고급 DAO 프로그래밍 (Transaction)
DB 2016. 12. 20. 17:35DAO 구현 기술
Level: Advanced |
소프트웨어 엔지니어
2003년 10월 7일
J2EE 개발자들은 Data Access Object (DAO) 디자인 패턴을 사용하여 저수준의 데이터 액세스 로직과 고급 비즈니스 로직을 분리한다. DAO 패턴을 구현하는 것은 단순히 데이터 액세스 코드를 작성하는 것 이상이다.
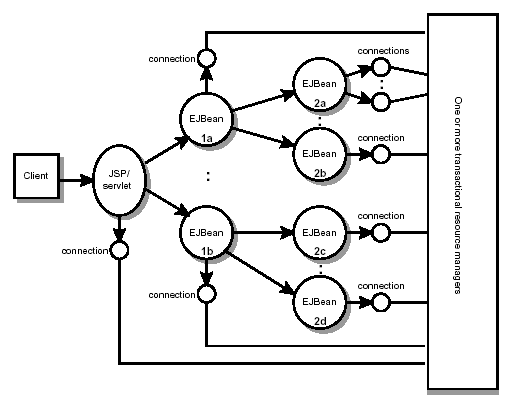
지난 18개월 동안, 재능 있는 소프트웨어 엔지니어들과 함께 웹 기반의 공급체인 관리 애플리케이션을 구현했다. 우리가 만든 애플리케이션은 선적 상황, 공급 체인 메트릭스, 창고 재고, 운송장, 프로젝트 관리 데이터, 사용자 프로파일 등의 광범위한 데이터에 접근했다. JDBC API를 사용하여 회사의 다양한 데이터베이스 플랫폼에 연결했고 이 애플리케이션에 DAO 디자인 패턴을 적용했다.
그림 1은 애플리케이션과 데이터 소스의 관계이다:

DAO의 기초
DAO 패턴은 표준 J2EE 디자인 패턴들 중 하나이다. 이 패턴을 사용하여 저수준 데이터 액세스와 고급 비지니스 로직을 분리한다. 전형적인 DAO 구현에는 다음과 같은 요소들이 있다:
- DAO 팩토리 클래스
- DAO 인터페이스
- DAO 인터페이스를 구현하는 구체적 클래스
- 데이터 전송 객체들(밸류(value) 객체)
구체적인 DAO 클래스에는 특정 데이터 소스로 부터 데이터에 액세스하는데 쓰이는 로직이 포함되어 있다.
트랜잭션 경계설정(demarcation)
DAO는 트랜잭션 객체들이라는 것을 반드시 기억해야 한다. DAO에 의해 수행되는 각각의 작동(데이터 구현, 업데이트, 삭제)은 트랜잭션과 관련있다. 따라서 트랜잭션 경계설정(demarcation) 개념은 매우 중요하다.
트랜잭션 경계설정은 트랜잭션 영역들이 정의 되는 방식이다. J2EE 스팩은 두 가지 모델의 트랜잭션 경계설정을 설명하고 있다. (표 1):
표 1. 트랜잭션 경계설정
| 선언적(Declarative) 트랜잭션 경계설정 | 프로그램에 입각한(Programmatic) 트랜잭션 경계설정 |
| 프로그래머는 EJB 전개 디스크립터를 사용하여 트랜잭션 애트리뷰트를 선언한다. | 프로그래머는 트랜잭션 로직을 코딩해야한다. |
| 런타임 환경(EJB 컨테이너)은 트랜잭션을 자동으로 관리하기 위해 이 애트리뷰트를 사용한다. | 이 애플리케이션은 API를 통해 트랜잭션을 제어한다. |
프로그램에 입각한(Programmatic) 트랜잭션 경계설정을 중점적으로 설명하겠다.
디자인 고려사항
앞서 언급했지만, DAO는 트랜잭션 객체이다. 전형적인 DAO는 구현, 업데이트, 삭제 같은 트랜잭션 작동을 수행한다. DAO를 설계할 때 다음 사항들을 점검한다:
- 트랜잭션은 어떻게 시작하는가?
- 트랜잭션은 어떻게 끝나는가?
- 트랜잭션 시작을 담당하는 객체는 무엇인가?
- 트랜잭션 종료를 담당하는 객체는 무엇인가?
- DAO가 트랜잭션의 시작과 종료를 담당해야 하는가?
- 이 애플리케이션이 다중의 DAO를 통해 데이터에 액세스해야 하는가?
- 트랜잭션에 포함될 DAO의 수는?
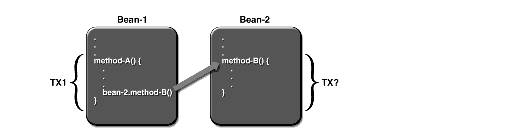
- 하나의 DAO가 또 DAO에 대한 메소드를 호출할 수 있는가?
이러한 질문들에 대한 답을 알고있다면 자신의 DAO에 가장 잘 맞는 트랜잭션 경계설정 전략을 선택하는데 도움이 된다. DAO에는 두 가지 주요한 트랜잭션 경계설정 전략이 있다. 하나는 DAO가 트랜잭션의 경계를 설정하도록 하는 것이다. 또 다른 방법은 트랜잭션 경계설정을 DAO의 메소드를 호출하는 객체에 맡기는 것이다. 전자를 선택한다면 DAO 클래스 안에 트랜잭션 코드를 임베딩해야 한다. 후자의 방법을 선택한다면 트랜잭션 경계설정 코드는 DAO 클래스의 외부에 있게 될 것이다. 코드 예제를 보고 이 두 가지 방법을 자세히 보도록 하자.
Listing 1- DAO와 두 개의 데이터 작동;구현 및 업데이트:
|
Listing 2은 간단한 트랜잭션이다. 트랜잭션 경계설정 코드는 DAO 클래스 외부에 있다. 이 예제에서 콜러(caller)가 다중의 DAO 작동들을 이 트랜잭션 내에서 결합하는 방법을 주목해보자.
Listing 2. 콜러(Caller)에 의해 관리되는 트랜잭션
|
이 트랜잭션 경계설정 전략은 단일 트랜잭션에서 다중의 DAO에 액세스 해야하는 애플리케이션에 특별히 어울린다.
JDBC API 또는 Java Transaction API (JTA)를 사용하여 트랜잭션 경계설정을 구현할 수 있다. JDBC 트랜잭션 경계설정은 JTA 보다 단순하다. 하지만 JTA는 보다 유연하다.
JDBC를 이용한 트랜잭션 경계설정
JDBC 트랜잭션은 Connection 객체를 사용하여 제어된다. JDBC Connection 인터페이스(java.sql.Connection)는 두 개의 트랜잭션 모드를 제공한다. (auto-commit과 manual commit). java.sql.Connection은 트랜잭션 제어에 다음의 메소드를 제공한다:
public void setAutoCommit(boolean)public boolean getAutoCommit()public void commit()public void rollback()
Listing 3은 JDBC API를 사용하여 트랜잭션의 경계설정을 하는 방법이다:
Listing 3. JDBC API를 이용한 트랜잭션 경계설정
|
JDBC 트랜잭션 경계설정을 이용하면 여러 개의 SQL 문장을 하나의 트랜잭션으로 결합할 수 있다. JDBC 트랜잭션의 단점 중 하나는 트랜잭션 범위가 하나의 데이터베이스 연결로 제한되어 있다는 점이다. JDBC 트랜잭션은 다중 데이터베이스로 확장할 수 없다. 다음에는 JTA를 사용한 트랜잭션 경계설정이다.
JTA 개요
Java Transaction API (JTA)와 Java Transaction Service (JTS)는 J2EE 플랫폼에 분산 트랜잭션 서비스를 제공한다. 분산 트랜잭션에는 트랜잭션 매니저와 한 개 이상의 리소스 매니저가 포함된다. 리소스 매니저는 일종의 영속 데이터스토어이다. 트랜잭션 매니저는 모든 트랜잭션 참여자들 간 통신을 조정하는 역할을 담당한다. 트랜잭션 매니저와 리소스 매니저 관계는 다음과 같다. (그림 2):
JTA 트랜잭션은 JDBC 트랜잭션 보다 강력하다. JDBC 트랜잭션이 하나의 데이터베이스 연결로 제한되어 있다면 JTA 트랜잭션은 다중의 참여자들을 가질 수 있다. 다음의 자바 플랫폼 컴포넌트 중 어떤 것이든지 JTA 트랜잭션에 참여할 수 있다:
- JDBC 커넥션
- JDO
PersistenceManager객체 - JMS 큐
- JMS 토픽
- Enterprise JavaBeans
- J2EE Connector Architecture 스팩에 호환하는 리소스 어댑터
JTA를 이용한 트랜잭션 경계설정
JTA로 트랜잭션 경계를 설정하기 위해 애플리케이션은 javax.transaction.UserTransaction 인터페이스에 대한 메소드를 호출한다. Listing 4는 UserTransaction 객체의 전형적인 JNDI이다:
Listing 4. UserTransaction 객체의 JNDI
|
애플리케이션 UserTransaction 객체에 대한 레퍼런스를 가진 후에 트랜잭션을 시작한다. (Listing 5):
|
애플리케이션이 commit()을 호출하면, 트랜잭션 매니저는 2 단계 커밋(two-phase commit) 프로토콜을 사용하여 트랜잭션을 종료한다.
트랜잭션 제어용 JTA 메소드javax.transaction.UserTransaction 인터페이스는 다음의 트랜잭션 제어 메소드를 제공한다:
public void begin()public void commit()public void rollback()public int getStatus()public void setRollbackOnly()public void setTransactionTimeout(int)
JTA 트랜잭션을 시작할 때 이 애플리케이션은 begin()을 호출한다. 트랜잭션을 끝내려면 commit() 또는 rollback()을 호출한다. (참고자료).
JTA와 JDBC 사용하기
개발자들은 DAO 클래스에서 저수준 데이터 작동에 JDBC를 사용하곤 한다. JTA를 이용하여 트랜잭션의 경계를 설정하려면 javax.sql.XADataSource, javax.sql.XAConnection, javax.sql.XAResource인터페이스를 구현하는 JDBC 드라이버가 필요하다. 이러한 인터페이스를 구현하는 드라이버는 JTA 트랜잭션에 참여할 수 있게된다. XADataSource 객체는 XAConnection 객체용 팩토리이다. XAConnection는 JTA 트랜잭션에 참여하는 JDBC 커넥션이다.
애플리케이션 서버의 관리 툴을 사용하여 XADataSource를 설정해야 한다. 애플리케이션 서버 문서와 JDBC 드라이버 문서를 참조하라.
J2EE 애플리케이션은 JNDI를 사용하여 데이터 소스를 검색한다. 일단 애플리케이션이 데이터 소스 객체에 대한 레퍼런스를 갖게 되면 이것은 javax.sql.DataSource.getConnection()을 호출하여 데이터베이스로의 커넥션을 획득하게 된다.
XA 커넥션은 비 XA 커넥션과는 다르다. XA 커넥션은 JTA 트랜잭션에 참여하고 있다는 것을 언제나 기억하라. XA 커넥션은 JDBC의 자동 커밋 기능을 지원하지 않는다. 또한 이 애플리케이션은 XA 커넥션 상에서 java.sql.Connection.commit() 또는 java.sql.Connection.rollback()을 호출하지 않는다. 대신 UserTransaction.begin(), UserTransaction.commit(), UserTransaction.rollback()을 사용한다.
최상의 접근방법 선택하기
JDBC와 JTA를 이용한 트랜잭션 경계설정에 대해 이야기했다. 각 접근방식 대로 장점이 있기 때문에 자신의 애플리케이션에 가장 알맞는 것을 선택해야 한다.
최근 많은 프로젝트에서 우리팀은 JDBC API를 사용하여 DAO 클래스를 구현했다. 이 DAO 클래스는 다음과 같이 요약된다:
- 트랜잭션 경계설정 코드는 DAO 클래스 안으로 임베딩된다.
- DAO 클래스는 트랜잭션 경계설정에 JDBC API를 사용한다.
- 콜러가 트랜잭션 경계를 설정할 방법은 없다.
- 트랜잭션 범위는 하나의 JDBC Connection으로 제한된다.
JDBC 트랜잭션이 복잡한 엔터프라이즈 애플리케이션에 언제나 적합한 것은 아니다. 트랜잭션이 다중 DAO 또는 다중 데이터페이스로 확장한다면 다음과 같은 구현 전략이 보다 적합하다:
- 트랜잭션은 JTA로 경계 설정된다.
- 트랜잭션 경계설정 코드는 DAO와 분리되어 있다.
- 콜러가 트랜잭션 경계설정을 담당하고 있다.
- DAO는 글로벌 트랜잭션에 참여한다.
JDBC 접근방법은 간단함이 매력이다. JTA 접근방법은 유연성이 무기이다. 애플리케이션에 따라 구현 방법을 선택해야 한다.
로깅과 DAO
잘 구현된 DAO 클래스는 런타임 작동에 대한 세부사항을 파악하기 위해 로깅(logging)을 사용한다. 예외, 설정 정보, 커넥션 상태, JDBC 드라이버 메타데이터, 쿼리 매개변수 중 어떤 것이든 선택하여 기록해야 한다. 기록은 모든 개발 단계에 유용하다.
로깅 라이브러리 선택하기
많은 개발자들은 단순한 형식의 로깅을 사용한다: System.out.println과 System.err.println. Println 문장은 빠르고 편리하지만 완벽한 로깅 시스템은 제공하지 않는다. 표 2는 자바 플랫폼을 위한 로깅 라이브러리이다:
표 2.자바 플랫폼을 위한 로깅 라이브러리
| 로깅 라이브러리 | 오픈소스여부 | URL |
| java.util.logging | No | http://java.sun.com/j2se/ |
| Jakarta Log4j | Yes | http://jakarta.apache.org/log4j/ |
| Jakarta Commons Logging | Yes | http://jakarta.apache.org/commons/logging.html |
java.util.logging은 J2SE 1.4 플랫폼을 위한 표준 API이다. Jakarta Log4j가 더 많은 기능성과 유연성을 제공한다는 것에는 많은 개발자들이 동의하고 있다. java.util.logging의 이점 중 하나는 J2SE 1.3과 J2SE 1.4 플랫폼을 지원한다는 것이다.
Jakarta Commons Logging은 java.util.logging 과의 연결 또는 Jakarta Log4j에 사용될 수 있다. Commons Logging은 로깅 추상 레이어로서 애플리케이션을 기저의 로깅 구현에서 고립시킬 수 있다. Commons Logging을 사용하여 설정 파일을 변경하여 기저의 로깅 구현을 바꿀 수 있다. Commons Logging은 Jakarta Struts 1.1과 Jakarta HttpClient 2.0에 사용된다.
로깅 예제
Listing 7은 DAO 클래스에서 Jakarta Commons Logging을 사용하는 방법이다:
Listing 7. Jakarta Commons Logging
|
로깅은 미션 수행에 중요한 애플리케이션의 중요한 일부이다. DAO에서 오류가 생기면 무엇이 잘못되었는지를 이해할 수 있게끔 최고의 정보를 로그가 제공한다. 로깅과 DAO를 결합하면 디버깅과 문제해결은 확실하다.
DAO 패턴을 구현할 때 다음 사항을 자문해보라:
- DAO의 퍼블릭 인터페이스의 메소드들이 검사된 예외를 던지는가?
- 그렇다면 어떤 예외들인가?
- DAO 구현 클래스에서 예외는 어떻게 처리되는가?
DAO 패턴을 작업하는 과정에서 우리 팀은 예외 핸들링에 대한 가이드라인을 개발했다:
- DAO 메소드는 의미있는 예외를 던져야한다.
- DAO 메소드는
java.lang.Exception을 던져서는 안된다.java.lang.Exception은 너무 일반적이다. 근본 문제에 대한 정보를 제공하지 않을 것이다. - DAO 메소드는
java.sql.SQLException메소드를 던져서는 안된다. SQLException은 저급 JDBC 예외이다. DAO는 JDBC를 나머지 애플리케이션에 노출하는 것이 아니라 JDBC를 캡슐화 해야한다. - DAO 인터페이스의 메소드들은 콜러가 예외를 처리할 수 있다고 합리적으로 판단될 때 에만 검사된예외를 던져야 한다. 콜러가 예외를 핸들할 수 없다면 검사되지 않은(런타임) 예외를 던질 것을 고려하라.
- 데이터 액세스 코드가 예외를 잡으면 이를 무시하지 말아라. 잡힌 예외를 무시하는 DAO는 문제해결에 애를 먹는다.
- 연쇄 예외를 사용하여 저급 예외를 고급 예외로 트랜슬레이팅 한다.
- 표준 DAO 예외 클래스를 정의하라. Spring Framework (참고자료)은 사전 정의된 DAO 예외 클래스를 제공한다.
구현 예제: MovieDAOMovieDAO는 이 글에 논의된 모든 기술을 보여주는 DAO이다: 트랜잭션 경계설정, 로깅, 예외 핸들링. 코드는 세 개의 패키지로 나뉜다. (참고자료):
daoexamples.exceptiondaoexamples.moviedaoexamples.moviedemo
DAO 패턴 구현은 클래스와 인터페이스로 구성된다:
daoexamples.movie.MovieDAOFactorydaoexamples.movie.MovieDAOdaoexamples.movie.MovieDAOImpldaoexamples.movie.MovieDAOImplJTAdaoexamples.movie.Moviedaoexamples.movie.MovieImpldaoexamples.movie.MovieNotFoundExceptiondaoexamples.movie.MovieUtil
MovieDAO 인터페이스는 DAO의 데이터 작동을 정의한다. 이 인터페이스는 다섯 개의 메소드를 갖고 있다:
public Movie findMovieById(String id)public java.util.Collection findMoviesByYear(String year)public void deleteMovie(String id)public Movie createMovie(String rating, String year, String, title)public void updateMovie(String id, String rating, String year, String title)
daoexamples.movie 패키지에는 두 개의 MovieDAO 인터페이스 구현이 포함되어 있다. 각 구현은 트랜잭션 경계설정에 다른 접근방식을 사용한다. (표 3):
표 3. MovieDAO 구현
| MovieDAOImpl | MovieDAOImplJTA | |
| MovieDAO 인퍼페이스 구현 | Yes | Yes |
| JNDI를 통한 DataSourc 획득 | Yes | Yes |
| DataSource에서 java.sql.Connection 객체 획득 | Yes | Yes |
| DAO가 트랜잭션을 내부적으로 경계설정하는가? | Yes | No |
| JDBC 트랜잭션 사용 | Yes | No |
| XA DataSource 사용 | No | Yes |
| JTA 트랜잭션 참여 | No | Yes |
MovieDAO 데모 애플리케이션
이 데모 애플리케이션 이름은 daoexamples.moviedemo.DemoServlet 이다. DemoServlet은 Movie DAO를 사용하여 무비 데이터를 쿼리 및 업데이트 한다.
Listing 8은 싱글 트랜잭션 에서의 JTA-aware MovieDAO와 Java Message Service의 결합 방법이다.
Listing 8. MovieDAO와 JMS 코드 결합
|
데모를 실행하려면 XA 데이터소스와 비 XA 데이터소스를 애플리케이션 서버에 설정해야 한다. 그런다음 daoexamples.ear 파일을 전개한다.
출처 -http://lbass.tistory.com/entry/%EB%B3%B8%EB%AC%B8%EC%8A%A4%ED%81%AC%EB%9E%A9-%EA%B3%A0%EA%B8%89-DAO-%ED%94%84%EB%A1%9C%EA%B7%B8%EB%9E%98%EB%B0%8D
'DB' 카테고리의 다른 글
| 트랜잭션 서비스 사용 (0) | 2016.12.20 |
|---|---|
| 트랜잭션(Transaction)과 2PC(two-phase commit) (0) | 2016.12.20 |
| OLTP / OLAP (1) | 2016.11.05 |
| 다차원 모델링(1/2) (0) | 2016.11.05 |
| DW, DM, OLAP의 이해 (2) | 2016.11.05 |