인 프로세스가 있으리라는걸 추리할 수 있을 것이다. 바로 init가 모든 프로세스의 조상이 되는 프로세스다. 모든 프로세스는 init로 부터 fork & exec 되어서 생성이 된다. pstree명령을 이용하면, 프로세스의 관계를 확인할 수 있다. $ pstree
init─┬─NetworkManager───{NetworkManager}
├─NetworkManagerD
├─acpid
├─amarok───11*[{amarok}]
├─atd
├─avahi-daemon───avahi-daemon
├─bonobo-activati───{bonobo-activati}
├─console-kit-dae───61*[{console-kit-dae}]
├─cron
├─cupsd
├─2*[dbus-daemon]
├─dbus-launch
....
6.2 프로세스의 identify와 관계에서의 위치프로세스는 운영체제위에서 실행되는 실행객체이다. 객체가 객체로써 정체성을 가지기 위해서는 다른객체와 자신을 분리할 수 있는 identify 를 가지고 있어야 한다. 각 프로세스는 다음의 2가지 요소를 이용해서 자신의 identify 를 확보할 수 있다. - name : 프로세스의 이름이다.
- PID : Process ID로 운영체제가 각각의 프로세스에 부여하는 유일한일련 번호다. 프로세스의 이름만으로도 identify를 확보할 수 있을거라고 생각할 수 있지만 이름이 같은 프로세스가 생성될 수 있으므로, name만 가지고는 identify를 확보할 수 없다. 때문에 운영체제에서 일련번호를 부여하게 된다. 이 번호는 중복되지 않는 유일한 번호다. 일종의 주민등록번호 정도로 보면 될 거 같다.
프로세스 이름과 PID 를 이용해서 프로세스를 identify(식별)할 수 있게 되었다. 하지만 이것만으로는 부족하다. 프로세스는 운영체제 위에서 독립적으로 존재하지만 또한 다른 프로세스들과 관계를 맺고 있기 때문이다. 어떤 프로세스는 반드시 어떤 프로세스의 자식 프로세스가 되어야 한다. 혹은 다른 프로세스의 부모가 되기도 한다. 즉 프로세스의 identify와 함께, 프로세스의 관계에서의 위치도 정의할 수 있어야 한다. 그래서, 각 프로세스는 name과 PID외에도 프로세스군에서의 자신의 위치를 정의하기 위한 다음과 같은 정보들을 가진다. - PPID : 부모프로세스의 ID로 어떤 프로세스로 부터 생성이 되었는지를 알려준다.
- PGID : 프로세스는 여러개의 자식프로세스를 만들어낼 수 있다. 그렇다면, 이들 프로세스는 {부모-->{자식,자식,자식}}과 같이 하나의 가계를 만들 수 있을 것이다. 운영체제에서는 이것을 가계라고 하는 대신 group이라고 한다. PGID는 프로세스가 어느 그룹에 포함되어 있는지에 대한 정보를 알려준다. PGID는 일련번호로 되어 있으며, 보통 부모프로세스의 PID즉 PPID가 PGID가 된다. 즉 프로세스그룹은 부모프로세스의 PID를 공통분모로 해서 하나의 그룹을 만들게 된다.
위의 forktest.c 프로그램을 실행시키고 다음과 같이 ps 를 이용해서 프로세스 정보를 알아보도록 하자. $ ps -efjc | grep forktest
UID PID PPID PGID SID CLS PRI STIME TTY TIME CMD
yundream 12198 8557 12198 8557 TS 24 17:40 pts/0 00:00:00 ./forktest
yundream 12199 12198 12198 8557 TS 21 17:40 pts/0 00:00:00 ./forktest
프로세스의 상세정보들이 출력됨을 알 수 있다. PID가 12199인 프로세스가 12198로 부터 생성된 자식프로세스임을 확인할 수 있다. 또한 12198 프로세스는 PID 8557 로 부터 생성된 자식 프로세스임을 미루어 짐작할 수 있다. 그렇다면 PID 8557인 프로세스가 어떤 프로세스인지 확인해 보도록 하자. $ ps -efjc | grep 8557
UID PID PPID PGID SID CLS PRI STIME TTY TIME CMD
yundream 8557 8550 8557 8557 TS 24 13:37 pts/0 00:00:00 bash
그렇다. bash 프로그램임을 알 수 있다. bash는 우리가 forktest 프로그램을 실행시킨 쉘프로그램으로, bash도 fork()를 이용해서 forktest 를 실행시켰을 것임으로 forktest의 부모프로세스가 된다. 이들의 관계는 다음과 같은 Tree 형태로 표현할 수 있을 것이다. fork&exec fork
bash ---+----------- forktest ---+-------- forktest
bash의 부모프로세스는 PID 8550을 가지는 프로세스일 것이고, 거슬로 올라가면 결국 init 프로세스를 만나게 될 것이다. 그렇다면 왜 그룹이 중요한 걸까. 단지 분류하기 좋게 하기 위해서 ? 물론 그런이유도 있기는 하지만, 좀 더 근본적인 이유가 있다. 그룹은 실생활에서의 가족들이 그렇듯이, 공통의 자원을 공유하는 관계로 서로에게 영향을 끼친다. 즉 부모프로세스가 종료되면 자식 프로세스도 따라서 종료되어버리거나 부모로부터 버려진 고아가 되는 등의 영향을 받는다. 또한 부모프로세스는 자식프로세스를 종료시킬 수 있으며, 아예 분가시켜버릴 수도 있다. 부모와 자식프로세스간의 어떤 매체를 이용해서 소통 이루어진다는 건데, 리눅스 운영체제는 signal이라는 매체를 이용해서, 부모와 자식프로세스간에 소통을 한다. 예를들자면 부모프로세스가 너 그냥 죽어라라고 신호를 보내건나 보내지 않는 식이다. 만약 부모프로세스가 죽으면서, 자식프로세스들에게 너희도 따라서 죽어라 - 좀 잔인한가? - 라고 하면, 자식프로세스들도 함께 죽는 거고, 자기만 죽겠다고 하고 신호를 보내지 않는다면, 자식프로세스는 고아프로세스가 되는 식이다. signal의 사용과 고아프로세스에 대한 것은 따로 언급될 것이다. 6.3 고아 프로세스위에서 프로세스는 부모프로세스와 그룹을 맺는다는 것을 배웠다. 그리고 고아 프로세스에 대해서도 간단하게 알아보았다. 고아 프로세스란 즉, 부모프로세스가 죽으면서 자신만 죽어서 자식프로세스는 그대로 남아있는 상태다. 부모프로세스가 죽었으니 고아가 될수 밖에...!!! 고아 프로세스는 어떻게 될까. 그냥 버려질까 ? 그렇다면 너무 비정한것 같다는 생각이 든다. 유닉스 운영체제를 만들던 개발자들이 매우 인간적이여서 그랬는지는 모르겠지만 이들은 고아가된 프로세스를 init 프로세스가 관리해서 버려지지 않도록 설계를 했다. 현실에서 고아를 버리지 않고, 사회에서 보호하는 것처럼 말이다. 이론적으로 고아 프로세스는 아주 간단하게 만들수 있다. 자식프로세스를 생성시킨 후 부모프로세스를 종료시키기만 하면 된다. 위의 forktest.c에서 자식 프로세스가 고아 프로세스가 되도록 수정해 보았다. 프로그램의 이름은 forktest2.c 로 하겠다. #include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <stdio.h>
int main()
{
int pid;
int i;
i = 1000;
pid = fork();
if (pid == -1)
{
perror("fork error ");
exit(0);
}
// 자식프로세스가 실행시키는 코드
else if (pid == 0)
{
printf("자식 : 내 PID는 %d\n", getpid());
while(1)
{
printf("-->%d\n", i);
i++;
sleep(1);
}
}
// 부모프로세스가 실행시키는 코드
else
{
printf("부모 : 내가 낳은 자식의 PID는 %d\n", pid);
sleep(1);
printf("T.T 나죽네\n");
exit(0);
}
}
이제 실행시켜 보도록 하자. $ ./forktest
부모 : 내가 낳은 자식의 PID는 8207
자식 : 내 PID는 8207
-->1000
T.T 나죽네
-->1001
yundream@yundream-desktop:~$ -->1002
-->1003
yundream@yundream-desktop:~$ -->1004
-->1005
-->1006
-->1007
-->1008
쉘과는 따로 자식프로세스가 계속 실행되는걸 알 수 있을 것이다. 이제 Ctrl+C 를 눌러보자. Ctrl+C를 누르면 일반적으로 프로세스는 종료가 된다는 것을 경험적으로 알고 있을 것이다. - 정확히 말하자면 SIGINT라는 시그널이 전달되고, 이에 대한 반응으로 프로세스가 죽는다. 시그널은 나중에 다룰 것이다 -. 그러나 Ctrl+C를 아무리 눌러도 자식프로세스가 죽지 않는걸 알 수 있을 것이다. 왜냐하면, bash 의 자식의 자식 프로세스, 즉 같은 그룹에 속하지 않은 전혀 다른 그룹의 프로세스가 되었기 때문이다. ps 결과로 확인해 보도록 하자. #ps -efjc | grep forktest
UID PID PPID PGID SID CLS PRI STIME TTY TIME CMD
yundream 8207 1 8206 8093 TS 24 00:16 pts/5 00:00:00 ./forktest
PPID가 1 즉 init의 자식프로세스가 되었음을 확인할 수 있다. 집도 절도 없는 고아프로세스라는 얘기가 되겠다. 6.4 Daemon 프로세스고아프로세스는 어감이 좋지 않아 보이기는 하지만, 프로세스의 또다른 가능성을 보여준다. 즉 현재 유저와 프로세스의 영향을 받지 않고 백그라운드에서 실행되는 프로세스의 제작에 관한 것이다. 이렇게 현재 화면과 프로세스에서 떨어져 나가서 독립적으로 실행되는 프로세스를 데몬 프로세스라고 한다. 가장 대표적인 프로그램이 웹서비스를 위한 웹서버 프로그램일 것이다. 이런 프로그램들은 거의 운영체제가 시작됨과 동시에 시작되어서 운영체제가 끝날때까지 뒤에서 우리가 눈치채지 못하는 상태에서실행이 된다. 데몬프로세스가 되려면 다음과 같은 조건을 갖추어야 한다. - 일단 고아 프로세스가 되어야 한다.
데몬 프로세스는 완전히 독립된 프로세스다. 그러므로 고아 프로세스가 되어야 한다. 예컨데, 가족으로 부터 독립해서 사회로 나가야 된다는 얘기가 되겠다.
- 표준입력, 표준출력, 표준에러을 닫는다.
표준입력과 표준출력, 표준에러는 사용자와 프로세스가 상호작용 하기 위한 장치로, 표준입력은 키보드, 표준출력은 모니터로 대응된다. 데몬 프로세스는 뒤에서 독립적으로 돌아가는 프로세스 이므로 사용자와의 상호작용을 해서는 안된다. 그러므로 표준입력과 표준출력을 표준에러를 닫아줄 필요가 있다. 뒤에서 혼자 돌아야 하는 프로그램인데, 모니터에 (forktest2.c 와 같이) 잡다한 메시지를 출력해서는 안될 것이기 때문이다. 이런 데몬프로세스와의 상호작용은 IPC혹은 로그 파일 등을 통해서 이루어진다. IPC는 Inter Process Communication 의 줄임말로 프로세스간 내부통신을 위해서 사용되는 설비이다. 회사내부에서 부서원간 통화를 위해 사용되는 전화라고 볼 수 있을 것이다. 이에 대한 내용은 별도의 장을 할애해서 다루도록 할것이다. - 터미널을 가지지 않는다.
terminal(터미널)이란 사용자가 컴퓨터에 접속된 상태를 말한다. 이 터미널에 키보드와 모니터와 같은 장치가 연결되어 있고, 이것을 이용해서 사용자의 프로세스가 컴퓨터와 연결이 된다. 데몬 프로세스는 사용자 환경과 독립되어야 하므로 터미널을 끊어줘야 한다.
그렇다면, 고아 프로세스를 만든다음 고아 프로세스로 부터 표준입력,출력,에러를 닫고 터미널을 제거시키면 데몬 프로세스가 될 것이라는 것을 예상 할 수 있을 것이다. 데몬 프로세스를 만드는건 이 3가지의 과정의 코드화다. 다음은 완전한 데몬 프로세스다. 프로그램이름은 daemon.c로 하자. 001 #include <unistd.h>
002 #include <stdlib.h>
003 #include <string.h>
004 #include <stdio.h>
005
006 int main()
007 {
008 int pid;
009 int i;
010
011 i = 1000;
012 pid = fork();
013 if (pid == -1)
014 {
015 perror("fork error ");
016 exit(0);
017 }
018 // 자식프로세스가 실행시키는 코드
019 else if (pid == 0)
020 {
021 printf("자식 : 내 PID는 %d\n", getpid());
022 close(0);
023 close(1);
024 close(2);
025 setsid();
026 while(1)
027 {
028 printf("-->%d\n", i);
029 i++;
030 sleep(1);
031 }
032 }
033 // 부모프로세스가 실행시키는 코드
034 else
035 {
036 printf("부모 : 내가 낳은 자식의 PID는 %d\n", pid);
037 sleep(1);
038 printf("T.T 나죽네\n");
039 exit(0);
040 }
041 }
042 - 39 에서 부모프로세스를 종료한다.
- 22,23,24 에서 표준입력,표준출력,표준에러를 닫았다.
- setsid()를 이용해서, 사용자환경에서 독립된 자신의 환경을 만든다. 기존의 환경이 리셋되면서 터미널이 사라진다. 또한 새로운 터미널을 지정하지 않았기 때문에, 이 프로세스는 결과적으로 터미널을 가지지 않게 된다.
ps를 통해서 프로세스의 상태를 확인해 보도록 하자. $ ps -efjc | grep daemon
UID PID PPID PGID SID CLS PRI STIME TTY TIME CMD
yundream 8252 1 8252 8252 TS 24 00:43 ? 00:00:00 ./daemon
PPID가 1 이고, 새로운 Session ID인 8252를 가졌으며 (이 프로세스가 세션의 주인이므로, PID가 SID가 된다) 터미널(TTY)가 없음을 확인할 수 있다. 28번 줄의 printf 결과도 화면에 출력되지 않는 것을 확인할 수 있다. 완전한 데몬 프로세스가 만들어진 것이다. 데몬 프로세스는 특히 Internet서버 프로그램을 만드는데, 중요하게 사용되는 기법으로 네트워크 프로그래밍에서 중요하게 다루어지는 기술이다.
OS/리눅스 & 유닉스 2012. 4. 2. 15:14
OS/리눅스 & 유닉스 2012. 3. 24. 19:23
pthread_detach
실행중인 쓰레드를 detached(분리)상태로 만든다.
사용법
#include <pthread.h>
int pthread_detach(pthread_t th);
설명
pthread_detach함수는 쓰레드 식별자th를 가지는 쓰레드를 메인쓰레드에서 분리 시킨다. 이것은 th를 가지는 쓰레드가 종료되는 즉시 쓰레드의 모든 자원을 되돌려(free)줄 것을 보증한다. detach상태가 아닐경우 쓰레드가 종료한다고 하더라도 pthread_join(3)을 호출하지 않는 한 자원을 되돌려주지 않는다.
pthread_detach()함수를 호출하는 외에도 pthread_create()시 pthread_attr_t에 detachstate를 지정해 줌으로써 detach상태로 생성할 수 도 있다. pthread_attr_t는 pthread_attr_init(3)함수를 이용해서 변경할 수 있다.
쓰레드가 detach상태로 되었다면 해당 쓰레드에 대한 pthread_join()호출은 실패한다.
반환값
성공하면 0을, 실패하면 0이 아닌 값을 리턴한다.
에러
예제
#include <pthread.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
// 쓰레드 함수
// 1초를 기다린후 아규먼트^2 을 리턴한다.
void *t_function(void *data)
{
char a[100000];
int num = *((int *)data);
printf("Thread Start\n");
sleep(5);
printf("Thread end\n");
}
int main()
{
pthread_t p_thread;
int thr_id;
int status;
int a = 100;
printf("Before Thread\n");
thr_id = pthread_create(&p_thread, NULL, t_function, (void *)&a);
if (thr_id < 0)
{
perror("thread create error : ");
exit(0);
}
// 식별번호 p_thread 를 가지는 쓰레드를 detach
// 시켜준다.
pthread_detach(p_thread);
pause();
return 0;
}
OS/리눅스 & 유닉스 2012. 3. 22. 14:57
nohup(노헙) 정의
리눅스, 유닉스에서 쉘스크립트파일(*.sh)을 데몬형태로 실행시키는 프로그램
nohup 주의사항
nohup으로 실행할 쉘스크립트파일(*.sh)은 현재 퍼미션이 755이상 상태여야 한다.
chmod 755 shell.sh
nohup 실행방법
nohup shell.sh &
또는
nohup sh -- ./shell.sh &
nohup 종료방법
1. "ps -ef | grep 쉘스크립트파일명" 명령으로 데몬형식으로 실행
2. "kill -9 PID번호" 명령으로 해당 프로세스 종료
nohup 로그파일
nohup으로 쉘파일을 실행하면 자동으로 "nohup.out" 파일이 생성되며 이 파일에는 리다이
렉션을 사용하지 않은 출력문자열이 자동으로 저장된다.
예제소스
cnt=0
while true;
do
Time=`date +"%T"` # 24시간 기준 현재시간
echo $Time >> test.txt
TimeHour=`date +"%H"`
if [[ $TimeHour -eq 07 && $TimeHour -eq 07 ]] # 오전 7시에 실행
then
cnt=1
cnt=cnt+1
break
fi
echo "* * * * * Start Main Job " `date`
#
echo "* * * * * End Main Job " `date` # + 로 문자열 연결하면 안됨. 그대로 출력됨
sleep 10
done
출처 - http://www.zetswing.com/bbs/board.php?bo_table=OS_LINUX&wr_id=27
|

