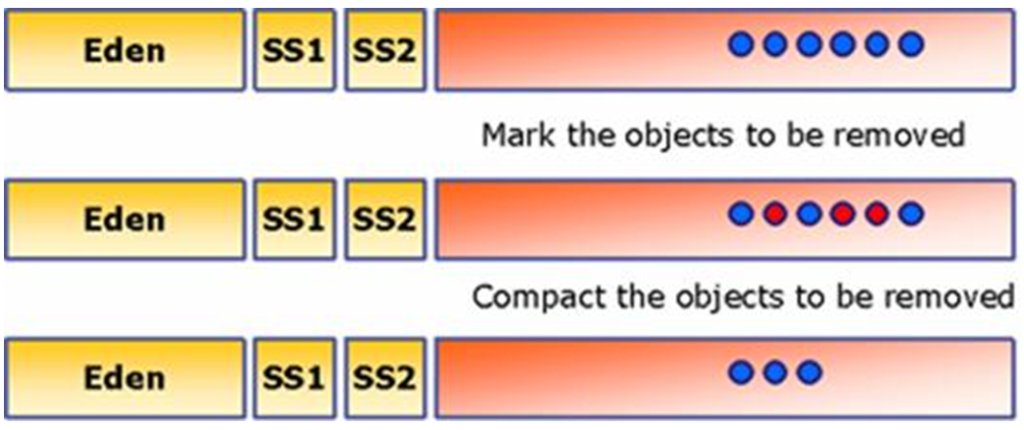
자바 JVM 정리(Java Virtual Machine)
Language/JAVA 2016. 8. 5. 14:50자바 JVM 정리(Java Virtual Machine)
Java 언어는 기본적으로 JVM(Java Virtual Machine) 위에서 실행되도록 고안된 언어입니다. 이번엔 JVM의 구조를 살펴보고 하나씩 점검해 보는 포스팅입니다.
1. Java Virtual Machine
A Java virtual machine (JVM) is an abstract computing machine. There are three notions of the JVM: specification, implementation, and instance. The specification is a book that formally describes what is required of a JVM implementation. Having a single specification ensures all implementations are interoperable. A JVM implementation is a computer program that meets the requirements of the JVM specification in a compliant and preferably performant manner. An instance of the JVM is a process that executes a computer program compiled into Java bytecode.
Wikipedia - Java virtual machine
위키피디아에서 소개된 JVM에 대한 설명중 일부입니다. 간략하게 풀어보자면,
JVM이란 추상적인 컴퓨팅 머신입니다. 그리고 JVM에는 3가지 개념이 있습니다. 이것은 명세(스펙), 구현, 그리고 인스턴스입니다. 명세는 책입니다. JVM 구현에 무엇이 요구되는지 공식적으로 설명 되어 있습니다. 하나의 명세를 가지는 것은 모든 구현의 상호 운영을 보장합니다. JVM 구현은 JVM 명세의 요구에 맞춘 컴퓨터 프로그램입니다. JVM의 인스턴스는 자바 바이트코드로 컴파일된 컴퓨터 프로그램을 실행하는 프로세스입니다.
2. JVM Diagram
실제로 JVM의 구조는 어떻게 되었는지 다이어그램으로 확인해 봅시다.
╋━━━━━━╋
class files ------▶┃Class Loader┃
╋━━━━━━╋
↕
╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╋
┃JVM Memory(Runtime Data Areas) ┃
┃╋━━━━━━╋ ╋━━╋ ╋━━━━━━━━━━╋ ╋━━━━━━╋ ╋━━━━━━━━━━╋┃
┃┃Method Area ┃ ┃Heap┃ ┃JVM Language Stacks ┃ ┃PC Registers┃ ┃Native Method Stacks┃┃
┃╋━━━━━━╋ ╋━━╋ ╋━━━━━━━━━━╋ ╋━━━━━━╋ ╋━━━━━━━━━━╋┃
╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╋
↕ ↕
╋━━━━━━━━╋ ╋━━━━━━━━━━━━╋ ╋━━━━━━━━━━━━╋
┃Execution Engine┃ ↔ ┃Native Method Interface ┃ ↔ ┃Native Method Libraries ┃
╋━━━━━━━━╋ ╋━━━━━━━━━━━━╋ ╋━━━━━━━━━━━━╋
다이어그램상으로 위에서 아래로 내려가는 과정을 수행한다고 보면 됩니다. class 파일의 정보를 Class Loader를 사용해 JVM Memory 공간으로 옮기고 이것을 Execution Engine으로 실행하는 구조입니다.
그리고 새로운 단어들이 많이 등장합니다. 하나씩 살펴봅시다.
3. Class Loader
Class Loader(이하 "클래스 로더")는 클래스 파일 포맷(.class)을 준수하는 어떠한 것이라도 인지하고 적재할 수 있도록 구현해야 합니다. 그리고 런타임(Runtime)시에 클래스를 적재하고 바른 바이트코드로 작성되었는지 검사합니다.
또한 일반적으로 클래스 로더는 두 종류로 나뉩니다. 하나는 bootstrap class loader이고 다른 하나는 user define class loader입니다. 모든 JVM 구현은 반드시 bootstrap class loader가 있어야 합니다. 그리고 JVM 명세에서 클래스 로더가 클래스를 찾는 방법을 지정하지 않습니다.
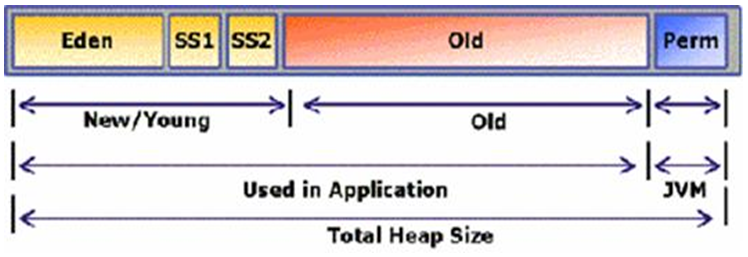
4. JVM Memory(Runtime Data Areas)
JVM Memory는 Runtime Data Areas라고도 불립니다. 해당 공간에는 Method Area, Heap, JVM Language Stacks, PC Registers, Native Method Stacks 등으로 구성 되어 있습니다.
이 공간은 클래스 로더에 의해 데이터가 적재되는 공간입니다.
4.1. Method Area
Method Area(이하 "메소드 지역")은 Type(class, inteface) 데이터들을 가지고 있습니다. 다이어그램으로 보면 아래와 같습니다.
╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╋ ┃Method Area ┃ ┃╋━━━━━━━━━━━━━━━━━━━━━━━━━━╋ ┃ ┃┃class data(Field, Method, Runtime Constant Pool...) ┃…┃ ┃╋━━━━━━━━━━━━━━━━━━━━━━━━━━╋ ┃ ╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╋
인스턴스 생성을 위한 필요 정보(필드, 메소드, 생성자...)를 적재한 공간입니다.
또한 각 Type 데이터에는 Runtime Constant Pool이라는 것을 가집니다. 이 곳은 심볼 테이블(symbol table)과 유사한 구조로 되어 있습니다. 상수 풀에는 해당 Type의 메소드, 필드, 문자열 상수등의 레퍼런스를 가지고 있습니다. 실제 물리적 메모리 위치를 참조할 때 사용합니다. 그리고 종종 바이트 코드를 메모리에 전부 올리기엔 크기 때문에 바이트 코드를 참조할 레퍼런스만 상수 풀에 저장하고 추후에 해당 값을 참조해서 실행할 바이트 코드를 찾아 메모리에 적재하게 하는 경우도 있습니다. 또한, 상수 풀을 사용함으로 동적 로딩(dynamic loading)이 가능합니다.
4.2. Heap
╋━━━━━━━━━━━━━━━━━╋ ┃Heap ┃ ┃╋━━━╋ ╋━━━╋ ╋━━━╋ ┃ ┃┃object┃ ┃object┃ ┃object┃…┃ ┃╋━━━╋ ╋━━━╋ ╋━━━╋ ┃ ╋━━━━━━━━━━━━━━━━━╋
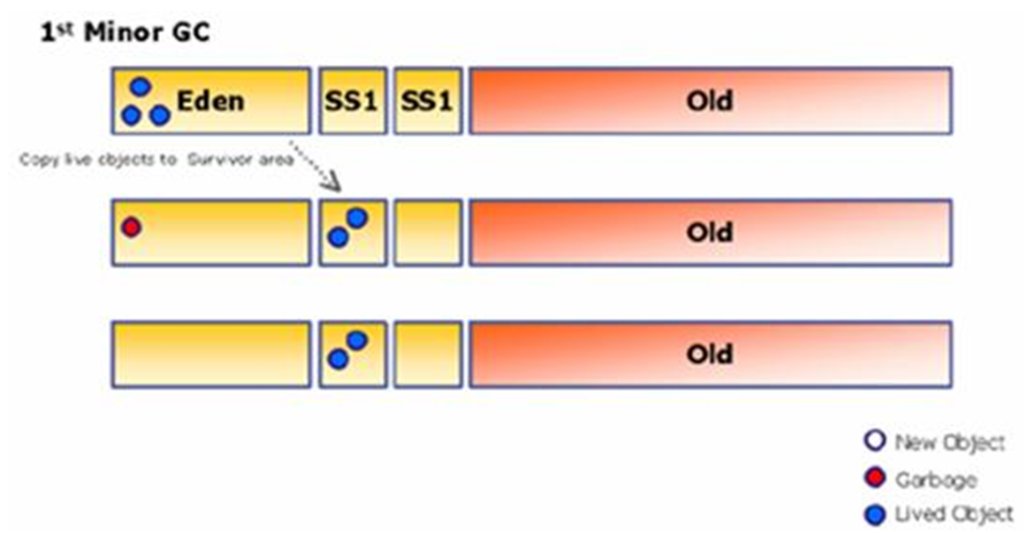
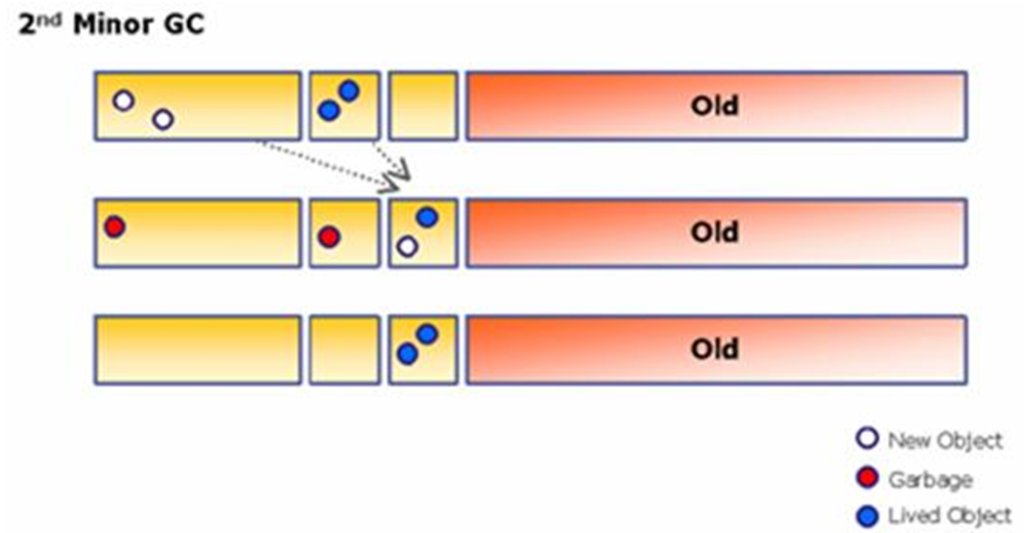
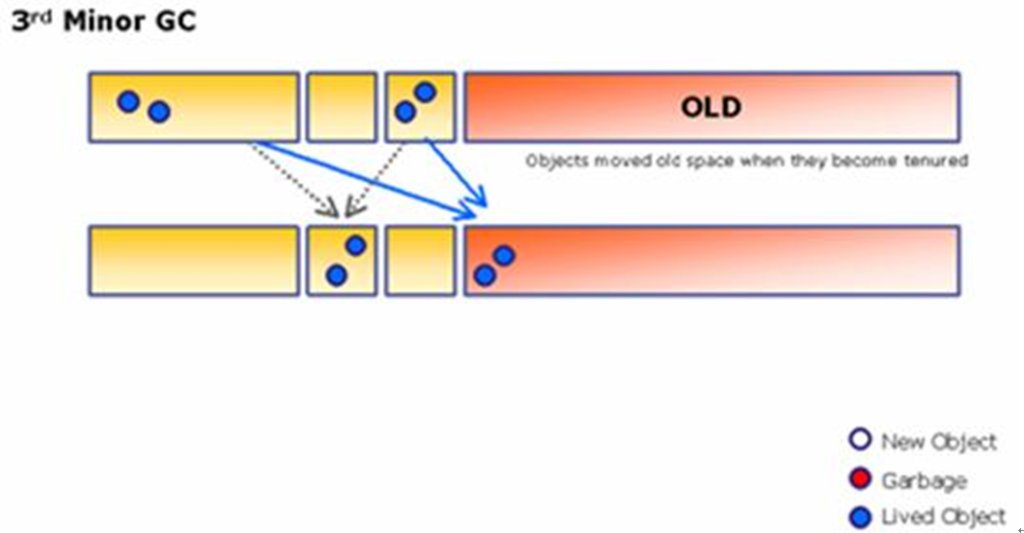
Heap(이하 "힙")은 객체들이 적재되는 공간입니다. 메소드 지역에서 참조한 값을 바탕으로 새로운 객체를 생성하면 이곳에 적재됩니다.
4.3. JVM Language Stacks
JVM Language Stacks(이하 "JVM 스택")은 아래의 다이어그램을 참조하면 됩니다. 추후에 기술할 PC Registers, Native Method Stacks도 이 다이어그램을 참조합니다.
╋━━━━━━━━━━╋ ╋━━━━━━━━━━╋ ╋━━━━━━━━━━╋
┃Thread ┃ ┃Thread ┃ ┃Thread ┃
╋━━━━━━━━━━╋ ╋━━━━━━━━━━╋ ╋━━━━━━━━━━╋
┃JVM Language Stacks ┃ ┃JVM Language Stacks ┃ ┃JVM Language Stacks ┃
┃PC Registers ┃ ┃PC Registers ┃ ┃PC Registers ┃
┃Native Method Stacks┃ ┃Native Method Stacks┃ ┃Native Method Stacks┃
╋━━━━━━━━━━╋ ╋━━━━━━━━━━╋ ╋━━━━━━━━━━╋
↕ ↕ ↕
╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╋
┃Heap ┃
╋━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╋
메소드 프레임(method frame)들이 JVM 스택에 하나씩 쌓이게 됩니다. 메소드 프레임은 간단하게 메소드라고 생각해도 됩니다. 스택 자료구조 형식이기 때문에 스택의 맨위에서부터 차례대로 메소드를 실행합니다. 또한 하나의 힙을 모든 스레드가 공유합니다. 하지만 각 스레드는 자신들만의 고유 JVM 스택을 가지고 있습니다.
4.4. PC Registers
PC는 Program Counter의 축약어입니다. 따라서 원래는 Program Counter Registers가 됩니다. 해당 영역은 현재 실행하고 있는 부분의 주소(adress)를 가지고 있습니다. 일반적으로 PC의 값은 현재 명령이 끝난 뒤에 값을 증가시킵니다. 그리고 해당하는 값의 명령을 실행하게 됩니다. 즉, 실행될 명령의 주소를 가지고 있습니다.
4.5. Native Method Stacks
일반적으로 JVM은 네이티브 방식을 지원합니다. 따라서 스레드에서 네이티브 방식의 메소드가 실행되는 경우 Native Method Stacks(이하 "네이티브 스택")에 쌓입니다. 일반적인 메소드를 실행하는 경우 JVM 스택에 쌓이다가 해당 메소드 내부에 네이티브 방식을 사용하는 메소드(예를 들면 C언어로 작성된 메소드)가 있다면 해당 메소드는 네이티브 스택에 쌓입니다.
5. Execution Engine
클래스 로더에 의해 JVM 메모리 공간에 적재된 바이트 코드를 Execution Engine(이하 "실행 엔진")을 이용해 실행합니다. 하지만 바이트 코드를 그대로 쓰는 것은 아니고 기계어로 변경한 뒤에 사용하게 됩니다. 해당 작업을 실행 엔진이 합니다. 그리고 바이트 코드를 기계어로 변경할 때엔 두 종류의 방식을 사용합니다. 각각 Interpreter와 JIT (Just-In-Time) compiler입니다.
Interpreter(이하 "인터프리터")는 우리가 알고 있는대로 방식대로 바이트 코드를 실행합니다. 하나의 명령어를 그때그때 해석해서 실행하게 되어 있습니다. JIT (Just-In-Time) compiler(이하 "JIT 컴파일러")는 인터프리터의 단점(성능,속도 등)을 보완하기 위해 도입되었습니다. 실행 엔진이 인터프리터를 이용해 명령어를 하나씩 실행하지만 JIT 컴파일러는 적정한 시간에 전체 바이트 코드를 네이티브 코드로 변경합니다. 이후에는 실행 엔진이 인터프리터 대신 네이티브로 컴파일된 코드를 실행합니다.
다만 JIT 컴파일러와 Java 컴파일러는 다른 것입니다. 다이어그램을 보면 이해가 빠를 것 같습니다.
Java Compiler JIT Compiler
↓ ↓
Java Source Code ------- Bytecode ------- Native Code
6. Native Method Interface(JNI)
Native Method Interface는 줄여서 JNI라고도 합니다. JNI는 JVM에 의해 실행되는 코드 중 네이티브로 실행하는 것이 있다면 해당 네이티브 코드를 호출하거나 호출 될 수 있도록 만든 일종의 프레임워크입니다.
7. Native Method Libraries
네이티브 메소드 실행에 필요한 라이브러리들을 뜻합니다.
8. Closing Remarks
간단하게 JVM에 대해 알아봤습니다. 혹시라도 잘못된 점이 있다면 말씀 부탁드립니다. :D
This work is licensed under a Attribution-NonCommercial-ShareAlike 4.0 International License.
All product names and trademarks are the property of their respective owners.
If there are copyright issues, please contact webmaster@jdm.kr or write reply.
출처 - http://jdm.kr/blog/188
'Language > JAVA' 카테고리의 다른 글
| Generic 메서드 (0) | 2017.10.20 |
|---|---|
| 자바 람다식(Lambda Expressions in Java) (0) | 2016.09.09 |
| GC (0) | 2016.08.05 |
| Do You Really Get Classloaders? (0) | 2016.08.04 |
| JVM ClassLoader의 작동원리 (0) | 2016.08.04 |