요즘 카이 호스트만의 코어 자바8로 Java 8을 공부하고 있다. 작년 초에 개발자로 전향하여 Java 8의 stream 같은 것을 매우 신기해하며 어깨너머로 배워 사용했었는데 알고보니 Java 8이 처음 출시된 것은 2014년 3월 18일이었다.(Java 릴리스 페이지 참고) 지금은 Java 9가 나오려고 몸을 들썩이는 중이다. Java 8을 제대로 공부도 해보지 않았는데 벌써 Java 9가 나온다고 하니 젊은 나이에 뒤처지는 것 같은 기분이 들었다. 이런 까닭에 황급히 서점에서 책을 사서 공부하는 중이다. 원저의 제목 Core Java for the Impatient가 내 상황에 잘 들어맞는 것 같다. 더 늦기 전에 Java 8을 공부하면서 중요하다고 생각하는 것들을 정리해보려고 한다.
인터페이스
객체 지향 프로그래밍에서 인터페이스는 기능의 생김새만 나타낸다. 인터페이스는 어떤 기능에 대한 추상이며, 실제 구현은 그 인터페이스를 구현하는 클래스에게 맡긴다. 해당 인터페이스를 사용하는 입장에서는 실제 클래스가 어떻게 구현되어 있는지 몰라도 인터페이스의 생김새에 따라 함수를 호출하기만 하면 된다. 마치 복잡한 시스템의 UI(유저 인터페이스)와 같다. 구글 검색 엔진은 복잡한 시스템이지만 사용자에게 보여주는 건 질의어를 입력하는 텍스트 박스밖에 없다. 구글 검색 엔진
추상화가 잘되어 있다는 것은 (구글 검색 엔진처럼)객체의 필요한 기능만 드러내고, 복잡하고 굳이 드러내지 않아도 되는 내용들은 숨겼다는 것을 의미한다. 이전에는 이러한 인터페이스의 추상성을 철저히 지켰기 때문에 인터페이스가 어떤 상태(인스턴스 변수)나 구현된 메서드를 갖는 것이 불가능했다. 하지만 Java 8부터 인터페이스가 조금 더 유연하게 바뀌었다.
정적 메서드
기술적으로 Java에서 인터페이스에 정적 메서드를 추가하지 못할 이유는 없었다. 정적 메서드는 어차피 인스턴스와 관계가 없기 때문이다. 다만 정적 메서드도 구현된 메서드라는 점에서 인터페이스의 추상성을 해친다는 것이 문제였다. Java 8에서는 그러한 제약이 없어졌고, 인터페이스에 정적 메서드를 추가할 수 있게 되었다.(사실 이전에도 인터페이스에 정적 필드는 정의할 수 있었기 때문에 정적 메서드가 Java 8에 와서야 추가된 것은 조금 의아하다.) 기존의 제약을 깨고 정적 메서드를 추가한 것은 개발 편의성을 높이려는 시도로 보인다. Java 8 이전의 표준 라이브러리에서는 인터페이스와 관련된 정적 메서드들을 동반 클래스(companion class)에서 제공했다. 대표적인 예로 Collection 인터페이스와 Collections 동반 클래스가 있다.
Java 8에서는 인터페이스에 기본 구현을 정의할 수 있게되었다. 기본 구현이 제공되는 메서드는 구현 클래스에서 구현하지 않아도 컴파일이 가능하다. 기본 메서드는 기존의 인터페이스에 메서드를 추가해야하는 경우에 아주 유용하다. 인터페이스가 변경되는 일이 없도록 프로그램을 잘 작성하는게 좋겠지만 변경이 불가피한 상황이 생길 수도 있다. 인터페이스에 메서드를 추가하면 해당 인터페이스를 구현하는 모든 클래스에서 추가된 메서드를 구현해야하기 때문에 문제가 생긴다. 구현 클래스가 9개라면 인터페이스까지 10개의 파일을 수정해야 한다. 하지만 추가되는 메서드의 구현이 대부분 동일하다면 인터페이스에 기본적인 메서드 구현을 정의하고 유별난 클래스만 수정해주면 된다. 연료 유형을 포함하는 Car 인터페이스를 예로 들어보자.
publicinterfaceCar{
String fuelType();
}
연료 유형에 따른 구현 클래스들도 있다.
publicclassDieselCarimplementsCar{
@Override
public String fuelType(){
return"DIESEL";
}
}
publicclassGasolineCarimplementsCar{
@Override
public String fuelType(){
return"GASOLINE";
}
}
자동 주행 차량에 발빠르게 대응하기 위해서 Car 인터페이스에 자동 주행 차량 여부를 확인할 수 있는 메서드가 추가되어야한다고 생각해보자. Car는 아래와 같이 변경되어야 한다.
publicinterfaceCar{
String fuelType();
booleanautodrive();
}
이 경우에 autodrive() 메서드는 기본 구현을 제공하지 않으므로 DieselCar, GasolineCar에서 구현해줘야 한다. 하지만 기존 차량들은 자율 주행이 안될 것이기 때문에 아래와 같이 기본 구현을 제공할 수 있다.
publicinterfaceCar{
String fuelType();
defaultbooleanautodrive(){
returnfalse;
}
}
autodrive()는 FutureCar와 같은 유별난 클래스에서만 따로 구현해주면 된다.
publicclassFutureCarimplementsCar{
@Override
public String fuelType(){
return"SOLAR";
}
@Override
publicbooleanautodrive(){
returntrue;
}
}
인터페이스의 기본 메서드는 클래스의 계층을 좀 더 단순하게 만들어준다는 장점도 있다. Java 2부터 있어왔던 AbstractCollection은 Collection 구현 클래스들의 공통 기능을 제공한다. Java 8 이전에는 구현 클래스들의 공통 기능들을 묶기 위해 인터페이스와 구현 클래스 사이에 추상 클래스를 정의하는 것이 일반적이었다. 하지만 Java 8에 와서는 더 이상 추상 클래스를 추가할 필요 없이 기본 메서드를 정의할 수 있게 되었다. 이런 변화로 인터페이스와 추상 클래스의 경계가 모호해졌다는 느낌이 들지만 여전히 인스턴스 변수의 유무 차이는 존재한다.
기본 메서드의 충돌 해결하기
Java에서 하나의 클래스는 여러 인터페이스를 구현할 수 있다. Java 8 이전에는 여러 인터페이스가 같은 메서드를 갖더라도 어차피 구현은 클래스에서만 제공했기 때문에 문제가 되지 않았다. 하지만 Java 8에서 인터페이스들이 각각 동일한 메서드의 기본 구현을 제공하고, 클래스에서 충돌이 발생하는 메서드를 명시적으로 오버라이드 하지 않으면 컴파일러가 어떤 기본 메서드를 사용해야할 지 선택할 수 없기 때문에 문제가 발생한다. 책에 나와있는 예시를 살펴보자.
publicinterfacePerson{
String getName();
defaultintgetId(){ return0; }
}
publicinterfaceIdentified{
defaultintgetId(){ return Math.abs(hashCode()); }
}
publicclassEmployeeimplementsPerson, Identified{
...
}
Person과 Identified 인터페이스는 getId() 기본 메서드를 정의하고 있고, Employee 클래스는 두 인터페이스를 구현한다. Employee 클래스에서 getId()를 오버라이드 하지 않으면 Employee inherits unrelated defaults for getId() from types Person and Identified 라는 컴파일 에러가 발생한다.
한 쪽에서 기본 메서드를 구현하지 않으면 문제가 해결될까? Identified를 아래와 같이 기본 메서드 구현을 하지 않도록 바꾸고 컴파일 해보자.
publicinterfaceIdentified{
intgetId();
}
될 것 같지만 메시지가 Employee is not abstract and does not override abstract method getId() in Identified 라고 바뀔 뿐 여전히 컴파일은 되지 않는다. Person과 Identified 인터페이스가 동일한 메서드를 갖고 있긴 하지만 컴파일러 입장에서는 두 개가 정말 같은 목적의 메서드인지 알 길이 없다. 따라서 같은 모양의 메서드지만 두 메서드를 다른 것으로 보고 클래스가 Identified를 구현하지 않았다고 판단한다.(개인적으로는 이것이 일관성이 부족하다고 생각하는데 그 이유는 두 인터페이스 모두 기본 메서드를 구현하지 않는 경우에는 충돌이 일어나지 않기 때문이다.)
가장 좋은 해결 방안은 충돌이 나는 경우를 만들지 않는 것이다. 두 인터페이스가 동일한 메서드를 갖고 있다면 인터페이스 간에 상속 관계가 있지는 않은지, 메서드 이름을 너무 포괄적으로 정한 것은 아닌지 따져보고 충돌 상황을 피하는 게 좋다.
메서드 이름이나 기본 메서드 구현을 포기하지 않고 컴파일 에러를 해결하는 방법은 아래와 같다.
클래스에서 충돌 메서드 구현
가장 단순한 방법으로 클래스에서 충돌 메서드의 구현을 덮어 버리는 것이다. 이 때 클래스에서 구현을 새로 할 수도 있지만 어느 한 쪽의 기본 메서드를 사용할 수도 있다.
publicclassEmployeeimplementsPerson, Identified{
@Override
publicintgetId(){
// Person의 기본 메서드를 사용하고 싶은 경우.
// Identified의 기본 메서드를 사용하려면 Identified.super.getId()를 반환한다.
return Person.super.getId();
}
}
인터페이스간 상속
Person 인터페이스가 Identified를 상속받도록 하면 Employee에 구현 메서드가 없어도 문제를 해결할 수 있다. 하지만 이런 결정을 하기 전에 인터페이스 사이의 관계를 잘 고려해야한다.
자바에서 데이터를 가공하거나 특정 메서드를 수행할 때 새로운 클래스를 만들어서 이를 인스턴스화 해서 쓸건지 아니면 static 으로 쓸건지 고민하게 될 때가 있다. 사실 후자는 객체지향적 관점에서 그리 좋은 선택은 아니다. Vamsi Emani라는 프로그래머가 stack overflow에 남긴 질문 Why are static variables considered evil? 과 가장 많은 지지를 받은 두개의 답변을 번역했다.
Q by V. Emani
I am a Java programmer who is new to the corporate world. Recently I’ve developed an application using Groovy and Java. All through the code I’ve used quite a good number of statics. I was asked by the senior technical lot to cut down on the number of statics used. I’ve googled about the same, and I find that many programmers are fairly against using static variables.
저는 현업에 갓 뛰어든 자바 프로그래머입니다. 근래에 Groovy와 Java를 이용하는 어플리케이션을 개발하고 있습니다. 그동안 자바로 개발할 때 “static” 변수(그리고 static 메소드)를 꽤나 많이 이용하는 습관을 가지고 있었습니다. 근데 제 시니어는 static 의 개수를 줄이라고 말합니다. 그 이유가 궁금해서 구글에 검색을 해봤는데 많은 자바 프로그래머가 static 을 사용하는 것을 꺼린다는 것을 발견했습니다.
I find static variables more convenient to use. And I presume that they are efficient too (please correct me if I am wrong), because if I had to make 10,000 calls to a function within a class, I would be glad to make the method static and use a straightforward class.methodCall() on it instead of cluttering the memory with 10,000 instances of the class, right?
사실 저는 static 을 이용하는 것이 보다 편하고 효율적이라고 생각합니다. (제가 틀린 부분이 있으면 지적해주세요!) 어떤 클래스 내에서 만번의 함수 호출을 하게 된다면 그 함수를 static으로 만들어서 class.methodCall()의 형태로 사용하는 것이 만개의 인스턴스를 생성해서 메모리를 어지럽히는 것보다 훨씬 낫지 않을까요?
Moreover statics reduce the inter-dependencies on the other parts of the code. They can act as perfect state holders. Adding to this I find that statics are widely implemented in some languages like Smalltalk and Scala. So why is this oppression for statics prevalent among programmers (especially in the world of Java)?
PS: please do correct me if my assumptions about statics are wrong.
게다가 static 변수는 코드의 상호의존성(inter-dependency)을 줄여준다고 생각합니다. 상태를 저장하는데 있어서 static 변수들은 아주 유용하게 사용될 수 있습니다. 사실 static은 자바 뿐만 아니라 Smalltalk나 Scala 와 같은 프로그래밍 언어에서도 널리 이용되고 있습니다. 근데 왜 유독 자바 프로그래밍 세계에선 개발자들이 static의 사용을 꺼리는 걸까요?
PS: static 변수에 대한 제 생각에 틀린 부분을 지적해주시면 감사하겠습니다.
A by J. Skeet
Static variables represent global state. That’s hard to reason about and hard to test: if I create a new instance of an object, I can reason about its new state within tests. If I use code which is using static variables, it could be in any state – and anything could be modifying it.
Static 변수는 global state(역주: 전역 상태. 프로그램 혹은 한 모듈 전체의 상태)를 상징합니다. Global state는 추론과 테스트가 매우 까다롭습니다. 가령 코드에서 static 변수를 사용한다고 하면, 이 변수의 상태는 코드 여러 부분에서 영향을 받을 수 있게 되고 따라서 변화를 추적하기가 어려워집니다. 반면에 이를 객체화하여 인스턴스로 생성하면 테스트 중에 그 변수가 어떤 상태를 가지고 있는지 추론하는 것이 보다 간단해집니다.
I could go on for quite a while, but the bigger concept to think about is that the tighter the scope of something, the easier it is to reason about. We’re good at thinking about small things, but it’s hard to reason about the state of a million line system if there’s no modularity. This applies to all sorts of things, by the way – not just static variables.
프로그래머로서 제가 그동안 경험해온 바에 따르면 큰 개념에 대해서 그리기 위해선 일단 이해하고자 하는 범위를 좁혀 쉽게 추론할 수 있어야 합니다. 일반적으로 우리는 작으면 작을수록 그 대상을 쉽게 이해합니다. 다시 말해, 모듈화를 제대로 하지 않는다면 백만 줄 짜리 시스템의 상태에 대해서 추론하는 것은 굉장히 어려운 일입니다. 이것은 단순히 static 변수 뿐만 아니라 모든 프로그래밍 이슈에 대해서 적용할 수 있는 중요한 사실입니다.
A by A. Lockwood & J. Brown
Its not very object oriented: One reason statics might be considered “evil” by some people is they are contrary the object-oriented paradigm. In particular, it violates the principle that data is encapsulated in objects (that can be extended, information hiding, etc). Statics, in the way you are describing using them, are essentially to use them as a global variable to avoid dealing with issues like scope. However, global variables is one of the defining characteristics of procedural or imperative programming paradigm, not a characteristic of “good” object oriented code. This is not to say the procedural paradigm is bad, but I get the impression your supervisor expects you to be writing “good object oriented code” and you’re really wanting to write “good procedural code”.
첫째로, static은 객체 지향적이지 않습니다: 개발자들이 static 변수를 ‘악’으로 규정하는 이유는 static 변수가 객체 지향의 패러다임과 상반되기 때문입니다. 특히나 static 변수는, 각 객체의 데이터들이 캡슐화되어야 한다는 객체지향 프로그래밍의 원칙(역주: 한 객체가 가지고 있는 데이터들은 외부에서 함부로 접근하여 수정할 수 없도록 해야 한다는 원칙)에 위반됩니다. 질문자께서 스스로 설명했듯이 static은 스코프(역주: 한 변수가 유효한 범위)를 고려할 필요가 없는 경우, 즉 전역 변수를 사용할 때에 유용합니다. 이는 절차지향적 프로그래밍 혹은 명령형 프로그래밍(역주: C가 대표적인 절차지향적, 명령형 프로그래밍 언어이며 Java 역시 큰 범위에서 절차지향적, 명령형 프로그래밍 언어라고 할 수 있다.)에서 매우 중요한 개념입니다. 하지만 이 것이 객체지향의 관점에서 좋은 코드라고 얘기하기는 힘듭니다. 절차지향 패러다임이 나쁘다는 것이 아닙니다. 다만, 당신의 시니어는 당신이 “객체지향적으로 좋은 코드”를 짜기를 바라는 것입니다. 반대로 당신은 “절차지향적으로 좋은 코드”를 짜기를 원하는 것이라고 말할 수 있을 것입니다.
There are many gotchyas in Java when you start using statics that are not always immediately obvious. For example, if you have two copies of your program running in the same VM, will they shre the static variable’s value and mess with the state of each other? Or what happens when you extend the class, can you override the static member? Is your VM running out of memory because you have insane numbers of statics and that memory cannot be reclaimed for other needed instance objects?
사실 자바에서 static을 사용하기 시작하면 예측이 어려운 문제가 많아지게 됩니다. 예를 들어서 하나의 가상머신에서 어떤 프로그램 두 카피가 돌고 있다고 가정해봅시다. 만약 이 두 카피가 동일한 static 변수를 공유하게 된다면, 서로의 상태에 영향을 주게 되지 않을까요? 더불어서 오버라이딩을 할 수 없는 static 멤버들 때문에 클래스를 확장하는게 어려워질 것입니다. 뿐만 아니라 지나치게 많은 static 변수를 사용하게 되면 이들로부터 메모리 회수를 할 수 없어서 가상머신이 메모리 부족을 겪게 될 것입니다.
Object Lifetime: Additionally, statics have a lifetime that matches the entire runtime of the program. This means, even once you’re done using your class, the memory from all those static variables cannot be garbage collected. If, for example, instead, you made your variables non-static, and in your main() function you made a single instance of your class, and then asked your class to execute a particular function 10,000 times, once those 10,000 calls were done, and you delete your references to the single instance, all your static variables could be garbage collected and reused.
객체의 라이프타임: 추가로, static 변수는 프로그램이 실행되고 있는 내내 살아있게 됩니다. 즉, 그 클래스를 이용한 작업을 끝내더라도 static 변수가 점유하고 있는 메모리는 garbage collector(역주: 사용하지 않는 메모리를 회수하는 기능)에 의해서 회수되지 않게 됩니다. 반대로, 프로그래머가 그 변수를 인스턴스화 해서 main() 함수 내에서 하나의 인스턴스로 생성하게 되면, 그리고 그 인스턴스에게 만번의 함수 호출을 시키게 되면 그 만번의 함수 호출이 끝난 후 인스턴스는 소멸됩니다. 따라서 메모리를 훨씬 절약할 수 있게 됩니다.
Prevents certain re-use: Also, static methods cannot be used to implement an interface, so static methods can prevent certain object oriented features from being usable.
static은 재사용성이 떨어집니다: 또한, static 메서드는 interface를 구현하는데 사용될 수 없습니다. 즉 static 메서드는 프로그래머가 (재사용성을 높여주는)이러한 자바의 유용한 객체지향적 기능들을 사용하는 것을 방해합니다.
Other Options: If efficiency is your primary concern, there might be other better ways to solve the speed problem than considering only the advantage of invocation being usually faster than creation. Consider whether the transient or volatile modifiers are needed anywhere. To preserve the ability to be inlined, a method could be marked as final instead of static. Method parameters and other variables can be marked final to permit certain compiler optimizations based on assumptions about what can change those variables. An instance object could be reused multiple times rather than creating a new instance each time. There may be complier optimization switches that should be turned on for the app in general. Perhaps, the design should be set up so that the 10,000 runs can be multi-threaded and take advantage of multi-processor cores. If portability isn’t a concern, maybe a native method would get you better speed than your statics do.
static의 대안들: 프로그래머에게 효율(여기서는 속도)이 가장 중요한 문제여서 객체를 생성할 때 마다 생기는 사소한 불이익에도 민감한 상황일 수 있습니다. 이 경우에도 여전히 static 대신에 다른 방법들을 사용하는 것이 가능합니다. 먼저 “transient”나 “volatile”과 같은 제어자(modifier)를 쓸 수 있는지 먼저 고려해봅니다. 실행 속도를 빠르게 해주는 메소드 인라이닝(역주: 실제 메소드를 호출하지 않고 바로 결과값을 돌려주는 방식)을 위해 “final” 메서드를 사용하는 것도 생각해볼 수 있습니다. 또한 메서드 파라미터들과 변수들이 final로 선언되면 컴파일러 단에서의 최적화 작업이 가능해집니다. 인스턴스를 사용할 때마다 새로 생성하는 대신에 여러번 재사용할 수도 있습니다. 아마도 컴파일러 단의 최적화 작업이 switches that should be turned on for the app in general. 어쩌면 멀티스레드를 이용해서 멀티코어 프로세스의 장점을 극대화하기 위해선 이런 디자인이 필수적일 수도 있습니다. 이식성(역주: 다른 플랫폼으로 쉽게 옮길 수 있는 특성)이 중요한 것이 아니라면, native 메서드를 사용해서 static을 사용하는 것보다 더 빠르게 만들 수도 있을 것입니다.
If for some reason you do not want multiple copies of an object, the singleton design pattern, has advantages over static objects, such as thread-safety (presuming your singleton is coded well), permitting lazy-initialization, guaranteeing the object has been properly initialized when it is used, sub-classing, advantages in testing and refactoring your code, not to mention, if at some point you change your mind about only wanting one instance of an object it is MUCH easier to remove the code to prevent duplicate instances than it is to refactor all your static variable code to use instance variables. I’ve had to do that before, its not fun, and you end up having to edit a lot more classes, which increases your risk of introducing new bugs…so much better to set things up “right” the first time, even if it seems like it has its disadvantages. For me, the re-work required should you decide down the road you need multiple copies of something is probably one of most compelling reasons to use statics as infrequently as possible. And thus I would also disagree with your statement that statics reduce inter-dependencies, I think you will end up with code that is more coupled if you have lots of statics that can be directly accessed, rather than an object that “knows how to do something” on itself.
만약 여러개의 인스턴스를 만드는 것을 피하고 싶다면 싱글톤 디자인 패턴을 이용하는 것이 훌륭한 대안이 될 수 있습니다. 싱글톤 디자인은 (싱글톤을 제대로 구현했다는 전제하에) 스레드 안정성을 가지고, lazy-initialization(역주: 객체가 필요할 때마다 만들어 쓰는 기법)을 허용하며, 객체가 사용될 때마다 제대로 초기화 된다는 것을 보장합니다. 뿐만 아니라 서브 클래싱(sub-classing) 기법을 가능하게 하고, 테스트와 리팩토링이 매우 용이합니다. 다음의 상황을 가정해봅시다. 프로그래밍을 하다가 어느 시점에서 지금까지의 설계를 바꿔야겠다는 생각이 들게 되면 두말할 것도 없이 하나의 인스턴스를 수정하는 것이 모든 static 변수들을 리팩토링 하는 것보다 훨씬 편할 것입니다. 사실 static을 사용하다가 refactoring을 해야하는 상황은 매우 흔한 일입니다. 그것은 유쾌하지 않은 일일 뿐 아니라 훨씬 많은 클래스를 수정하게 만들기도 합니다. 이렇게 또다시 클래스들을 수정하다보면 새로운 버그를 만들어낼 소지가 매우 커집니다. 이런 상황을 피하기 위해서 처음에 “제대로”(위에서 언급한 방식들대로) 디자인하여 코딩하는 것이, 그 방식이 몇가지 단점을 가지고 있는 것 처럼 보여도 훨씬 나은 선택입니다. 사실 이런 끔찍한 재수정 작업이 요구될지도 모른다는 소지가 제가 static을 되도록 쓰지 않으려는 가장 큰 이유 중 하나입니다. 정리하자면, 저는 질문자께서 static이 코드의 상호의존성(inter-dependency)을 줄여준다고 말하신 것에 동의할 수 없습니다. 인스턴스화 되어 있는 객체들을 쓰지 않고 static 변수에 직접 접근하는 방식으로 코드를 짜다보면, 결국 작성한 모듈들이 서로 더 많이 엮이는 (바람직하지 않은) 상황에 처하게 될 것입니다.
가자고팀은 백엔드 어플리케이션을 Java로 개발하고 있다. Java로 개발을 하다보면 자주 쓰는 메서드들을 static (클래스 메서드)으로 선언하고자 하는 유혹이 생겨난다. 객체화를 할 필요도 없고 접근이 훨씬 용이하기 때문이다. 하지만 위의 두 개발자의 답변대로 static의 남용은 프로그램의 상태를 추정하기 어렵게 만들고 결과적으로 객체지향적이지 않은 코드를 작성하게 만든다.
물론 static을 ‘evil’이라고 규정하고 있는 이들의 의견에 전적으로 동의하는 것은 아니다. 그러나 필자도 개발 중에 static 을 빈번하게 사용하면 겪게 되는 문제들을 경험해본 적이 있다. ‘좋은 코드’라는 것에 결코 절대적인 기준이 있는 것은 아니지만, 객체지향적 프로그래밍의 원칙들을 되새겨볼때 분명 static의 사용에 심사숙고할 필요가 있어보인다.
Generic 메서드는 자신의 타입매개변수를 가진 메서드이다. generic 타입을 선언하는 것과 비슷하지만 타입매개변수의 스코프는 메서드로 제한된다. 일반 메서드, 정적 메서드 generic 클래스의 생성자는 이 룰을 동일하게 적용된다. Generic methods are methods that introduce their own type parameters. This is similar to declaring a generic type, but the type parameter's scope is limited to the method where it is declared. Static and non-static generic methods are allowed, as well as generic class constructors.
generic 메서드 문법은 return 타입 전에 꺽쇠 사이에 타입매개변수를 표기한다.static generic 메서드를 위해 타입매개변수는 반드시 메서드의 return 타입 이전에 위치해야한다. The syntax for a generic method includes a type parameter, inside angle brackets, and appears before the method's return type. For static generic methods, the type parameter section must appear before the method's return type.
Util 클래스는 두 Pair 객체를 비교하는 generic 메서드를 포함하고 있습니다. The Util class includes a generic method, compare, which compares two Pair objects:
publicclassUtil{
publicstatic <K, V> booleancompare(Pair<K, V> p1, Pair<K, V> p2){
return p1.getKey().equals(p2.getKey()) &&
p1.getValue().equals(p2.getValue());
}
}
publicclassPair<K, V> {
private K key;
private V value;
publicPair(K key, V value){
this.key = key;
this.value = value;
}
publicvoidsetKey(K key){ this.key = key; }
publicvoidsetValue(V value){ this.value = value; }
public K getKey(){ return key; }
public V getValue(){ return value; }
}
이 메서드를(static boolean compare)를 호출한 문장은 다음과 같다. The complete syntax for invoking this method would be:
Pair<Integer, String> p1 = new Pair<>(1, "apple");
Pair<Integer, String> p2 = new Pair<>(2, "pear");
boolean same = Util.<Integer, String>compare(p1, p2);
Util.<Integer, String>compare(p1, p2) 강조한 영역처럼 타입을 명시하였다. 타입인자는 컴파일러가 타입 추론할때 필요한 정보가 된다. The type has been explicitly provided, as shown in bold. Generally, this can be left out and the compiler will infer the type that is needed:
Pair<Integer, String> p1 = new Pair<>(1, "apple");
Pair<Integer, String> p2 = new Pair<>(2, "pear");
boolean same = Util.compare(p1, p2);
위의 코드는 타입 추론을 나타낸것이다. 꺽쇠에 타입 명시하지 않고 generic 메서드가 아닌 일반 메서드를 호출해도 타입 추론이 이루어진다. 이 주제는 뒤에 나오는 타입 추론 섹션에서 더 논의한다. This feature, known as type inference, allows you to invoke a generic method as an ordinary method, without specifying a type between angle brackets. This topic is further discussed in the following section, Type Inference.
기존에 있던 코드량이 줄어든 것을 볼 수 있습니다. 인자가 없기 때문에 ()로 작성하고 실제로 동작할 코드를 ->{ ... }의 내부에 작성했습니다. 처음에 적어두었던 () -> { expression body } 구조입니다. 하지만 이것은 꽤나 단순한 예제이고 이것으로 람다식이 끝은 아닙니다.
2.2. Using @FunctionalInterface
객체지향 언어인 자바에서 값이나 객체가 아닌 하나의 함수(Funtion)을 변수에 담아둔다는 것은 이해가 되지 않을 것입니다. 하지만 자바 8에서 람다식이 추가 되고 나서는 하나의 변수에 하나의 함수를 매핑할 수 있습니다.
실제로 다음과 같은 구문을 실행시키고자 한다면 어떻게 해야할까요?
Func add =(int a,int b)-> a + b;
분명히 int형 매개 변수 a,b를 받아 그것을 합치는 것을 람다식으로 표현한것입니다. 그러면 Func는 무엇이어야 할까요?
답은 interface입니다. 위와 같은 람다식을 구현하려면 Func 인터페이스를 아래처럼 작성합니다.
interfaceFunc{publicint calc(int a,int b);}
이 인터페이스에서는 하나의 추상 메소드를 가지고 있습니다. 바로 calc라는 메소드입니다. 이 메소드는 int형 매개 변수 2개를 받아 하나의 int형 변수를 반환합니다. 아직 내부 구현은 어떻게 할지 정해지지 않았죠.
이 내부 구현을 람다식으로 만든것이 처음에 보셨던 코드입니다. 아래의 코드죠.
Func add =(int a,int b)-> a + b;
여기까지는 진행에 무리가 없어보입니다. 그러면 혹시 Func 인터페이스에 메소드를 추가하게 되면 어떻게 될까요?
람다식으로 구현했던 add 함수 코드에서 오류가 납니다. 기본적으로 람다식을 위한 인터페이스에서 추상 메소드는 단 하나여야 합니다. 하지만 이러한 사실을 알고 있다 하더라도 람다식으로 사용하는 인터페이스나 그냥 메소드가 하나뿐인 인터페이스나 구별을 하기 힘들뿐더러 혹시라도 누군가 람다식으로 사용하는 인터페이스에 메소드를 추가하더라도 해당 인터페이스에서는 오류가 나지 않습니다.
따라서 이 인터페이스는 람다식을 위한 것이다라는 표현을 위해 어노테이션 @FunctionalInterface을 사용합니다. 실제로 저 어노테이션을 선언하면 해당 인터페이스에 메소드를 두 개 이상 선언하면 유효하지 않다는 오류를 냅니다. 즉, 컴파일러 수준에서 오류를 확인 할 수 있습니다.
이 코드는 조금 설명이 필요할 것 같습니다. 우선, 첫번째 연산으로 1과 2가 선택되고 계산식은 앞의 값에서 뒤의 값을 빼는 것이기 때문에 결과는 -1이 됩니다. 그리고 이상태에서 -1과 3이 선택되고 계산식에 의해 -1-3이 되기 때문에 결과로 -4가 나옵니다. 뒤로 추가 요소가 있다면 차근차근 앞에서부터 차례대로 계산식에 맞춰 계산하면 됩니다.
Java 언어는 기본적으로 JVM(Java Virtual Machine) 위에서 실행되도록 고안된 언어입니다. 이번엔 JVM의 구조를 살펴보고 하나씩 점검해 보는 포스팅입니다.
1. Java Virtual Machine
A Java virtual machine (JVM) is an abstract computing machine. There are three notions of the JVM: specification, implementation, and instance. The specification is a book that formally describes what is required of a JVM implementation. Having a single specification ensures all implementations are interoperable. A JVM implementation is a computer program that meets the requirements of the JVM specification in a compliant and preferably performant manner. An instance of the JVM is a process that executes a computer program compiled into Java bytecode.
JVM이란 추상적인 컴퓨팅 머신입니다. 그리고 JVM에는 3가지 개념이 있습니다. 이것은 명세(스펙), 구현, 그리고 인스턴스입니다. 명세는 책입니다. JVM 구현에 무엇이 요구되는지 공식적으로 설명 되어 있습니다. 하나의 명세를 가지는 것은 모든 구현의 상호 운영을 보장합니다. JVM 구현은 JVM 명세의 요구에 맞춘 컴퓨터 프로그램입니다. JVM의 인스턴스는 자바 바이트코드로 컴파일된 컴퓨터 프로그램을 실행하는 프로세스입니다.
다이어그램상으로 위에서 아래로 내려가는 과정을 수행한다고 보면 됩니다. class 파일의 정보를 Class Loader를 사용해 JVM Memory 공간으로 옮기고 이것을 Execution Engine으로 실행하는 구조입니다.
그리고 새로운 단어들이 많이 등장합니다. 하나씩 살펴봅시다.
3. Class Loader
Class Loader(이하 "클래스 로더")는 클래스 파일 포맷(.class)을 준수하는 어떠한 것이라도 인지하고 적재할 수 있도록 구현해야 합니다. 그리고 런타임(Runtime)시에 클래스를 적재하고 바른 바이트코드로 작성되었는지 검사합니다.
또한 일반적으로 클래스 로더는 두 종류로 나뉩니다. 하나는 bootstrap class loader이고 다른 하나는 user define class loader입니다. 모든 JVM 구현은 반드시 bootstrap class loader가 있어야 합니다. 그리고 JVM 명세에서 클래스 로더가 클래스를 찾는 방법을 지정하지 않습니다.
4. JVM Memory(Runtime Data Areas)
JVM Memory는 Runtime Data Areas라고도 불립니다. 해당 공간에는 Method Area, Heap, JVM Language Stacks, PC Registers, Native Method Stacks 등으로 구성 되어 있습니다.
이 공간은 클래스 로더에 의해 데이터가 적재되는 공간입니다.
4.1. Method Area
Method Area(이하 "메소드 지역")은 Type(class, inteface) 데이터들을 가지고 있습니다. 다이어그램으로 보면 아래와 같습니다.
또한 각 Type 데이터에는 Runtime Constant Pool이라는 것을 가집니다. 이 곳은 심볼 테이블(symbol table)과 유사한 구조로 되어 있습니다. 상수 풀에는 해당 Type의 메소드, 필드, 문자열 상수등의 레퍼런스를 가지고 있습니다. 실제 물리적 메모리 위치를 참조할 때 사용합니다. 그리고 종종 바이트 코드를 메모리에 전부 올리기엔 크기 때문에 바이트 코드를 참조할 레퍼런스만 상수 풀에 저장하고 추후에 해당 값을 참조해서 실행할 바이트 코드를 찾아 메모리에 적재하게 하는 경우도 있습니다. 또한, 상수 풀을 사용함으로 동적 로딩(dynamic loading)이 가능합니다.
메소드 프레임(method frame)들이 JVM 스택에 하나씩 쌓이게 됩니다. 메소드 프레임은 간단하게 메소드라고 생각해도 됩니다. 스택 자료구조 형식이기 때문에 스택의 맨위에서부터 차례대로 메소드를 실행합니다. 또한 하나의 힙을 모든 스레드가 공유합니다. 하지만 각 스레드는 자신들만의 고유 JVM 스택을 가지고 있습니다.
4.4. PC Registers
PC는 Program Counter의 축약어입니다. 따라서 원래는 Program Counter Registers가 됩니다. 해당 영역은 현재 실행하고 있는 부분의 주소(adress)를 가지고 있습니다. 일반적으로 PC의 값은 현재 명령이 끝난 뒤에 값을 증가시킵니다. 그리고 해당하는 값의 명령을 실행하게 됩니다. 즉, 실행될 명령의 주소를 가지고 있습니다.
4.5. Native Method Stacks
일반적으로 JVM은 네이티브 방식을 지원합니다. 따라서 스레드에서 네이티브 방식의 메소드가 실행되는 경우 Native Method Stacks(이하 "네이티브 스택")에 쌓입니다. 일반적인 메소드를 실행하는 경우 JVM 스택에 쌓이다가 해당 메소드 내부에 네이티브 방식을 사용하는 메소드(예를 들면 C언어로 작성된 메소드)가 있다면 해당 메소드는 네이티브 스택에 쌓입니다.
5. Execution Engine
클래스 로더에 의해 JVM 메모리 공간에 적재된 바이트 코드를 Execution Engine(이하 "실행 엔진")을 이용해 실행합니다. 하지만 바이트 코드를 그대로 쓰는 것은 아니고 기계어로 변경한 뒤에 사용하게 됩니다. 해당 작업을 실행 엔진이 합니다. 그리고 바이트 코드를 기계어로 변경할 때엔 두 종류의 방식을 사용합니다. 각각 Interpreter와 JIT (Just-In-Time) compiler입니다.
Interpreter(이하 "인터프리터")는 우리가 알고 있는대로 방식대로 바이트 코드를 실행합니다. 하나의 명령어를 그때그때 해석해서 실행하게 되어 있습니다. JIT (Just-In-Time) compiler(이하 "JIT 컴파일러")는 인터프리터의 단점(성능,속도 등)을 보완하기 위해 도입되었습니다. 실행 엔진이 인터프리터를 이용해 명령어를 하나씩 실행하지만 JIT 컴파일러는 적정한 시간에 전체 바이트 코드를 네이티브 코드로 변경합니다. 이후에는 실행 엔진이 인터프리터 대신 네이티브로 컴파일된 코드를 실행합니다.
다만 JIT 컴파일러와 Java 컴파일러는 다른 것입니다. 다이어그램을 보면 이해가 빠를 것 같습니다.
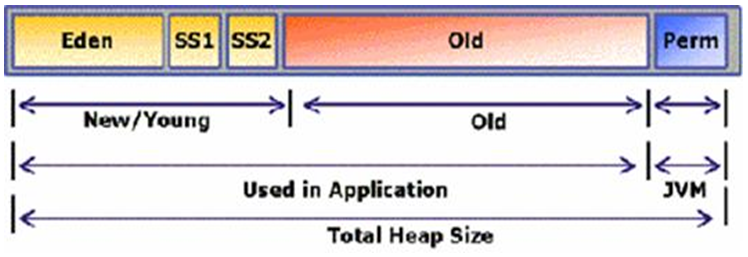
1. 자바 VM은 힙을 세개의 영역으로 나누어 사용한다. 1) New/Young 영역 : 새로 생성된 객체를 저장 2) Old 영역 : 만들어진지 오래된 객체를 저장 3) Permanent 영역 : JVM클래스와 메서드 객체를 저장
자바가 사용하는 메모리 구조
여기서 New 영역은 다시 a) Eden : 모든 새로 만들어진 객체를 저장 b) Survivor Space 1, Survivor Space 2 : Old 영역으로 넘어가기 전 객체들이 저장되는 공간 으로 구분된다.
2. Garbage Collector 자바 언어의 중요한 특징중 하나. 전통적인 언어의 경우 메모리를 사용한 뒤에는 일일이 메모리를 수거해 주어야 했다. 그러나, 자바 언어 에서는 GC기술을 사용하여 개발자로 하여금 메모리 관리에서 자유롭게 했다.
자바의 GC는 New/Young 영역과 Old 영역에 대해서만 GC를 수행한다. (Permanent 영역은 code가 올라가는 부분이기 때문에 GC가 필요없다.)
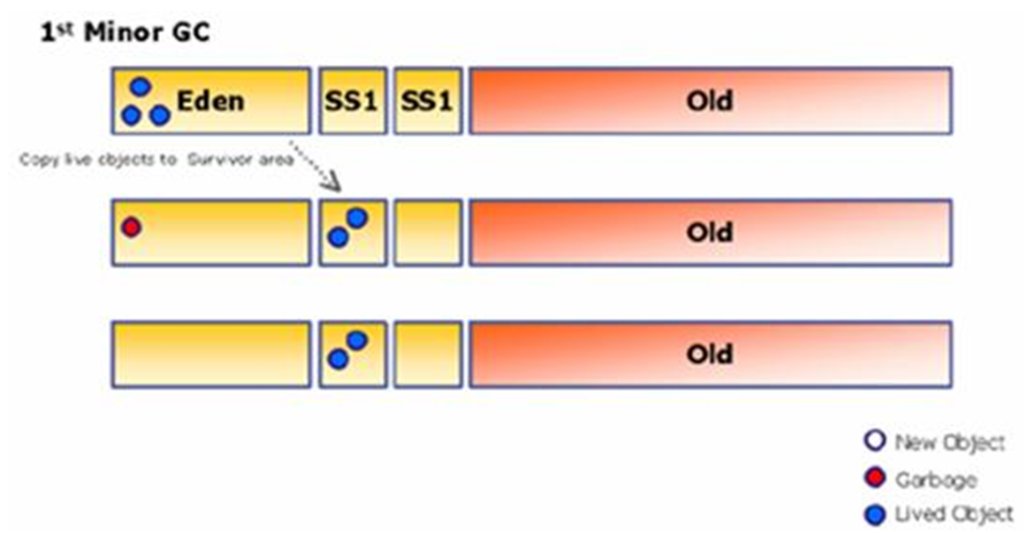
1) Minor GC New 영역의 GC를 Minor GC라고 부른다. New 영역은 Eden과 Survivor라는 두 영역으로 구분된다. Eden 영역은 자바 객체가 생성 되자 마자 저장이 되는 곳이다. 이곳의 객체가 Minor GC가 발생할 때 Survivor 영역으로 이동된다.
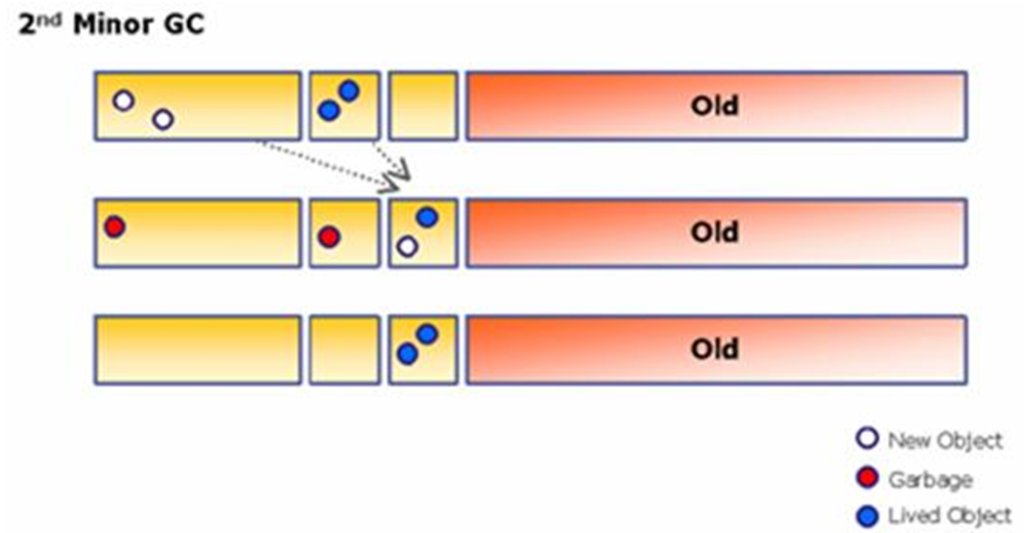
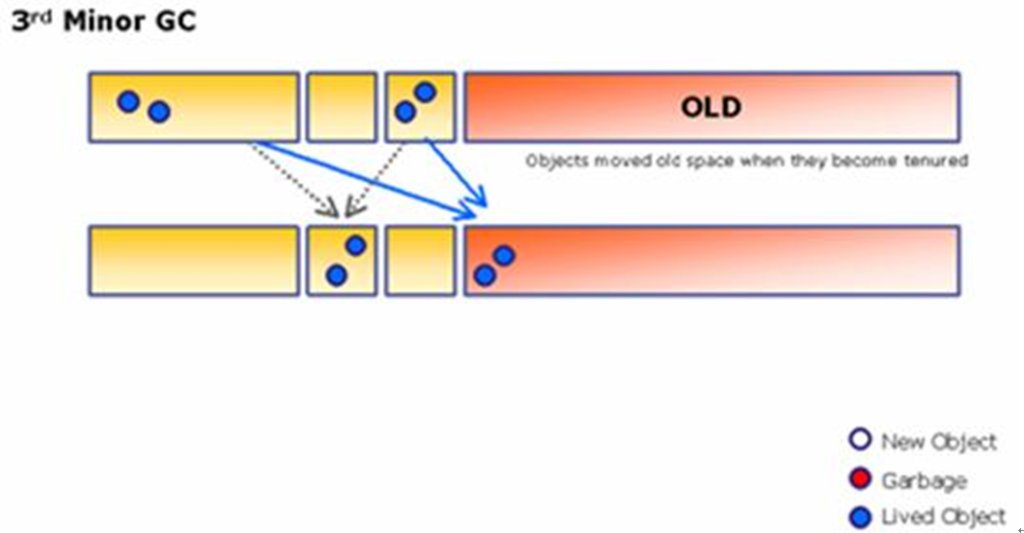
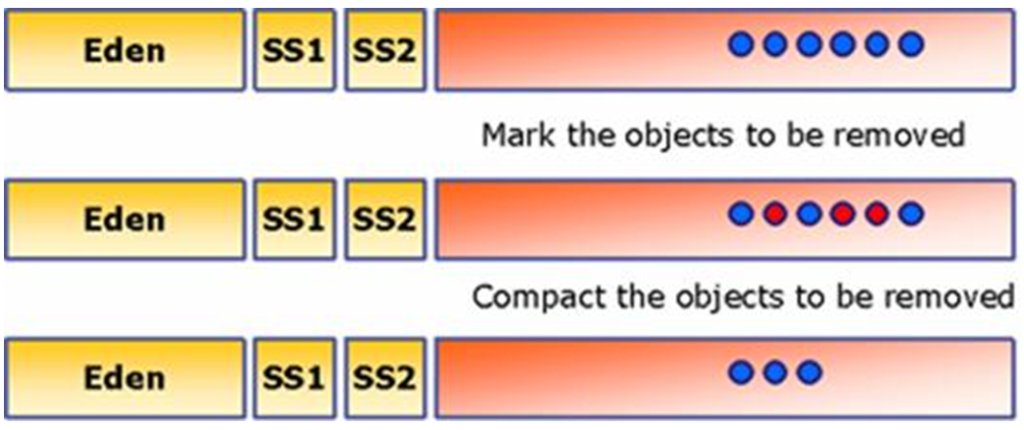
Survivor 영역은 Survivor1 과 Survivor2로 나뉘어 지는데, Minor GC가 발생하면 Eden과 Survivor1에 살아있는 객체가 Survivor2로 이동되고, Eden 영역과 Survivor1 영역에 남아있는(죽어있는) 객체는 clear된다. 결과적으로, 현재 살아있는 객체들만 Survivor2에 남아있게 된다. 다음번 Minor GC가 발생되면 같은 원리로, Eden과 Survivor2의 살아있는 객체가 Survivor1으로 이동되고, 두 영역은 Clear 된다. 이와 같은 방법으로 반복되면서 메모리를 수거한다. 이런 방식의 GC알고리즘을 Copy & Scavenge라고 한다. 속도가 빠르며 작은 크기의 메모리를 collecting 하는데 효과적이다. Minor GC 과정중 오래된 객체는 Old 영역으로 복사된다. (Kein:그런데 얼마나 지나야 '오래된' 객체인 것인지는 명확히 모르겠네요)
새로 생성된 객체가 Eden 영역에 있다가 Minor GC가 일어난다. 살아있는 객체(파란색)가 SS1으로 옮겨지고 죽은객체(빨간색)는 그대로 남겨진다. 이후 Eden과 SS2를 clear 한다.
Eden에 새로 생성된 객체와 SS1에 있는 살아있는 객체를 SS2로 옮기고, Eden과 SS1 을 clear 한다.
생성된지 오래된 객체를 Old 영역으로 이동한다.
2) Full GC Old 영역의 GC를 Full GC라 한다. Mark & Compact 알고리즘을 이용하는데, 전체 객체들의 reference를 따라가면서 연결이 끊긴 객체를 marking 한다. 이 작업이 끝나면 사용되지 않는 객체가 모두 mark 되고, 이 객체들을 삭제한다. 실제로는 삭제가 아니라, mark 된 객체로 생기는 부분을 unmark된, 즉 사용중인 객체로 메꾸는 방법이다.
Full GC는 속도가 매우 느리며, Full GC가 일어나는 도중에 순간적으로 java application이 멈춰버리기 때문에 Full GC가 일어나는 정도와 Full GC에 소요되는 시간은 application의 성능과 안정성에 매우 큰 영향을 미치게 된다.
Full GC 동작 순서
3. Garbage Collection이 중요한 이유 Minor GC는 보통 0.5초 이내에 끝나기 때문에 큰 문제가 되지 않는다. 하지만, Full GC의 경우 보통 수 초가 소요되고, GC동안 Application이 멈추기 때문에 문제가 될 수 있다. 5초 동안 서버가 멈춘다면, 멈춰있는 동안 사용자의 request는 쇄도하게 되고, queue에 저장되었다가 요청이 한꺼번에 들어오게되면 여러 장애를 발생할 수 있게 된다. 원할한 서비스를 위해서 GC를 어떻게 일어나게 하느냐가 시스템의 안정성과 성능에 변수로 작용하게 된다.
4. Garbage Collection 알고리즘들 1) Default Collector 위에 설명한 전통적인 GC방법으로 Minor GC에 Scavenge를, Full GC에 Mark & Compact를 사용하는 방법이다.
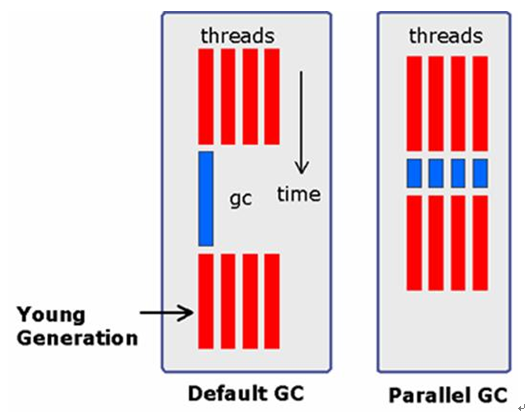
2) Parallel GC JDK 1.3까지는 하나의 thread 에서만 GC가 수행되었다. JDK 1.4 부터 지원되는 parallel gc 는 minor gc를 동시에 여러개의 thread 를 이용해서 수행하는 방법으로 하나의 thread 에서 gc를 수행하는 것보다 빠른 gc를 수행한다.
하지만, parallel gc가 언제나 유익한 것은 아니다. 1 CPU에서는 오히려 parallel gc 가 느리다. multi thread에 대한 지원이나 계산등을 위해서 4CPU의 256M 정도의 메모리를 보유한 시스템에서 유용하게 사용된다. parallel gc 는 두가지 옵션을 제공하는데, Low-Pause 방식과 Throughput 방식이다. solaris 기준으로 Low-pause 방식은 ?XX:+UseParNewGC 옵션을 사용한다. Old GC를 수행할 때 Application 이 멈추는 현상을 최소화 하는데 역점을 두었다. Throughput 방식은 ?XX:+UseParallelGC 옵션을 사용하며, Old 영역을 GC할때는 기본 옵션을 사용하며 Minor GC가 발생했을 때 최대한 빨리 수행되도록 throughput에 역점을 둔 방식이다.
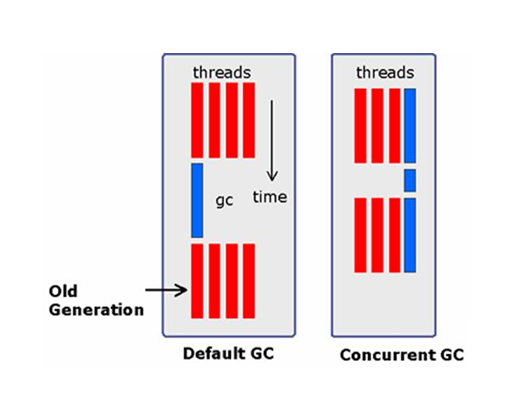
3) Concurrent GC Full GC를 하는 동안 시간이 길고, Application이 순간적으로 멈추는 현상이 발생하는 단점을 보완하기 위해서, Full GC에 의해 Application이 멈추는 현상을 최소화 하기 위한 방법이다. Full GC에 소요되는 작업을 Application을 멈추고 하는것이 아니라, 일부는 Application을 수행하고, Application이 멈추었을때 최소한의 작업만을 GC에 할당하는 방법으로 Application이 멈추는 시간을 최소화 한다.
Application이 수행중 일 때 (붉은라인) Full GC를 위한 작업을 수행한다. Application이 멈춘 시간동안에는 일부분의 작업을 수행하기 때문에 기존 Default 방법보다 멈추는 시간이 현저하게 줄어든다. solaris JVM 에서는 -XX:+UseConcMarkSweepGC 옵션을 사용한다.
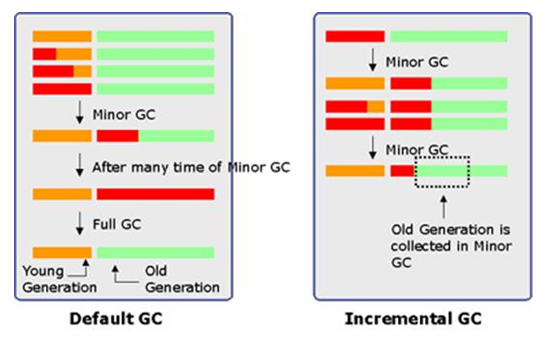
4) Incremental GC (Train GC) Incremental GC 또는 Train GC 라고 불리우는 방법은 JDK 1.3 부터 지원된 방법이다. 의도 자체는 Full GC 동안 Application이 멈추는 시간을 최소화 하는데 목적이 있다. Minor GC가 일어날 때 마다 Old 영역을 조금씩 GC를 해서, Full GC가 발생하는 횟수나 시간을 줄이는 방법이다.
그림에서 보듯,왼쪽의 Default GC는 Full GC가 일어난 후에나 Old 영역이 Clear된다. 그러나, 오른쪽의 Incremental GC를 보면 Minor GC가 일어난후에, Old 영역이 일부 Collect된것을 알 수 있다. Incremental GC를 사용하는 방법은 JVM 옵션에 ?Xinc 옵션을 사용하면 된다. Incremental GC는 많은 자원을 소모하고, Minor GC를 자주일으키며, Incremental GC를 사용한다고 Full GC가 없어지거나 그 횟수가 획기적으로 줄어드는 것은 아니다. 오히려 느려지는 경우가 많다.
5. GC 로그 수집 및 분석 방법 이제 적군에 대해 알았으니 나 자신을 파악할 차례다. 내 Application의 gc 동태를 파악하기 위해 java 실행 옵션에 -verbose:gc 옵션을 주면 gc 로그를 출력할 수 있다.
garbage collection 로그
로그중 GC 는 Minor GC 이고, Full GC는 Full GC를 나타낸다. 그 뒤의 숫자는 GC수행 전 heap 메모리 사용량 이다. (New + Old + Perm 영역) 그뒤 -> 이후의 숫자는 GC 수행 후 heap 메모리 사용량을 나타낸다. Minor GC 가 수행된 뒤에는 Eden 과 Survivor 영역의 GC가 수행된 것이며, GC이후 heap 사용량은 Old영역의 용량과 유사하다. 괄호 안의 Total Heap Size 는 현재 jvm 이 사용하는 Heap memory의 양이다. 이 크기는 java 실행 옵션의 -Xms -Xmx 옵션으로 설정이 가능한데, 예를 들어 -Xms512 -Xmx1024로 해 놓으면 jvm는 메모리 사용량에 따라서 512~1024m 사이에서 적절하게 메모리 사용량을 늘였다 줄였다 하며 동작한다. 그 다음값은 gc에 소요된 시간이다.
위의 로그를 보면, Minor GC가 일어날 때 마다 약 20,000Kbytes 정도의 collection이 일어난다. Minor GC는 Eden과 survivor 영역 하나를 gc 하는 것이기 때문에 New 영역을 20,000Kbyte 정도로 생각할 수 있다. Full GC 때를 보면 약 44,000Kbytes 에서 1,749Kbytes 로 줄어든 것을 볼 수 있다. Old 영역에 큰 데이터가 많지 않은 경우이다. Data를 많이 사용하는 Application의 경우 전체 Heap 이 512M 라 할 때, Full GC 후에도 480M 정도로 유지되는 경우가 있다. 이런 경우에는 실제로 Application이 메모리를 많이 사용하는 경우라고 판단할 수 있기 때문에, 전체 Heap 메모리를 늘려주면 효과적이다.
Part I: An Overview of Java Classloaders, Delegation and Common Problems
In this part, we provide an overview of classloaders, explain how delegation works and examine how to solve common problems that Java developers encounter with classloaders on a regular basis.
Introduction: Why you should know, and fear, Classloaders
Classloaders are at the core of the Java language. Java EE containers, OSGi, various web frameworks and other tools use classloaders heavily. Yet, something goes wrong with classloading, would you know how to solve it?
Join us for a tour of the Java classloading mechanism, both from the JVM and developer point-of-view. We will look at typical problems related to classloading and how to solve them. NoClassDefFoundError, LinkageError and many others are symptoms of specific things going wrong that you can usually find and fix. For each problem, we’ll go through an example with a corresponding solution. We’ll also take a look at how and why classloaders leak and how can that be remedied.
And for dessert, we review how to reload a Java class using a dynamic classloader. To get there we’ll see how objects, classes and classloaders are tied to each other and the process required to make changes. We begin with a bird’s eye view of the problem, explain the reloading process, and then proceed to a specific example to illustrate typical problems and solutions.
Enter java.lang.ClassLoader
Let’s dive into the beautiful world of classloader mechanics.
It’s important to realize that each classloader is itself an object–an instance of a class that extends java.lang.ClassLoader. Every class is loaded by one of those instances and developers are free to subclass java.lang.ClassLoader to extend the manner in which the JVM loads classes.
There might be a little confusion: if a classloader has a class and every class is loaded by a classloader, then what comes first? We need an understanding of the mechanics of a classloader (by proxy of examining its API contract) and the JVM classloader hierarchy.
First, here is the API, with some less relevant parts omitted:
package java.lang;
publicabstractclassClassLoader{
public Class loadClass(String name);
protected Class defineClass(byte[] b);
public URL getResource(String name);
public Enumeration getResources(String name);
public ClassLoader getParent()
}
By far, the most important method of java.lang.ClassLoader is the loadClass method, which takes the fully qualified name of the class to be loaded and returns an object of class Class.
The defineClass method is used to materialize a class for the JVM. The byte array parameter ofdefineClass is the actual class byte code loaded from disk or any other location.
What if you no longer had to redeploy your Java code to see changes? The choice is yours. In just a few clicks you can Say Goodbye to Java Redeploys forever.
getResource and getResources return URLs to actually existing resources when given a name or a path to an expected resource. They are an important part of the classloader contract and have to handle delegation the same way as loadClass – delegating to the parent first and then trying to find the resource locally. We can even view loadClass as being roughly equivalent todefineClass(getResource(name).getBytes()).
The getParent method returns the parent classloader. We’ll have a more detailed look at what that means in the next section.
The lazy nature of Java has an effect on how do classloaders work – everything should be done at the last possible moment. A class will be loaded only when it is referenced somehow – by calling a constructor, a static method or field.
Now let’s get our hands dirty with some real code. Consider the following example: class A instantiates class B.
publicclassA{
publicvoiddoSomething(){
B b = new B();
b.doSomethingElse();
}
}
The statement B b = new B() is semantically equivalent to B b = A.class.getClassLoader().loadClass(“B”).newInstance()
As we see, every object in Java is associated with its class (A.class) and every class is associated with classloader (A.class.getClassLoader()) that was used to load the class.
When we instantiate a ClassLoader, we can specify a parent classloader as a constructor argument. If the parent classloader isn’t specified explicitly, the virtual machine’s system classloader will be assigned as a default parent. And with this note, let’s examine the classloader hierarchy of a JVM more closely.
자바는 동적으로 클래스를 읽어온다. 즉, 런타임에 모든 코드가 JVM에 링크된다. 모든 클래스는 그 클래스가 참조되는 순간에 동적으로 JVM에 링크되며, 메모리에 로딩된다. 자바의 런타임 라이브러리([JDK 설치 디렉토리]/jre/lib/rt.jar) 역시 예외가 아니다. 이러한 동적인 클래스 로딩은 자바의 클래스로더 시스템을 통해서 이루어지며, 자바가 기본적으로 제공하는 클래스로더는 java.lang.ClassLoader를 통해서 표현된다. JVM이 시작되면, 부트스트랩(bootstrap) 클래스로더를 생성하고, 그 다음에 가장 첫번째 클래스인 Object를 시스템에 읽어온다.
런타임에 동적으로 클래스를 로딩하다는 것은 JVM이 클래스에 대한 정보를 갖고 있지 않다는 것을 의미한다. 즉, JVM은 클래스의 메소드, 필드, 상속관계 등에 대한 정보를 알지 못한다. 따라서, 클래스로더는 클래스를 로딩할 때 필요한 정보를 구하고, 그 클래스가 올바른지를 검사할 수 있어야 한다. 만약 이것을 할 수 없다면, JVM은 .class 파일의 버전이 일치하지 않을 수 있으며, 또한 타입 검사를 하는 것이 불가능할 것이다. JVM은 내부적으로 클래스를 분석할 수 있는 기능을 갖고 있으며, JDK 1.1부터는 개발자들이 리플렉션(Reflection)을 통해서 이러한 클래스의 분석을 할 수 있도록 하고 있다.
로드타임 동적 로딩(load-time dynamic loading)과 런타임 동적 로딩(run-time dynamic loading)
클래스를 로딩하는 방식에는 로드타임 동적 로딩(load-time dynamic loading)과 런타임 동적 로딩(run-time dynamic loading)이 있다. 먼저 로드타임 동적 로딩에 대해서 알아보기 위해 다음과 코드를 살펴보자.
public class HelloWorld { public static void main(String[] args) { System.out.println("안녕하세요!"); } }
HelloWorld 클래스를 실행하였다고 가정해보자. 아마도, 명령행에서 다음과 같이 입력할 것이다.
$ java HelloWorld
이 경우, JVM이 시작되고, 앞에서 말했듯이 부트스트랩 클래스로더가 생성된 후에, 모든 클래스가 상속받고 있는 Object 클래스를 읽어온다. 그 이후에, 클래스로더는 명령행에서 지정한 HelloWorld 클래스를 로딩하기 위해, HelloWorld.class 파일을 읽는다. HelloWorld 클래스를 로딩하는 과정에서 필요한 클래스가 존재한다. 바로 java.lang.String과 java.lang.System이다. 이 두 클래스는 HelloWorld 클래스를 읽어오는 과정에서, 즉 로드타임에 로딩된다. 이 처럼, 하나의 클래스를 로딩하는 과정에서 동적으로 클래스를 로딩하는 것을 로드타임 동적 로딩이라고 한다.
이제, 런타임 동적 로딩에 대해서 알아보자. 우선, 다음의 코드를 보자.
public class HelloWorld1 implements Runnable { public void run() { System.out.println("안녕하세요, 1"); } } public class HelloWorld2 implements Runnable { public void run() { System.out.println("안녕하세요, 2"); } }
이 두 클래스를 Runnable 인터페이스를 구현한 간단한 클래스이다. 이제 실제로 런타임 동적 로딩이 일어나는 클래스를 만들어보자.
public class RuntimeLoading { public static void main(String[] args) { try { if (args.length < 1) { System.out.println("사용법: java RuntimeLoading [클래스 이름]"); System.exit(1); } Class klass = Class.forName(args[0]); Object obj = klass.newInstance(); Runnable r = (Runnable) obj; r.run(); } catch(Exception ex) { ex.printStackTrace(); } } }
위 코드에서, Class.forName(className)은 파리미터로 받은 className에 해당하는 클래스를 로딩한 후에, 그 클래스에 해당하는 Class 인스턴스(로딩한 클래스의 인스턴스가 아니다!)를 리턴한다. Class 클래스의 newInstance() 메소드는 Class가 나타내는 클래스의 인스턴스를 생성한다. 예를 들어, 다음과 같이 한다면 java.lang.String 클래스의 객체가 생성된다.
Class klass = Class.forName("java.lang.String"); Object obj = klass.newInstance();
따라서, Class.forName() 메소드가 실행되기 전까지는 RuntimeLoading 클래스에서 어떤 클래스를 참조하는 지 알수 없다. 다시 말해서, RuntimeLoading 클래스를 로딩할 때는 어떤 클래스도 읽어오지 않고, RuntimeLoading 클래스의 main() 메소드가 실행되고 Class.forName(args[0])를 호출하는 순간에 비로서 args[0]에 해당하는 클래스를 읽어온다. 이처럼 클래스를 로딩할 때가 아닌 코드를 실행하는 순간에 클래스를 로딩하는 것을 런타임 동적 로딩이라고 한다.
다음은 RuntimeLoading 클래스를 명령행에서 실행한 결과를 보여주고 있다.
$ java RuntimeLoading HelloWorld1 안녕하세요, 1
Class.newInstance() 메소드와 관련해서 한 가지 알아둘 점은 해당하는 클래스의 기본생성자(즉, 파라미터가 없는)를 호출한다는 점이다. 자바는 실제로 기본생성자가 코드에 포함되어 있지 않더라도 코드를 컴파일할 때 자동적으로 기본생성자를 생성해준다. 이러한 기본생성자는 단순히 다음과 같이 구성되어 있을 것이다.
public ClassName() { super(); }
ClassLoader
자바는 클래스로더를 사용하고, 클래스를 어떻게 언제 JVM으로 로딩하고, 언로딩하는지에 대한 특정한 규칙을 갖고 있다. 이러한 규칙을 이해해야, 클래스로더를 좀 더 유용하게 사용할 수 있으며 개발자가 직접 자신만의 커스텀 클래스로더를 작성할 수 있게 된다.
클래스로더의 사용
이 글을 읽는 사람들은 거의 대부분은 클래스로더를 프로그래밍에서 직접적으로 사용해본 경험이 없을 것이다. 클래스로더를 사용하는 것은 어렵지 않으며, 보통의 자바 클래스를 사용하는 것과 완전히 동일하다. 다시 말해서, 클래스로더에 해당하는 클래스의 객체를 생성하고, 그 객체의 특정 메소드를 호출하기만 하면 된다. 간단하지 않은가? 다음의 코드를 보자.
ClassLoader cl = . . . // ClassLoader의 객체를 생성한다. Class klass = null; try { klass = cl.loadClass("java.util.Date"); } catch(ClassNotFoundException ex) { // 클래스를 발견할 수 없을 경우에 발생한다. ex.printStackTrace(); }
일단 클래스로더를 통해서 필요한 클래스를 로딩하면, 앞의 예제와 마찬가지로 Class 클래스의 newInstance() 메소드를 사용하여 해당하는 클래스의 인스턴스를 생성할 수 있게 된다. 형태는 다음과 같다.
위 코드를 보면, Class.newInstance()를 호출할 때 몇개의 예외와 에러가 발생하는 것을 알 수 있다. 이것들에 대한 내용은 Java API를 참고하기 바란다.
자바 2의 클래스로더
자바 2 플랫폼에서 클래스로더의 인터페이스와 세만틱(semantic)은 개발자들이 자바 클래스로딩 메커니즘을 빠르고 쉽게 확장할 수 있도록 하기 위해 몇몇 부분을 재정의되었다. 그 결과로, 1.1이나 1.0에 맞게 작성된 (커스텀 클래스로더를 포함한) 클래스로더는 자바 2 플랫폼에서는 제기능을 하지 못할 수도 있으며, 클래스로더 사용하기 위해 작성했던 코드를 재작성하는 것이 그렇게 간단하지만은 않다.
자바 1.x와 자바 2에서 클래스로더에 있어서 가장 큰 차이점은 자바 2의 클래스로더는 부모 클래스로더(상위 클래스가 아니다!)를 갖고 있다는 점이다. 자바 1.x의 클래스로더와는 달리, 자바 2의 클래스로더는 부모 클래스로더가 먼저 클래스를 로딩하도록 한다. 이를 클래스로더 딜리게이션 모델(ClassLoader Delegation Model)이라고 하며, 이것이 바로 이전 버전의 클래스로더와 가장 큰 차이점이다.
자바 2의 클래스로더 딜리게이션 모델에 대해 구체적으로 알아보기 위해 로컬파일시스템과 네트워크로부터 클래스를 읽어와야 할 필요가 있다고 가정해보자. 이 경우, 쉽게 로컬파일시스템의 jar 파일로부터 클래스를 읽어오는 클래스로더와 네트워크로부터 클래스를 읽어오는 클래스로더가 필요하다는 것을 생각할 수 있다. 이 두 클래스로더를 각각 JarFileClassLoader와 NetworkClassLoader라고 하자.
JDK 1.1에서, 커스텀 클래스로더를 만들기 위해서는 ClassLoader 클래스를 상속받은 후에 loadClass() 메소드를 오버라이딩하고, loadClass() 메소드에서 바이트코드를 읽어온 후, defineClass() 메소드를 호출하면 된다. 여기서 defineClass() 메소드는 읽어온 바이트코드로부터 실제 Class 인스턴스를 생성해서 리턴한다. 예를 들어, JarFileClassLoader는 다음과 같은 형태를 지닐 것이다.
public class JarFileClassLoader extends ClassLoader { ... private byte[] loadClassFromJarFile(String className) { // 지정한 jar 파일로부터 className에 해당하는 클래스의 // 바이트코드를 byte[] 배열로 읽어온다. .... return byteArr; }
public synchronized class loadClass(String className, boolean resolveIt) throws ClassNotFoundException {
Class klass = null;
// 클래스를 로드할 때, 캐시를 사용할 수 있다. klass = (Class) cache.get(className);
if (klass != null) return klass;
// 캐시에 없을 경우, 시스템 클래스로더로부터 // 지정한 클래스가 있는 지 알아본다. try { klass = super.findSystemClass(className); return klass; } catch(ClassNotFoundException ex) { // do nothing }
// Jar 파일로부터 className이 나타내는 클래스를 읽어온다. byte[] byteArray = loadClassFromJarFile(className); klass = defineClass(byteArray, 0, byteArray.length); if (resolve) resolveClass(klass); cache.put(className, klass); // 캐시에 추가 return klass; } }
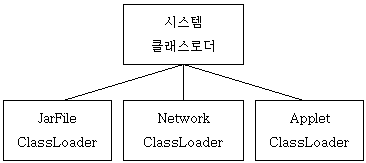
위의 개략적인 코드를 보면, 시스템 클래스로더에게 이름이 className인 클래스가 존재하는 지 요청한다. (여기서 시스템 클래스로더 또는 primordial 시스템 클래스로더는 부트스트랩 클래스로더이다). 그런 후에, 시스템 클래스로더로부터 클래스를 읽어올 수 없는 경우 Jar 파일로부터 읽어온다. 이 때, className은 완전한 클래스 이름(qualified class name; 즉, 패키지이름을 포함한)이다. NetworkClassLoader 클래스 역시 이 클래스와 비슷한 형태로 이루어져 있을 것이다. 이 때, 시스템 클래스로더와 그 외의 다른 클래스로더와의 관계는 다음 그림과 같다.
위 그림을 보면, 각각의 클래스로더는 오직 시스템 클래스로더와 관계를 맺고 있다. 다시 말해서, JarFileClassLoader는 NetworkClassLoader나 AppletClassLoader와는 관계를 맺고 있지 않다. 이제, A라는 클래스가 내부적으로 B라는 클래스를 사용한다고 가정해보자. 이 때, 만약 A 클래스는 네트워크를 통해서 읽어오고, B라는 클래스는 Jar 파일을 통해서 읽어와야 한다면? 이 경우에 어떻게 해야 하는가? 쉽사리 해결책이 떠오르지 않을 것이다. 이러한 문제는 JarFileClassLoader와 NetworkClassLoader 간에 유기적인 결합을 할 수 없기 때문에 발생한다.
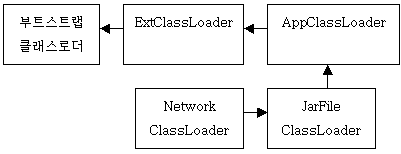
자바 2에서는 이러한 문제를 클래스로더 딜리게이션 모델을 통해서 해결하고 있다. 즉, 특정 클래스로더 클래스를 읽어온 클래스로더(이를 부모 클래스로더라고 한다)에게 클래스 로딩을 요청하는 것이다. 다음의 그림을 보자.
이 그림은 자바 2에서 클래스로더간의 관계를 보여주고 있다. 이 경우, NetworkClassLoader 클래스는 JarFileClassLoader가 로딩하고, JarFileClassLoader 클래스는 AppClassLoader가 로딩하였음을 보여준다. 즉, JarFileClassLoader는 NetworkClassLoader의 부모 클래스로더가 되고, AppClassLoader는 JarFileClassLoader의 부모 클래스로더가 되는 것이다.
이 경우, 앞에서 발생했던 문제가 모두 해결된다. A 클래스가 필요하면, 가장 먼저 NetworkClassLoader에 클래스로딩을 요청한다. 그럼, NetworkClassLoader는 네트워크로부터 A 클래스를 로딩할 수 있으므로, A 클래스를 로딩한다. 그런 후, A 클래스는 B 클래스를 필요로 한다. B 클래스를 로딩하기 위해 NetworkClassLoader는 JarFileClassLoader에 클래스 로딩을 위임(delegation)한다. JarFileClassLoader는 Jar 파일로부터 B 클래스를 읽어온 후 NetworkClassLoader에게 리턴할 것이며, 따라서 NetworkClassLoader는 Jar 파일에 있는 B 클래스를 사용할 수 있게 된다. 앞의 JDK 1.1에서의 클래스로더 사이의 관계에 비해 훨씬 발전적인 구조라는 것을 알 수 있다.
앞에서 말했듯이, 자바 2에서는 몇몇 클래스로더 메커니즘을 재정의하였다. 이 때문에, JDK 1.1에서의 클래스로더에 관한 몇몇개의 규칙이 깨졌다. 먼저, loadClass() 메소드를 더 이상 오버라이딩(overriding) 하지 않고, 대신 findClass()를 오버라이딩한다. loadClass() 메소드는 public에서 protected로 변경되었으며, 실제 JDK1.3의 ClassLoader 클래스의 소크 코드를 보면 다음과 같이 정의되어 있다.
// src/java/lang/ClassLoader.java public abstract class ClassLoader { /* * The parent class loader for delegation. */ private ClassLoader parent;
protected synchronized Class loadClass(String name, boolean resolve) throws ClassNotFoundException { // First, check if the class has already been loaded Class c = findLoadedClass(name); if (c == null) { try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClass0(name); } } catch (ClassNotFoundException e) { // If still not found, then call findClass in order // to find the class. c = findClass(name); } } if (resolve) { resolveClass(c); } return c; } .... }
위 코드를 보면 부모 클래스로더로부터 먼저 클래스 로딩을 요청하고, 그것이 실패할 경우(즉, catch 블럭)에 비로소 직접 클래스를 로딩한다. 여기서 그렇다면 부모 클래스는 어떻게 결정되는 지 살펴보자. 먼저 JDK 1.3의 ClassLoader 클래스는 다음과 같은 두 개의 생성자를 갖고 있다.
이 두 코드를 살펴보면, 부모 클래스로더를 지정하지 않을 경우, 시스템 클래스로더를 부모 클래스로더로 지정하는 것을 알 수 있다. 따라서 커스텀 클래스로더에서 부모 클래스로더를 지정하기 위해서는 다음과 같이 하면 된다.
public class JarFileClassLoader extends ClassLoader { public JarFileClassLoader () { super(JarFileClassLoader.class.getClassLoader()); // 다른 초기화 관련 사항 } .... public Class findClass(String name) { // 지정한 클래스를 찾는다. } }
모든 클래스는 그 클래스에 해당하는 Class 인스턴스를 갖고 있다. 그 Class 인스턴스의 getClassLoader() 메소드를 통해서 그 클래스를 로딩한 클래스로더를 구할 수 있다. 즉, 위 코드는 JarFileClassLoader 클래스를 로딩한 클래스로더를 JarFileClassLoader 클래스로더의 부모 클래스로더로 지정하는 것이다. (실제로 커스텀 클래스로더를 구현하는 것에 대한 내용은 이 Article의 시리중에서 3번째에 알아보기로 한다).
JVM에서 부모 클래스로더를 갖지 않은 유일한 클래스로더는 부트스트랩 클래스로더이다. 부트스트랩 클래스로더는 자바 런타임 라이브러리에 있는 클래스를 로딩하는 역할을 맡고 있으며, 항상 클래스로더 체인의 가장 첫번째에 해당한다. 기본적으로 자바 런타임 라이브러리에 있는 모든 클래스는 JRE/lib 디렉토리에 있는 rt.jar 파일에 포함되어 있다.
결론
이번 Article에서는 자바에서 클래스 로딩이 동적으로 이루어지면, 클래스 로딩 방식에서는 로드타임 로딩과 런타임 로딩의 두 가지 방식이 있다는 것을 배웠다. 그리고 자바 2에서의 클래스로딩이 클래스로더 딜리게이션 모델(Classloader Delegation Model)을 통해서 이루어진다는 점과 이 모델에 자바 1.x에서의 클래스로딩 메커니즘과 어떻게 다르며, 어떤 장점이 있는 지 알아보았다. 다음 Article에서는 자바 2에서 기본적으로 제공하는 클래스로더에 대해서 알아보기로 한다.
// src/java/lang/ClassLoader.java public abstract class ClassLoader { /* * The parent class loader for delegation. */ private ClassLoader parent;
protected synchronized Class loadClass(String name, boolean resolve) throws ClassNotFoundException { // First, check if the class has already been loaded Class c = findLoadedClass(name); if (c == null) { try { if (parent != null) { c = parent.loadClass(name, false); } else { c = findBootstrapClass0(name); } } catch (ClassNotFoundException e) { // If still not found, then call findClass in order // to find the class. c = findClass(name); } } if (resolve) { resolveClass(c); } return c; } .... }
코드 5를보면, 부모클래스로더를지정하지않을경우에는시스템클래스로더를부모클래스로더로지정하고있습니다. 커스텀클래스로더에서부모클래스로더를지정하기위해서는코드 6과같이하면됩니다.
public class JarFileClassLoader extends ClassLoader { public JarFileClassLoader () { super(JarFileClassLoader.class.getClassLoader()); // 다른초기화관련사항 } .... public Class findClass(String name) { // 지정한클래스를찾는다. } }
코드 6.
모든클래스는그클래스에해당하는 Class 인스턴스를가지고있습니다. 그 Class 인스턴스의 getClassLoader() 메소드를통해서그클래스를로딩한클래스로더를구할수있습니다. 코드 6에서는 JarFileClassLoader 클래스를로딩한클래스로더를 JarFileClassLoader 클래스로더의부모클래스로더로지정하는것입니다. JVM에서부모클래스로더를갖지않은유일한클래스로더는부트스트랩클래스로더로서부트스트랩클래스로더는자바런타임라이브러리에있는클래스를로딩하는역할을맡고있으며, 항상클래스로더체인의첫번째에해당합니다. Java에서는같은클래스일지라도다른클래스로더에의해서로딩되었다면다른클래스로구분이됩니다.
Example
public class ToolsJarLoader extends URLClassLoader {
private static ToolsJarLoader mInstance;
public static ToolsJarLoader getInstance() {
if(mInstance == null) {
mInstance = new ToolsJarLoader(((URLClassLoader)ClassLoader.getSystemClassLoader()).getURLs());
}
return mInstance;
}
public ToolsJarLoader(URL[] urls) {
super(urls);
}
@Override
public void addURL(URL url) {
super.addURL(url);
}
public boolean isLoaded(URL url) {
URL[] urls = getURLs();
for(URL temp : urls) {
if(temp.equals(url)) {
return true;
}
}
return false;
}
}
코드 7.
코드 7은원하는클래스및 jar를런타임에동적으로로드하기위한클래스로더이다. addURL을통해 jar 및클래스를로딩한다.
URL jarUrl = new File(toolsJarPath).toURI().toURL();


 구글 검색 엔진
구글 검색 엔진