|
|
etc 2017. 1. 19. 15:18

음수와 음수를 곱하면 양수가 된다는데, 그냥 그렇다고 외우기만 했을 뿐, 그 이유를 생각해 보지 못했다. 음수끼리 더하면 여전히 음수인데 왜 곱하면 양수가 될까? 생각해 보면, 곱이 양수가 되는 것은커녕 음수끼리 어떻게 곱할 수 있는지도 이해하기 어렵다. 음수와 음수의 곱은 도대체 무엇일까? 스탕달도 파스칼도 음수를 몰랐다음수를 이해할 수 있는 쉬운 방법 가운데 하나는 아마도 금전적 이익을 양, 금전적 손실을 음으로 생각하는 방식일 것이다. 그런데 이 방식은 음수의 덧뺄셈을 설명하는 데는 좋지만, 곱셈이나 나눗셈을 다루는 데는 오히려 방해가 된다. 일례로, 소설 <적과 흑>으로 유명한 프랑스의 작가 스탕달(Stendhal, 1783-1842)은 자전적 소설에서, “1만 프랑의 빚과 5백 프랑의 빚을 곱하면 어떻게 5백만 프랑의 이익이 된다는 말인가?”라고 썼다. 음수와 음수의 곱이 양수인 것을 이해할 수 없다는 것이다. 당대의 지식인 가운데 한 명인 스탕달이 이 정도였으니, 음수에 음수를 곱해서 양수가 된다는 사실을 선뜻 받아들이지 못하는 사람들이 많았음을 짐작할 수 있다. 사실 무리수보다 음수가 더 늦게 발견됐으며, 음수의 연산을 보편적으로 받아들인 것이 무리수를 받아들인 것보다 나중인 것을 보면, 음수에 대한 거부감 내지는 공포감이 얼마나 심했는지 알 만하다. 희대의 천재로 손꼽히는 파스칼(Blaise Pascal, 1623-1662)조차 “놀랍게도, 아무것도 없는 상태에서 4개를 없애도 여전히 아무것도 없다는 사실을 이해하지 못하는 사람들이 있다”라고 자신의 책에 써놓을 정도였다.
양수와 음수의 모델 : 빚과 이익‘인간은 생각하는 갈대’라고 말한, ‘파스칼의 원리’를 발견한, 세계에서 처음으로 계산기를 만든 그 파스칼이 말이다. 음수 곱하기 음수가 양수라는 것은 문헌 상으로는 7세기 인도의 수학자 브라흐마굽타(Brahmagupta, 598–668)가 처음 밝혔다. 그렇지만, -3이 2보다 작은데 어떻게 -3의 제곱이 2의 제곱보다 크냐는 반론이 1000년도 더 지난 18세기 유럽에서 버젓이 상식처럼 통용되기도 하였으니, 음수에 음수를 곱한 것이 양수라는 사실에 대한 저항이 만만치 않았음을 알 수 있다. 오늘날처럼 경제나 날씨 등에서 음수의 개념이 일상화된 사회에서는 이러한 저항이 훨씬 덜한 편이지만, 여전히 음수를 처음 배우는 사람들이나 배운지 오랜 사람들에게는 낯설게 느껴지는 것도 사실이다.
스탕달의 예에서처럼 음수와 양수는 “빚”과 “이익”이라는 모델이 있다. 양수를 이익으로 생각하고 음수를 빚으로 생각하면, 이 모델은 양수의 덧셈과 뺄셈을 모두 설명할 수 있기 때문에 매우 좋은 모델이라 할 수 있다. 예를 들어 양수를 더하는 것은 이익이 늘어나는 것이고, 음수를 더하는 것은 이익이 줄어드는 것으로 생각하는 것이다. (이익이 0보다 작으면 빚으로 해석한다.) 인간은 한번 성공한 방법을 상황이 달라지더라도 적용하려는 경향이 있어서, 양수와 음수에 대한 연산을 할 때면 으레 빚과 이익을 생각하기 마련이다. 따라서 음수를 곱해서 양수라는 것을 빚과 빚을 곱해서 이익이라는 모델로 이해하려 시도하는 것도 자연스러운 현상이다. 왜 이 모델이 곱셈을 다룰 때는 잘 작동하지 않는 것일까? 빚에 빚을 곱하지 말라빚과 이익 모델을 써서 곱하기를 하려고 하면, 양수 곱하기 양수를 설명할 때부터 벌써 삐걱거리기 시작한다. 이 모델대로라면 ‘이익’에 ‘이익’을 곱하면 ‘이익’이라는 말인데 과연 그럴까? 100원짜리가 10개 있으면 1,000원(100 × 10 = 1,000)이므로 양수를 곱하면 양수라는 것은 얼핏 보면 그럴듯한 설명처럼 보인다. 그런데 잘 들여다보면 앞의 100의 단위는 ‘원’이지만, 뒤의 10은 단위가 ‘개수’임을 알 수 있다. 앞의 100원은 ‘이익’이라 불러도 괜찮지만, 뒤의 10개는 ‘이익’이라고 해석하기 곤란한 것이다. 따라서 빚에 빚을 곱하는 것은 고사하고, 이익에 이익을 곱한다는 것부터가 어불성설임을 알 수 있다. 빚과 이익모델 버릴까? 살릴까?‘이익의 곱은 이익’이라는 말은 틀린 ‘해석’이지만, 빚과 이익 모델로도 일단 양수 곱하기 양수가 양수라는 것을 설명하는 데는 별 문제가 없다. 한편, 이 모델로 음수 곱하기 양수가 음수라는 것도 설명할 수 있다. 예를 들어, 천 원을 빚진 사람이 열 명이면, 전체 빚이 만원임을 안다. 식으로 쓰면 아래와 같이 나타낼 수 있다. 이와 같이 음수 곱하기 양수와 양수 곱하기 음수가 음수라는 것을 설명할 수 있기 때문에 (역시 ‘빚 곱하기 이익이 빚’이라는 얘기는 아니다) 곱셈일 때도 완전히 폐기처분하기에 아까운 모델이기는 하다. 그렇지만 이 모델은 ‘음수 곱하기 음수’를 잘 설명할 수 없다는 것이 결정적 약점이다. 무엇보다 사람수나 개수에는 음수가 없기 때문이다. 물론 이해해 볼 방법이 없는 것은 아닌데, 조금 뒤로 미루자. 음수에 음수를 곱하면 양수이다 : 1.규칙성위의 곱셈표를 보자. 가로줄을 보면, 곱해지는 수를 하나씩 줄임에 따라 곱셈의 결과도 일정하게 변한다. 세로줄을 보면 곱하는 수를 하나씩 줄임에 따라 역시 일정하게, 첫 번째 세로줄은 2씩 줄고, 두 번째 줄은 1씩 줄고, 세 번째 줄은 0으로 변함이 없고, 네 번째 줄은 1씩 늘고, 다섯 번째 줄은 2씩 늘고 있다. 따라서 다음 가로줄을 만들면 아래와 같이 되어야 원래의 규칙이 유지된다. 이로부터 음수에 음수를 곱하면 양수가 되는 것이 매우 자연스럽다는 것을 알 수 있다. (원한다면두어 줄 더 계산해도 좋다.) 음수에 음수를 곱하면 양수이다 : 2.수직선음수를 다루는 기본적인 방식 가운데 하나는 수에 방향성을 부여하는 것이다. 양수와 음수를 양의 방향과 음의 방향의 두 가지로 생각하면 모델링 하기에 편리하다. 우리가 잘 알고 있는 수직선(數直線)이 바로 그것이다. 수직선에서 3과 -3은 기준점이 되는 원점에서 같은 거리(양)만큼 떨어져 있지만 방향이 서로 반대여서 다른 수가 된다. 사실 수직선 모델이 나온 이후에야 비로소 파스칼처럼 음수의 존재 자체를 부정하는 경향이 사라졌다. 이 수직선 모델에서 2에 3을 곱하는 것은 2를 3번 더하는 것이므로, 수직선의 0에서 양의 방향으로 2칸씩 3번 이동한 결과로 생각할 수 있다. 같은 방식으로 2에 -3을 곱하는 것은 반대 방향으로 2칸씩 3번, 즉 -2만큼 움직이는 과정을 3번 반복한 것으로 생각할 수 있다. 즉, -2에 3을 곱하는 것과 마찬가지로 생각할 수 있다. 이제(-2)×(-3)을 생각해 보면 -2의 반대 방향으로 3번 움직이는 것에 해당하고, 이것은 2를 3번 더한 것과 같아지므로,(-2)×(-3) = 6이 된다. 음수에 음수를 곱하면 양수이다 : 3.빚과 이익 모델빚과 이익 모델로도 음수의 곱을 설명할 수 있다. 양수만 더하고 빼던 것을, 음수도 더하고 빼는 것으로 확장하는 것이다. 음수를 더하는 것은 빚이 늘어난다, 이익이 줄어든다는 뜻으로 해석하고, 음수를 뺀다는 것은 빚이 줄어든다, 즉, 이익이 늘어난다는 뜻으로 해석하는 것이 합리적이다. 특히 a가 양수일 때,-a를 뺀다는 것은 a만큼의 빚(즉, -a)이 줄었다는 뜻이므로, a만큼의 이익이 늘어났다는 뜻이다. 즉,-(-a) = a인 것이다. 또한 빚과 이익 모델에서 a와 b가 양수일 때(-a) × b = -(a × b) = a × (-b)라는 것은 수긍할 수 있을 것이다. 음수의 곱셈이 기존의 셈법과 어울리려면 저 식이b가 음수일 때도 (혹은 0일 때도) 성립하는 것이 바람직할 것이다. 따라서 b가 음수일 때b = -c로 나타내면, c는 양수이고 (-a) × (-c) = a ×(-(-c)) = a × c여야만 한다.즉, 음수 곱하기 음수는 양수가 되는 것이 합리적이다. 음수에 음수를 곱하면 양수이다 : 4.수학적 증명음수와 음수의 곱이 양수임을 여러가지로 ‘설명’했지만, 엄밀한 증명이라고 하기는 어렵다. 예를 들어 -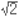 와 - 와 -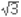 의 곱이 의 곱이 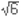 임을 위의 설명을 써서 보이기 힘든데, 번, 혹은 개 같은 것을 생각할 수 없기 때문이다. 엄밀한 증명을 위해서는 0이 덧셈의 항등원이라는 것과, 덧셈의 결합법칙, 덧셈과 곱셈 사이의 분배법칙을 이용해여 (-a) × (-b) = ab를 증명할 수 있다. 먼저 음수와 음수의 곱 가운데 가장 간단한 (-1) × (-1) = 1을 연습 삼아 풀어보자. 0 = 1 + (-1)임은 알고 있다. 양변에 -1을 곱하고 분배법칙을 적용하면, 아래와 같다. 임을 위의 설명을 써서 보이기 힘든데, 번, 혹은 개 같은 것을 생각할 수 없기 때문이다. 엄밀한 증명을 위해서는 0이 덧셈의 항등원이라는 것과, 덧셈의 결합법칙, 덧셈과 곱셈 사이의 분배법칙을 이용해여 (-a) × (-b) = ab를 증명할 수 있다. 먼저 음수와 음수의 곱 가운데 가장 간단한 (-1) × (-1) = 1을 연습 삼아 풀어보자. 0 = 1 + (-1)임은 알고 있다. 양변에 -1을 곱하고 분배법칙을 적용하면, 아래와 같다. 1 × (-1) = -1이므로 위의 식은 0=-1+(-1)×(-1) 이 된다. 이제 양변에 1을 더하면 결과가 나온다. 그럼, 이제 일반적인 음수와 음수의 곱에 대해서도 증명해 보겠다. 먼저 0 × b = 0 이라는 것을 증명한다. 0이 만약 3개 있다면 0 × 3 = 0 + 0 + 0 = 0 이니까 이런 것은 쉽다. 하지만 0에다 를 곱한 것도 이렇게 생각할 수 있을까? 0이 번 있다는 것은 상상할 수 없다. 그래서 증명을 하는 것이다. 0 × b = 0의 증명은 다음과 같다. a ×0 = 0인 것도 마찬가지로 똑같이 보일 수 있다. 이제 본격적으로(-a) × (-b) = ab를 증명하겠다. 그 증명은 아래와 같다. 이제 원하는 사실, (-a) × (-b) = ab의 증명이 끝났다.
관련링크 : [오늘의 과학] "-1 x -1 = 1 ?" 수학자 박부성님이 지식iN에 묻습니다.
관련링크 : 오늘의 과학 저자와의 질의응답 전체보기
출처 - http://navercast.naver.com/contents.nhn?rid=22&contents_id=106
etc 2017. 1. 19. 15:08

많은 사람들이 나눗셈을 할 때 0으로 나눌 수 없다는 말을 들었을 것이다. 0으로 나눌 수 없는 이유는 모든 선생님이 가르쳐 주었을 텐데, 여전히 0으로 나누는 것이 왜 안 된다는 건지 모르겠다는 말을 많이 한다. 다른 수학 문제에 비하면 0으로 나누는 것을 도무지 모르겠다는 사람의 수는 그래도 적은 편이지만, 그래도 끊임없이 제기되는 문제인 것만은 분명하다. 한번 0으로 나눌 수 없는 이유를 짚어보자.
0으로 나누기,한번 해보자
두 실수가 주어지면 나눗셈을 하는 방법은 초등학교 고학년이 되면 배우게 된다. 예를 들어 3.764를 1.9로 나누려고 하면, 아래 그림처럼 나눠가기 시작한다. 
이런 나눗셈 방법을 ‘긴 나눗셈’ 한자로는 장제법(長除法) 영어로는 long division이라고 부른다. 이제 같은 방법을 써서 1을 0으로 나눠보자.

좀처럼 나눗셈이 되지 않는 것을 알 수 있다. 물음표 부분에 어떤 수를 쓰더라도 파란색으로 쓴 부분이 0이 되어 도무지 소거가 안 되는 것이다. 이 경우에는 ‘아무리 나누고 싶어도 몫을 구할 수 없으므로’ 나눗셈이 불가능한 것이다. 어떤 수든 0이 아닌 수를 0으로 나누면 같은 현상이 생긴다. 이번에는 긴 나눗셈을 써서 0을 0으로 나눠보자.

이번에는 조금 전과 상황이 다른데, 물음표 부분에는 1을 쓰든, 2를 쓰든 어떤 수를 쓰더라도 나눗셈이 단번에 끝난다. 하지만 이래서야 몫이 1인지, 2인지 알 도리가 없다. 따라서 0으로 나눈 값을 결정할 수가 없다! 이 경우엔 ‘몫을 정할 수 없어서’ 나눗셈이 안 되는 것이다.
컴퓨터도 0으로 나누라고 하면,못 하겠다고 버틴다
계산기에 1을 0으로 나눠본 결과
이처럼 0으로 나누려고 하면 긴 나눗셈은 통하지 않는다. 그렇지만, 혹시 뭔가 신비하고 특별한 다른 나눗셈을 쓰면 0으로 나눌 수 있지 않을까? 수학자들에게는 숨겨놓은 비장의 방법이 있지 않을까? 수학의 원리가 가장 잘 들어있는 컴퓨터에게 0으로 나누기를 시켜 보면 어떨까?
예를 들어 윈도 계열 운영체제에서는 컴퓨터 프로그램 수행 중에 긴급 상황이 발생하면, 중앙처리장치로 ‘인터럽트’라는 것을 보내 프로그램을 잠시 멈추고 컴퓨터의 처리를 기다린다. 그런데, 이런 인터럽트가 발생하는 상황 중 가장 상위에 있는 것이 바로 ‘0으로 나누기’이다. 프로그램이 0으로 나눌 것을 요청하면 중앙처리장치에서는 ‘0으로 나누는 것은 오류’, ‘0으로 나눌 수 없습니다’ 영어로는 ‘Divide by 0’라는 결과를 내보낸다. 이 오류를 잘못 처리하면 심할 경우 파란 화면을 띄우고 나 몰라라 하는 경우도 있다. 예를 들어 윈도 계산기로 1÷0을 시키면 이런 화면을 볼 수 있다.
그런데 컴퓨터는 왜 0으로 나눌 수 없다고 하는 것일까? 먼저 근본적으로 컴퓨터는 나눗셈을 못한다는 것부터 언급해야겠다. 계산 능력이 탁월한 컴퓨터가 나눗셈을 못하다니 무슨 뚱딴지 같은 소리냐고 오해는 하지 말길 바란다. 컴퓨터가 나눗셈을 못한다는 말은, 컴퓨터가 나눗셈을 할 때 ‘뺄셈’을 반복해서 처리한다는 뜻으로 한 말이다. 사실은 뺄셈도, 덧셈과 보수 연산을 이용해서 처리한다. 어쨌든 0으로 나누려면 0을 빼는 일을 반복해야 하는데, 0을 아무리 빼도 값이 변하지 않으므로, 뺄셈만 반복하며 무한 루프에 빠져 버릴 것이다. 그냥 뒀다가는 0만 빼다가 세월 다 보낼 테니, 0으로 나누는 것을 금지할 수밖에 없는 것이다. 나눗셈의 정의를 바꾸지 않는 한,누구도 0으로는 못 나눈다
사실 이미 감은 잡혔겠지만, 누가 뭐래도 0으로 나누는 것은 불가능하다는 것을 ‘증명’할 수 있다. 이를 위해서는 나눗셈이 ‘곱셈의 역연산’임을 돌이켜 생각해 보기만 하면 된다. a÷b를 계산하여 c가 나온다는 것은 c×b = a가 성립한다는 뜻이다. 예를 들어, 3÷2가 1.5인 것은 1.5×2 = 3이 성립하기 때문이다. 이제 예를 들어 3을 0으로 나눌 수 있다고, 즉, 3÷0 = c 를 만족하는 c를 구할 수 있다고 해 보자. 정의에 따라 c×0 = 3이 성립한다는 말과 마찬가지다. 그런데, ‘음수 곱하기 음수는 양수’를 설명할 때 증명한 적도 있지만, 왼쪽 변은 항상 0이다! 따라서 0=3이 성립하게 되어, 모순이 발생한다. 모순이 생겼다는 것은 중간 단계 어디선가 잘못했다는 뜻인데, 어디가 잘못인지 알기 위해서는 거꾸로 올라가는 것이 도움이 된다. 즉, 0이 3과 다르다는 것에서 거꾸로 올라가면, 애초 c×0 = 3 이 성립하는 c가 있다고 가정했던 것이 잘못이라는 뜻, 즉, 3÷0=c인 c를 구할 수 없다는 뜻이 된다! 따라서 0으로 나누는 것은 불가능하다.
그런데 이런 설명으로는 0÷0을 구할 수 없다는 얘기를 하기에는 불충분하고, 조금 보충 설명이 필요하다. 이제 0÷0이 계산 가능하다고 하자. 이때는 1×0 = 0 , 2×0 = 0인 것을 알기 때문에 나눗셈의 정의로부터 0÷0 = 1 및 0÷0 = 2가 성립할 것이다. 따라서 1 = 2가 되어야 한다. 이것 역시 모순이다. (왜 모순일까? 예를 들어 페아노 공리계의 용어를 쓰면 1=1’인데, 이는 1이 어떤 수의 다음수도 아니라는 데 모순이다!) 이런 모순은 0÷0이 계산 가능하다는 가정을 한 데서 생기는 모순이다. 따라서 0÷0 역시 불가능하다.
그런데 왜 하필 0으로만 나눌 수 없나?
예를 들어 1.8으로는 나눌 수 있고, -π로도 나눌 수 있는데, 왜 하필 0으로만 안 되는 걸까라는 질문을 해 볼 수 있다. 이미 답은 나온 셈이지만, 0이 뭐 그리 대단한 수라서 그런 특혜를 누리는 걸까? 사실 0은 대단한 수가 아니라고 생각할 수도 있다. 어떤 수든 0을 더해도 그대로이기 때문에, 덧셈에 관한 한 0은 있으나마나 한 변변치 못한 수니까. 그러나 0을 빼놓고 생각하는 덧셈은 ‘오아시스 없는 사막’이라는 것을 알아 주기 바란다. 0이 덧셈에서는 변변치 못했을지는 몰라도, 곱셈에서만큼은 어마어마하게 사정이 다르다. 가히 무소불위의 권력을 휘두른다. 어떤 수를 곱해도 그 수를 무력하게 만들고 결과를 0으로 만들기 때문이다. 그런데 이런 성질을 갖는 수는 0밖에 없다! 바로 이런 이유 때문에 0으로는 나눌 수 없는 것이다. 본질적으로는 같지만, 조금 다른 방식으로 설명해 보자. 예를 들어 4×b를 생각하자. 이 값은 b가 달라지면 결과가 달라진다. 또한, 모든 수가 곱셈 결과가 될 수 있다는 것도 (예를 들어, 긴 나눗셈을 해 보면) 알 수 있다. 이 두 가지 성질은 4를 다른 수로 바꿔도 성립하는데, 오로지 0만 예외다. 0×b를 생각하면, b가 달라도 결과가 달라지기는커녕, 결과는 0 하나밖에 안 나온다! 적어도 곱셈에 대해서는 (따라서 나눗셈에 대해서도) 0만큼은 특별 대접을 하지 않을 수 없는 것이다.
0으로 나누면 무한대라던데요
0을 맨 처음 수로 취급한 인도에서 0으로 나누는 문제를 맨 먼저 고민했을 거라는 사실은 짐작할 수 있는데, 일례로 12세기의 유명한 인도 수학자 바스카라(Bhaskara Acharya, 1114~1185)는 자신의 저서 “릴라바티(Lilavati)”에서 1÷0을 무한대로 취급하였다. 사실 현대 수학자들도 극한의 개념을 써서 이렇게 취급하는 경우가 있을 만큼, 이런 주장에는 장점도 있다. 하지만 섣불리 1÷0을 무한대로 취급하는 것은 자칫 오해를 부를 수 있으므로 조심하는 게 좋다. 첫째, 1÷0 = ∞ 라는 말은, 1 = ∞ x 0 을 뜻하는 말이 아니라는 것이다. ∞는 숫자도 아니므로 무작정 숫자와 곱셈을 할 수는 없는 것이다. 둘째, 1÷0 = ∞ 라면 당연히 -1÷0 = -∞로 취급해야 할 것이다. 그렇다고 예를 들어 다음과 같이 주장하는 ‘우’를 범해서는 안 된다.

무한대는 수가 아니므로, 무한대와 관련한 연산은 보통의 의미에서의 사칙 연산의 규칙을 그대로 따르지 않을 수 있기 때문이다. 사실 무한대와 관련한 연산은 ‘극한의 개념’이나 ‘확장된 실수계의 개념’ 등을 이용할 때 비로소 제대로 된 의미를 가지는데, 그런 개념을 소개하는 것은 이 글이 의도하는 바의 범위를 넘으므로 생략하기로 한다. 그러나, 1÷0 = ∞ 이라는 표기를 쓴다고 해서 여전히 ‘0으로 나눌 수 있다’는 얘기는 아님을 다시 한 번 강조해 두고 싶다.
관련글 : -1×-1=1인 이유는?
글 정경훈 / 서울대 기초교육원 강의교수
출처: http://sonseungha.tistory.com/33 [Linuxias]
etc 2017. 1. 18. 16:19
정수와는 달리 실수는 크게 지수부분(exponent)과 소수부분(mantissa)으로 나누어 저장됩니다. 가장 많이 사용하는 IEEE754 규격의 예를들겠습니다. 32비트의 실수가 저장되는 방식은 32 = 1(sign bit)+8(exponent)+23(mantissa) 이렇게 나누어 저장이 됩니다. sign bit은 양수일 때 0, 음수일 때 1이구요. exponent는 2의 몇승인지 나타내지요. 이때 bias 127방식으로 저장되기 때문에 실제 지수에 127이 더해서 저장이 됩니다. mantissa부분은 소수점 아래 24bit에 해당합니다. (지수에 127을 더하는 이유는 만약 데이터가 손상되서 지수부분이 모두 0000 0000이 되었다고 생각해 보죠. 지수가 0이면 결과는 1을 갖게 됩니다. 하지만 손상된 값은 0이 되는것이 좋겠죠. 만약 bias127을 사용했다면 결과는 어떤수의 -127승이 되어 거의 0이되는 효과를 갖게되죠.) 예를들어 십진수 12.5 를 저장한다고 하면, 우선 이진수로는.. 1100.1 이렇게 되겠죠. 이것을 지수부와 소수부로 표현해 보면 1.1001*(2^3) 이렇게 되겠네요. (이때 소수점 왼쪽의 1은 hidden 1이라 하여 따로 저장되지 않습니다. 당연히 1밖에 올수 없으니까요..) 그럼 지수는 3이고 소수부는 1001 이 됩니다. bias를 적용하면 exponent=130 즉 이진수로 10000010 이 되지요. mantissa는 100 1000 0000 0000 0000 0000 이렇게 23bit를 차지하겠죠. 즉 실제로 저장되는 데이터는 0 1000 0010 100 1000 0000 0000 0000 0000 이렇게 되겠지요.(띄어쓰기는 임의로 했습니다) 실수라도 float은 4바이트고 double은 8바이트입니다. IEEE 64비트 배정밀도(double-precision) 실수 표현 방식은 네이버 지식인 검색에서 IEEE 754 로 검색하면 아주 훌륭한 답변들이 많으므로 재탕은 생략하겠습니다. 참고로 말씀드리자면 double 전체 크기가 8바이트인데 정수 부분만 8바이트라면 소수 부분은 어디에 저장될까요? 소수부 + 정수부 + 부호비트 합하여 64비트(8바이트)입니다. 그리고 IEEE 표기법을 간단하게 말하자면 소수부와 정수부 따로 구분하지 않고 유효숫자와 지수형태의 표기방법을 사용합니다. 즉 100.1이라면 무조건 숫자는 정수 1자리, 나머지 소수(즉 1.001)로 표기하고 대신 지수부분을 2라고 써줍니다. 그렇다면 1.001 * 10^2(10의 2승)은 100.1이 되는 형태지요.
출처 - http://m.blog.naver.com/sncherry/50026275330
etc 2017. 1. 18. 16:18
부동 소수점 표현은 아주 큰 수와 아주 작은 수를 효율적?으로 표현하기 위해서 사용한다. 여기서 효율적이란 표현은 정확하다는 표현은 아니다. 효율적일 수록 오차가 발생하기 마련이다. 우선 부동소수점표현을 어떤 방식으로 하는지 이해하고, 오차가 발생할 수 밖에 없는 원리도 이해해보자. 부동 소수점 우선 우리가 10진수를 10으로 나누거나 곱하면 소수점의 위치를 변경할 수 있다. 이와 마찬가지로 2진수 또한 2로 나누거나 곱하면 소수점 위치가 한 칸씩 이동된다.(자세한 설명은 하지 않겠지만, 이 원리를 이용해 진수변환도 한다는 것을 알아 두자.) 부동 소수점은 이런 원리를 이용해서 소수점의 위치를 나타낸다. 예를 들어 1001.1011 이란 수가 있다면, 부동 소수점은 이 수를 1.0011011 * 2^3 으로 표현 한다. 여기서 3은 위에서 설명한 원리를 통해 소수점의 위치를 정하게 되고 앞에 1.0011011은 1001.1011을 정규화한 것이다. 정규화 방법 정규화 방법은 정수부에 1만 남기도록 소수점을 이동하고 소수점에 관한 정보는 2^x으로 표현하는 것이다. 이런 표현은 고정 소수점 보다 효율적으로(적은 비트로) 큰 수를 표현할 수 있다. 부동 소수점 구조 알아보기 
위 그림은 c/c++에서 float형의 표현 방식이다. 부호부 : 표현할 값이 0인 경우 양수, 1인 경우 음수 지수부:(2의 8승) -1가지 표현을 할 수 있다. 다시 말하면 2진수 체계에서 주어진 가수의 (2의 8승) -1가지 자리수 표현이 가능하다. 가수부: 가수부는 수의 모양을 알려주는데, 위에 예시의 수의 가수부는 00110110000000000000000(23자리)이 된다. 23bit(자리수)가 갖는 한계와 특징에 대해서는 따로 설명하겠다. 지수부 부동 소수점의 지수부는 컴퓨터가 수를 표현하는 일반적인 방식과 다르다. 바이어스(bias)표현 법인 이 방법을 알면 부동 소수점에 대해서 80%는 이해했다고 보면 된다. 예를 들어 char형 자료형으로 수를 표현하는 방법은 다음과 같다. 0000 0000 : 0 ... 0111 1111 : 127 1000 0000 : -128 1000 0001 : -127 ... 1111 1111 : -1 -128~127 까지 수를 표현 이렇게 음수를 표현하는 방법을 2의 보수법이라고 한다. 아무튼 char 뿐 아니라 int형도 이런 식으로 표현된다. 바이어스 표현법 지수부가 8bit인 부동 소수점을 표현할 때, 바이어스 표현법은 다음과 같다. 0000 0000 : -127 0000 0001 : -126 .... 0111 1111 : 0 .... 1111 1111 : 128 이런 식으로 표현하는 이유는 일반적인 정수를 나타낼 때와 지수를 나타낼 때, 0과 음수의 의미가 다르기 때문이다. 여러 특징이 있겠지만, 우선 밑이 양수인 경우 지수가 음수여도 값은 양수가 되기 때문이고, 지수가 음의 무한대로 뻗어나가더라도 밑이 무한히 0에 가까운 수가 된다.(0보다 큼) 따라서, 지수부가 8bit인 경우 가장 작게 표현할 수 있는 -127의 경우를 0000 0000으로 표현한다. 바이어스 상수 여기서는 IEEE754표준인 127바이어스법(8bit)을 기준으로 한다. 바이어스 상수 : 2^(n-1)-1 n:비트부 자리수(여기서는 8bit) 64바이어스법은 바이어스 상수가 100 0000이 되는데, 여기서는 127바이어스 법만 다룬다. 2의 보수법 + 바이어스 상수 = 바이어스 표현법 예를 들어 2의 보수법으로 127을 표현하면 0111 1111 이고 이를 바이어스 표현법으로 바꾸려면(float형) 127((2^8)-1)을 더하면 된다. 0111 1111 + 0111 1111 = 1111 1110 (127 바이어스 법으로 표현한 127) 예) -0.4를 16부동 소수점으로 바꾸어라. ( 지수부 5bit, 가수부 10비트) 0.4 = 0.0110011001100110...(2진수) = 1.1001100110...*2^-2 따라서 지수부는 -2가 된다. -2를 2진수로 나타내면(2의보수법) 1 1110이 된다. 지수부 비트가 5bit므로 바이어스 상수는 2^5-1 = 15 = 0 1111 지수부를 바이어스 표현 법으로 나타내기 위해 위 두값을 더한다. 1 1110 + 0 1111 = 0 1101 따라서, 1 0 1101 1001100110 예) 19.25를 127 바이어스법으로 바꾸면 19.25 = 10011.01(2진수) = 1.001101 * 2^4 4 = 100(2진수) 여기서 비트부를 바이어스법으로 바꾸면 100 + 0111 1111 = 1000 0011이 된다. 따라서 0100 0001 1001 1010 0000 0000 0000 0000 로 표현할 수 있다. 0을 표현하는 방법 바이어스 표현 방법으로 지수의 표현은 -127 ~ 128까지 가능하다. 그러면 0의 표현은 어떻게 할까? 상식적으로 생각하면 0은 표현할 수 있는 가장 작은 양수 보다 작거나 같아야 한다. 부동 소수점 표현에서 표현할 수 있는 가장 작은 수는 다음과 같다. 
따라서 모두 0인 경우를 0으로 하기로 한다. 2^-127보다 작은 수 표현 그런데 32bit float가 표현할 수 있는 가장 작은 수는 2^149이다. 위에서 모든 비트가 0으로 채워진 경우(지수부가 -127승인 경우)는 0을 표현한다고 했다. 그러면 어떻게 2^-127승 보다 더 작은 수는 어떻게 표현하는 것일까? 규칙 지수부가 모두 0인 경우는 특별한 경우로 나누어 생각하는 것이 좋다. 모든 비트가 0인 경우는 0을 나타낸다.(위에서 살펴봄) 지수부의 비트가 0이지만 가수부의 비트는 0이 아닌 경우, 유효수에서 정수값을 1이 아닌 0으로 한다. 그리고 지수값을 -126으로 약속 한다. 예를 들어, 
0.00000000010000000001000 * 2^-126 
0.10000000000000000000000 * 2^-126 = 2^-127 
0.00000000000000000000001 * 2^-126 = 2^-149 따라서 32bit float형의 표현할 수 있는 가장 작은 수는 2^-149승이 된다. 참고로 2^-126은 다음과 같다. 
1. 00000000000000000000000 * 2^-126 = 2^-126 지수부 비트가 모두 1로 채워진 경우 우선 이 경우 지수부는 128을 나타내는데 가수부의 형태에 따라서 두 가지 상태를 나타낸다. 가수부 비트가 모두 1인 경우 inf를 나타냄(무한) 가수부 비트가 모두 1이 아닌 경우 nan을 나타냄(미정값) 최대값 0x7f7fffff 는 float자료형이 표현할 수 있는 가장 큰 수가 된다. 약 2^128승정도가 되는데 
이런 식으로 표현된다. 부동 소수점의 오차 부동 소수점은 적은 비트로 큰 수를 표현할 수 있지만, 이런 효율성은 정확성을 떨어뜨릴 수 밖에 없다. float의 가수부의 크기는 23bit인데, 23은 실제로 값자리수(길이)를 나타낸다. 부동 소수점의 표현 방식상 정수값 자리수가 23을 넘어가게 되면 소수점 이동이 23(가수의 길이)이 넘어가므로 가수부의 길이를 초과하여 소수점 이하를 표현할 길이 없어진다. 길이를 넘어가게 되면 가수의 마지막 자리 값은 넘어간 수만큼의 0이 생긴다. 지수값이 24인 경우 0이 하나 생겼다. 2진수의 LSD(least significant Digit)가 무조건 0이기 때문에 홀수를 표현할 수 없다. 지수값이 25가 되면 0이 두개 생긴다. 따라서 4의 배수만 표현된다. 이런 식으로 오차가 점점 늘어나는데, 사실 이런 오차는 지수값이 23이넘어가면 값의 크기에 비해서 아주 작은 값이 되므로 그렇게 큰 차이는 아니지만, 정밀도가 떨어질 수밖에 없다. 따라서 double 타입의 자료형을 사용하면 이런 오차를 좀 더 줄일 수 있다.
출처 - http://thrillfighter.tistory.com/349
리버싱 2017. 1. 10. 16:41
여덟번째 이야기입니다. 연재도 거의 끝이 보입니다. ^^; 이번 이야기는 섹션 테이블에 관한 이야기입니다. (익스포트에 관해서는 PE 파일을 다 만든 다음에...)만들던 PE 파일 마저 조립해야죠. 이번 이야기 마지막에는 PE 파일을 완성할 수 있을 것입니다. 고고싱~~
섹션 테이블은 IMAGE_SECTION_HEADER 타입의 엘리먼트로 구성된 배열입니다. 섹션 헤더는 섹션의 이름, 섹션의 파일 상에서의 위치 및 사이즈 정보, 메모리 상에서의 위치 및 사이즈 정보 그리고 메모리 상에서의 속성 값에 대한 정보를 가지고 있습니다. 요컨대 섹션 헤더에는 로더가 각 섹션을 메모리에 로드하고 속성을 설정하는데 필요한 정보들이 담겨져 있는 것입니다. 아 그러고 보니 섹션에 대한 이야기를 빠뜨렸군요. 섹션은 동일한 성질의 데이터가 저장되어 있는 영역이라고 생각하시면 되겠습니다. 섹션은 왜 필요할까요? 이는 윈도우에서 사용하는 메모리 프로텍션 매커니즘과 연관이 있습니다. 윈도우의 경우 메모리 프로텍션의 최소 단위가 페이지입니다. 페이지 단위로 PAGE_EXECUTE, PAGE_EXECUTE_READ, PAGE_EXECUTE_READWRITE, PAGE_READONLY, PAGE_READWRITE 같은 속성을 설정해두고 속성에 위배되는 오퍼레이션을 시도할 때 Access violation을 발생시켜 메모리를 보호한다는 이야기입니다. 다시 말해 페이지의 일부는 읽기만 가능하고, 페이지의 일부는 읽고쓰기가 가능하도록 설정하는 방식의 프로텍션은 허용하지 않는다는 이야기죠. 이는 성격이 다른 데이터들을 하나의 페이지에 담을 수 없다는 것을 의미합니다. 그렇다보니 프로그램에 포함된 데이터들 중 읽기와 실행이 가능해야 하는 데이터 즉 실행코드와 읽고 쓰는 것이 가능한 데이터, 읽기만 가능한 데이터등을 별도의 페이지에 두어야 하는데 로더에 입장에서는 이를 구분할 방법이 없으므로 섹션이라는 개념을 두어 실행 파일 생성 단계에서 구분해 놓도록 하는 것입니다.
IMAGE_SECTION_HEADER는 아래와 같이 정의되어 있습니다.
typedef struct _IMAGE_SECTION_HEADER {
BYTE Name[IMAGE_SIZEOF_SHORT_NAME];
union {
DWORD PhysicalAddress;
DWORD VirtualSize;
} Misc;
DWORD VirtualAddress;
DWORD SizeOfRawData;
DWORD PointerToRawData;
DWORD PointerToRelocations;
DWORD PointerToLinenumbers;
WORD NumberOfRelocations;
WORD NumberOfLinenumbers;
DWORD Characteristics;
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
지금까지 해왔던 것처럼 중요한 필드들만 살펴보도록 하겠습니다.
Name : 섹션의 이름입니다. 최대 사이즈는 8bytes이구요. IMAGE_SIZEOF_SHORT_NAME이 8이라는 거죠. 이 필드와 관련해서 기억해야 할 것은 Name은 로딩 과정과는 아무 상관이 없다는 것입니다. 로더는 이 값을 거들떠 보지도 않습니다. -.-;; 섹션의 이름은 마음대로 정할 수 있으며 심지어 널이어도 관계가 없습니다. 섹션 이름은 C언어에서의 문자열과는 달리 NULL로 끝나지 않아도 됩니다.
VirtualAddress : 섹션이 로드될 가상 주소를 나타내는 필드입니다. PE 포맷 내에서 모든 가상 주소값이 그렇듯이 이 필드 역시 RVA 값입니다.
SizeOfRawData : 이 필드는 파일 상태에서의 섹션의 사이즈 값을 가지고 있습니다. 물론 file alignment의 배수이어야 하겠죠.
PointerToRawData : 파일 상태에서의 섹션의 시작 위치를 나타냅니다.
Characteristics : 섹션의 속성 값입니다. 속성 값 중 중요한 것들은 글의 서두에서 언급했던 것처럼 메모리 프로텍션과 관련된 것들로 excute, read, write 등이 있습니다.
요컨대 로더는 PointerToRawData가 지정한 곳에서 부터 SizeOfRawData 만큼의 데이터를 읽어들여 VirtualAddress에 맵핑한 후에 Characteristics에 설정된 속성 정보를 이용하여 페이지 프로텍션을 적용하는 것입니다. 나머지 필드의 값은 지금은 그다지 중요하지 않으므로 생략하도록 하겠습니다.
뭐 별거 없지 않습니까? ^^; 바로 PE 파일을 만들어 보도록 하겠습니다. 만들면서 아래의 그림을 참조하도록 하세요.
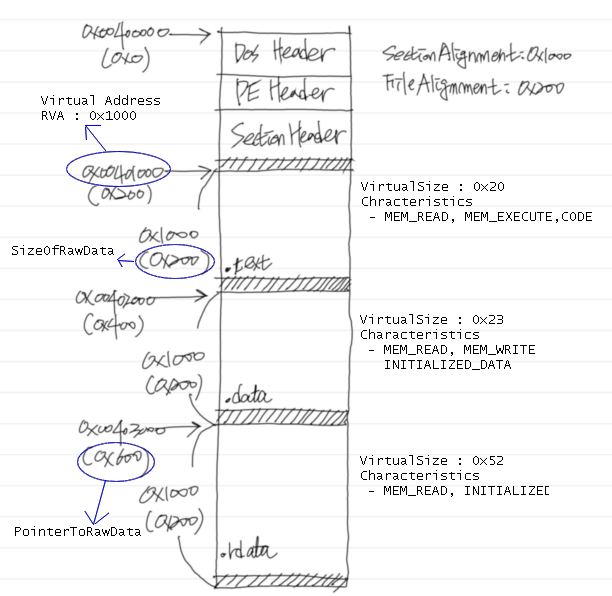
[그림 1] 제작 중인 파일의 섹션 레이아웃
Step 1. 섹션 테이블을 위한 공간을 할당합니다.
IMAGE_SECTION_HEADER의 사이즈는 40bytes이며, 섹션 테이블에는 섹션의 개수와 동일한 수의 IMAGE_SECTION_HEADER가 필요하므로 120bytes 공간을 할당하면 됩니다. (앞서의 글에서 우리는 실행코드를 위한 섹션과 데이터를 위한 섹션 그리고 임포트 테이블을 구성하기 위한 섹션을 만들것이라고 이야기했습니다. 또한 섹션의 개수는 PE헤더에 기록되어 있음을 떠올려보세요. 만약 섹션의 개수가 어딘가에 기록되어 있지 않다면 로더의 입장에서 섹션의 개수를 알 수 없으므로 섹션 테이블의 끝을 나타내는 IMAGE_SECTION_HEADER가 하나 더 추가되어야 할 것입니다.)
Step 2. 실행 코드를 위한 섹션 헤더를 완성해 보도록 하겠습니다.
- 먼저 섹션의 이름은 일반적으로 컴파일러가 하는 것처럼 .text로 하도록 하겠습니다.
- 그 다음으로 채워야 할 값은 VirtualSize입니다. 이 필드에는 섹션 영역의 실제 사이즈를 채워넣으면 됩니다. 우리가 사용할 코드는 32bytes사이즈를 가지고 있습니다. 따라서 VirtualSize는 리틀엔디언임을 고려하여 20 00 00 00 으로 채우면 되겠습니다.
- 그 다음으로 채워야 할 값은 VirtualAddress 입니다. .text 섹션의 VirtualAddress는 [그림 1]에서 볼 수 있는 것처럼 0x1000이 됩니다. 따라서 00 10 00 00 으로 채우면 되겠습니다.
- 그 다음으로 채워야 할 값은 SizeOfRawData입니다. 역시 [그림 1]을 참고하여 0x200으로 하도록 합니다. 이는 코드의 사이즈가 32bytes이고 앞서의 글에서 PE 헤더의 FileAlignment 값을 0x200으로 설정하였기 때문입니다. 00 02 00 00 으로 채우면 되겠습니다.
- [그림 1]을 살펴보면 PointerToRawData 값은 0x200 임을 알 수 있습니다. 실행코드의 실제 사이즈가 32bytes이고 이는 앞에서 설정한 FileAlignment 단위인 0x200(512bytes)보다 작기 때문에 패딩을 추가해야 하기 때문입니다.(이해가 되지 않으시면 앞의 글들을 다시 확인해 보세요) 00 02 00 00 으로 채우면 되겠습니다.
- PointerToRelocations 부터 NumberOfLinenumbers 까지의 12bytes는 모두 0으로 채웁니다.
- Characteristics를 채울 차례군요. .text 섹션에 실행 코드를 두어야 하므로 CODE, MEM_READ, MEM_EXECUTE 속성을 지정할 것입니다. 이 값은 0x60000020 입니다. 이 값에 대한 내용은 구글신에게 기도를 드려보세요. 20 00 00 60 을 채워넣으면 되겠습니다.
지금까지의 작업 내용은 아래와 같습니다.
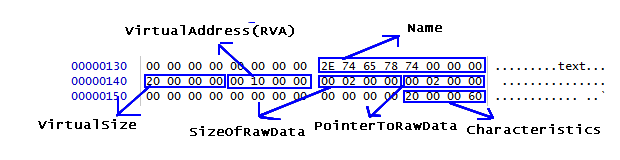 [그림 2] 완성된 .text 섹션 헤더의 모습
Step 3. .data 섹션을 위한 헤더를 완성합니다.
[그림 3]은 [그림 1]을 참고하면서 완성한 .data 섹션 헤더의 모습입니다. 속성값은 C0000040으로 설정하였는데 이는 INITIALIZED, MEM_READ, MEM_WRITE를 의미하는 값입니다.
[그림 3] 완성된 .data 섹션 헤더의 모습
Step 4. .rdata 섹션을 위한 헤더를 완성합니다.
앞에서와 마찬가지로 .rdata 섹션을 위한 섹션 헤더를 완성한 모습이 아래 [그림 4]입니다. 속성값은 40000040으로 설정하였는데 이는 INITIALIZED, MEM_READ를 의미하는 값입니다. 우리는 .rdata 섹션에 임포트 테이블을 둘 것입니다.(요즘의 컴파일러들은 우리와 달리 임포트 테이블을 별도의 섹션에 두지 않고 .코드 섹션이나 데이터 섹션에 임포트 테이블을 두는 경향이 강한 것 같습니다.)
[그림 4] 완성된 .rdata 섹션 헤더의 모습
Step 5. .text 섹션을 생성하고 내용을 채워 넣습니다.
섹션 테이블을 드디어 완성했습니다. 이제는 섹션을 만들차례입니다.
먼저 .text 섹션을 생성하기 전에 FlieAlignment를 고려하여 0x1FF까지 0x00을 패딩합니다. 우리는 FileAlignment를 0x200으로 설정하였으므로 첫번째 섹션인 .text 섹션은 아래 [그림 5]에서 볼 수 있는 것처럼 0x200에서 시작합니다. 패딩을 끝냈으면 섹션을 위한 영역을 할당해야 겠습니다. 우리가 사용할 코드의 사이즈는 32bytes 이지만 역시 FileAlignment를 고려해야 하므로 512bytes만큼의 빈 공간을 추가하면 되겠습니다.
끝으로 첨부된 code.bin을 복사하여 0x200 위치에 붙여넣으면 됩니다. 완성된 모습은 아래와 같습니다.
[그림 5] 완성된 .text 섹션의 모습
Step 6. .data 섹션을 생성하고 내용을 채워 넣습니다.
앞의 단계에서와 마찬가지로 512bytes 공간을 추가한 다음 첨부된 data.bin을 복사하여 0x400에 붙여 넣습니다. 완성된 모습은 아래와 같습니다.
[그림 6] 완성된 .data 섹션
Step 7. .rdata 섹션을 생성하고 임포트 테이블을 완성합니다.
이 부분은 앞에서의 다른 섹션과 달리 직접 수작업으로 완성해 가도록 하겠습니다. .rdata 섹션의 시작점에 임포트 테이블을 작성할 것입니다. 임포트 테이블 및 관련 정보의 모양은 [그림 7]과 같습니다. 우리가 사용하는 코드는 MessageBoxA를 이용하여 메시지 박스를 띄우는 프로그램입니다. MessageBoxA는 user32.dll에서 익스포트하는 API입니다. 이를 염두해 두시고 아래 그림을 살펴보시기 바랍니다.
[그림 7] 임포트 테이블 및 관련 정보 레이아웃
[그림 7]과 여섯번째 이야기의 [그림 2]를 참고하여 데이터를 채워나가면 아래와 같습니다. (사이즈를 줄이기 위해서 위의 배치를 조금 변경할 수도 있습니다. 하지만 KISS 원칙에 입각하여 ㅋㅋ 무식하게 채웠습니다.) 참고로 오디널값은 00으로 채워도 무방합니다. 이러한 경우 로더는 뒤에 나온 이름을 이용하여 함수의 주소값을 찾게 됩니다.
[그림 8] 완성된 임포트 테이블 및 관련 데이터의 모습
Step 8. 자 이제 데이터 디렉토리에 임포트 테이블의 주소(RVA)와 사이즈를 기록해야 겠습니다.
다섯번째 이야기에서 데이터디렉토리를 위한 공간 128bytes를 생성한 바 있습니다. 그 때 생성한 데이터 디렉토리의 파일 상의 offset은 확인해 보시면 0xB8입니다. 각 엔트리의 사이즈는 8bytes이며 IMPORT_DIRECTORY_ENTRY_IMPORT는 두번째 엔트리이므로 우리는 0xC0에 임포트 테이블에 대한 VirtualAddress와 Size를 차례대로 채워넣어야 겠습니다. VirtualAddress에는 00 30 00 00 을 입력하고 Size는 60 00 00 00 으로 입력하면 됩니다. 완성된 데이터 디렉토리의 모습은 아래와 같습니다.
[그림 9] 완성된 데이터 디렉토리의 모습(일부)
Step 9. 짜잔!!!! 드디어 완성입니다. 실행시켜보겠습니다.
[그림 10] 우리의 첫번째 작품입니다.
잘 실행되셨습니까? 축하드립니다.
점프 테이블
이번 글을 끝내기 전에 한가지 언급해야 할 일이 있습니다. 다름 아닌 점프 테이블에 관한 이야기입니다. 지금까지 알아본 내용을 바탕으로 생각해보면 컴파일러는 컴파일을 수행할 때 임포트한 API의 주소를 알 수가 없습니다. (pre binding 기능 역시 링커가 해주는 것이죠) 그렇다면 CALL MessageBoxA와 같은 코드는 어떤 형식으로 컴파일 될까요? 완성된 코드를 Ollydbg로 열어 그 매커니즘을 확인해보세요. 아래 간단한 설명을 달아 놓았습니다. 조금만 생각해보시면 쉽게 이해하실 수 있을 것이라 믿습니다.
[그림 11] ollydbg에서 확인한 점프 테이블
지금까지 PE 파일의 대략의 구조를 살펴보면서 손수 실행 파일을 만들어보았습니다. 재미있으셨는지 모르겠네요. 이제 연재도 끝나가네요. 다음번에는 마지막으로 익스포트에 대해서 알아보도록 하겠습니다. 나머지 재배치나 리소스 섹션에 대한 이야기는 인터넷 상에 자료가 많으니 별도로 공부하시기 바랍니다. 이호동씨의 책에도 매우 자세히 잘 나와있습니다. 오늘도 즐핵하세요_~
* 제 잘못된 습관 중 하나가 글을 쓴 후 잘 읽지를 않는 것이어서 오탈자도 많을 테고, 내용상 오류가 있을 지도 모르겠습니다. 댓글달아주시면 수정하도록 하겠습니다.
첨부파일 1. 코드섹션
첨부파일 2. 데이터섹션
출처 - http://zesrever.tistory.com/74
리버싱 2017. 1. 10. 16:40
일곱번째 이야기입니다. 참 오랜만에 쓰는 글 같습니다. 저도 글을 쓰기 전에 앞에 쓴 글을 다시 읽어봐야 했습니다. 먼소리를 했는지 기억이 안나서... ^^; 암튼 살펴보니, 앞서 이야기에서 ILT에서 임포트할 함수의 이름 또는 ordinal 값을 알아낸 후 이 정보를 이용하여 익스포트 디렉토리(익스포트 테이블)로 부터 함수의 주소를 알아낸다는 사실을 알아보았더군요. 살짝 복습을 해볼까요? Windows XP에 있는 calc.exe 프로그램의 임포트 디렉토리를 찾아 ILT와 IAT를 잠깐 살펴보도록 하죠. 데이터 디렉토리는 그냥 StudPE를 이용하여 확인하도록 하겠습니다.
그림 1. StudPE로 살펴본 calc.exe의 임포트 테이블(임포트 디렉토리) 주소
임포트 테이블(임포트 디렉토리)의 주소(RVA)는 0012B80이고 사이즈는 8c입니다. 여섯번째 이야기에서 알아보았듯이 Raw Offset 값은 StudPE가 계산해 준 것이구요, 실제로 데이터 디렉토리에는 존재하지 않는 데이터이죠. 실제 계산 방법은 여섯번째 이야기를 참고하세요. 어쨌든 파일 상에서는 Raw Offset 11F80에서 임포트 테이블을 찾을 수 있겠습니다. WinHex를 이용하여 11F80으로 이동하여 보겠습니다.
그림 2. WinHex를 이용하여 살펴본 calc.exe의 임포트 테이블
[그림 2]에서와 같이 두번째 필드인 TimeDateStamp와 세번째 필드인 ForwarderChain은 바인딩 전에는 -1 값을 가집니다. 세번째 필드는 Name은 임포트할 DLL의 이름을 가르키는 포인터(RVA)입니다. 파일 상태에서 읽을 필요가 없으므로 RVA값만 기록되어 있습니다. 기억하시죠? PE 파일에서 어떠한 데이터 구조를 가르킬 때 RawOffset 값이 없다면 로더 입장에서 해당 데이터 구조는 파일 상태에서는 따로 접근하지 않는다는 이야기입니다. 메모리에 로드된 후에나 사용한다는 것이죠. 어쨌든 그래도 파일 상에서 Name을 확인해보도록 하겠습니다. 여섯번째 이야기에서 살펴본 것처럼 데이터 디렉토리내의 데이터구조를 파일 상에서 찾으려면 RVA값과 RawOffset이 동시에 기록되어 있는 섹션 테이블을 참조해야 합니다. StudPE를 이용하여 섹션 테이블을 살펴보면 Name은 .text 섹션에 포함되어 있음을 알 수 있습니다. (RVA값이 00012E42이므로 .text 섹션 범위안에 존재합니다. 아래 그림 참고)
그림 3. StudPE를 통해 살펴본 calc.exe의 섹션 테이블
.text 섹션의 RVA 값은 00001000이고 RawOffset은 400 이네요. Name필드의 RVA값은 00012E42 이므로 RawOffset은 0x400+(00012E42 - 00001000 ) = 0x12242가 됩니다. WinHex를 이용해서 확인해 볼까요?
그림 4. WinHex를 이용하여 살펴본 calc.exe의 임포트 디렉토리
이로써 임포트 디렉토리의 첫번째 엔트리는 shell32.dll에 관한 것임을 알 수 있습니다. 그럼 ILT와 IAT를 살펴보도록 하겠습니다. 첫번째 필드인 OriginalFirstChunk로 ILT를 가르키는 RVA 값이며 마지막 필드인 FirstChunk로 IAT를 가르키는 RVA 값이라는 것을 잘 아는 사실일 것입니다. ILT와 IAT 역시 파일 상태에서는 읽을 필요가 없는 데이터들이라 RVA값만 기록되어 있습니다. 휴~ 또 산수시간입니다. ^^; ILT의 위치는 00012CA8 이므로 역시 .text 섹션에 존재함을 알 수 있습니다. 그렇다면 ILT의 파일 상에서의 위치 즉 RawOffset은 0x400 + (12CA8 - 1000) = 0x120A8이군요. WinHex를 이용해서 해당 위치로 이동해 보겠습니다.
그림 5. calc.exe의 shell32.dll관련 ILT
ILT나 IAT는 모두 IMAGE_THUNK_DATA의 배열이라고 했습니다. IMAGE_THUNK_DATA는 4가지 정도의 의미를 가지고 있는데 ILT의 경우 대부분 IMAGE_IMPORT_BY_NAME을 가르키는 RVA값이라는 것도 이미 알아봤구요. 살펴보니 ILT의 첫번째 엔트리는 00012E34 값을 가지고 있네요. 헉헉...
ㅠ.ㅠ;; 또 산수가 필요합니다. 0012E34는 .text 섹션에 위치하므로 파일 상에서의 위치는 0x400 + ( 0012E34 - 1000 ) = 0x12234 입니다. 다시 WinHex를 이용해서 해당 위치를 살펴보도록 하겠습니다.
그림 6.
위 그림에서 볼 수 있듯이 IMAGE_IMPORT_BY_NAME은 1바이트 사이즈 ordinal값과 이름으로 구성되어 있습니다. 위 그림을 보니 SHELL32.DLL에서 임포트한 첫번째 함수는 ShellAboutW로 오디널 값이 0x94임을 알 수 있습니다.
자, 이제 IAT를 살펴볼까요? 다시 [그림 2]로 돌아가서 살펴보니 IAT의 RVA는 109C이군요. 역시 .text 섹션에 위치합니다. IAT는 RawOffset은 0x400 + (109c - 1000) = 0x49c 입니다. WinHex를 이용하여 해당 위치를 살펴보면 아래와 같습니다.
 그림 7. calc.exe의 shell32.dll관련 IAT
위 그림에서 볼 수 있듯이 파일 상에서 즉 바인딩 되기 전의 IAT는 ILT와 마찬가지로 보통 IMAGE_IMPORT_BY_NAME 타입의 데이터를 가르킵니다. 물론 동일한 정보를 가르키고 있어야 합니다. 따라서 7744E3DB에 가면 ... 그런데 허걱.. 뭔가 주소가 이상하네요? 7744E3DB라면 왠지 윈도우의 주요 DLL들이 사용하는 주소 중 하나인것 같은데요.. 이럴수가.. 제가 지금까지 거짓말을 한건가요? ㅠ.ㅠ;; 뭐 그런것은 아니구요... ^^ 이건 pre binding(보통 줄여서 binding 또는 bound라고 부릅니다.)이라는 기능때문에 그렇습니다.
Pre-Binding
여러개의 DLL을 로딩하는 경우 로딩 타임에 IAT를 완성하는 것은 비교적 오랜 시간이 소요되는 작업이 될 것입니다. 그만큼 프로그램 실행에 많은 지연이 발생하겠죠. 그렇다면, 만약 로딩 타임에 IAT를 완성하지 않고 링킹 타임에 IAT를 미리 완성해 둘 수 있다면 어떻게 될까요? 다시 말해 오브젝트 파일을 링킹하는 단계에서 IAT에 실제 임포트하는 함수의 주소를 채워 넣을 수 있다면? 당연히 성능 향상에 많은 도움이 될 것입니다. 이러한 기능을 pre-binding이라고 합니다. 앞에서 살펴본 calc.exe의 경우 pre-binding이 적용되어 있는 것입니다. 이처럼 pre-binding되어 있는 상태를 일컫을 때 간단히 DLL이 바운드 되었다고 표현합니다. 그렇다면 로더의 입장에서 DLL이 바운드되었는지는 어떻게 알 수 있을까요? 여기에 대한 해답은 bound import table (BIT)에서 찾을 수 있습니다. BIT의 주소는 데이터 디렉토리의 12번째 엔트리인 IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT에서 찾을 수 있습니다. 아래의 그림을 봐주세요.
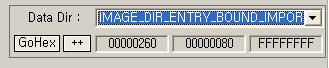 그림 8. StudPE를 이용하여 살펴본 calc.exe의 BIT 관련 정보
StudPE를 이용하여 BIT의 위치를 확인해 보았습니다. RVA값이 0x260이고 사이즈가 0x80임을 알 수 있습니다. RawOffset은 우리의 똑똑하신 StudPE가 계산을 못하고 있습니다. ㅠ.ㅠ;; Stupid라고 불러야 할지... 앞의 [그림 3]을 살펴보면 BIT는 섹션에 위치하고 있지 않음을 알 수 있습니다. (RVA값 0x260은 어느 섹션에도 속하지 않습니다.) 이러한 경우 RVA값이나 RawOffset 값은 동일한 값이 됩니다. 따라서 WinHex를 이용하여 파일내 offset 0x260으로 이동해 보면 BIT를 찾을 수 있을 것입니다. 아래의 그림을 봐주세요.
그림 9. calc.exe의 BIT
BIT의 첫번째 4bytes는 TimeDateStamp 값입니다. 이 값은 매우 중요한데 이에 대해서는 뒤에서 다시 이야기 하도록 하겠습니다. 다음 2bytes는 OffsetModuleName이라는 필드로 BIT의 각 엔트리 시작점에서 모듈의 이름까지의 Offset을 의미합니다. 이로서 우리는 SHELL32.DLL이 이미 바운드 되었음을 알 수 있습니다. 다음 2bytes는 NumberOfModuleForwarderRefs라는 값인데. 이 값은 본 연재에서 다룰 만한 내용이 아니라서 스킵합니다. ^^v
자 이제 로더는 SHELL32.DLL이 이미 바운드 되었음을 알 수 있으므로 SHELL32.DLL과 관련된 IAT를 채우려고 하지 않을 것입니다. [그림 4]에서 [그림 7]까지 나타난 정보를 살펴보면 shell32.dll의 ShellAboutW의 주소는 7744E3DB임을 알 수 있습니다. 이제 이 주소만 확인해 보면 되겠습니다. 아래의 그림을 봐주세요.
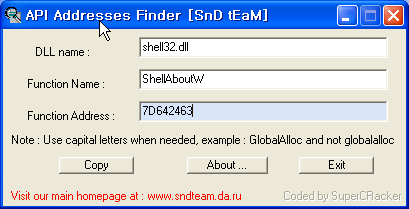 그림 10. API Address Finder를 이용하여 살펴본 ShellAboutW의 주소.
허걱.. 이런 IAT 기록된 주소와 일치하지 않습니다. ^^; 또 하나 더 배울게 생겼습니다. 지금의 상황처럼 DLL이 바운딩된 경우 링크 타임에 IAT에 기록된 API의 주소와 실제 주소가 다른 경우가 발생할 수 있습니다. DLL이 업데이트 된 경우이겠죠. 이러한 경우 IAT의 정보가 변경되지 않는다면 당연히 프로그램은 크래쉬됩니다. 따라서 로더는 DLL이 변경되었음을 감지하고 IAT 테이블을 업데이트 할 수 있어야 합니다. 그렇다면 로더는 DLL이 변경되었음을 어떻게 알 수 있을까요? 다시 [그림 9]를 봐주세요. BIT내 엔트리의 처음 4bytes 값은 TimeDateStamp입니다. 로더는 이 값을 DLL의 PE 헤더에 기록된 TimeDateStamp 값과 비교하여 DLL이 변경되었음을 감지할 수 있습니다. 그럼 shell32.dll의 TimeDateStamp값을 확인해 보겠습니다.
그림 11. Shell32.DLL의 TimeDateStamp
[그림 11]에서 볼 수 있는 것처럼 shell32.dll의 TimeDateStamp값은 [그림 9]에서 확인한 calc.exe의 BIT에 기록된 TimeDateStamp 값보다 큽니다. 로더는 이 정보를 확인하여 shell32.dll이 변경되었음을 알 수 있고 따라서 IAT를 리빌딩하게 됩니다. 이제 마지막으로 calc.exe가 로드된 후 IAT를 살펴보도록 하겠습니다. [그림 2]에 나타난 것처럼 IAT의 RVA가 109c이므로 OllyDbg에서 calc.exe를 실행시킨 후 데이터 덤프 윈도우에서 해당 주소로 이동하면 쉽게 확인할 수 있을 것입니다.
그림 12. 로드된 후 calc.exe의 IAT 모습
지금까지 pre-binding에 대해서 알아보았습니다. 이 정도면 임포트에 관해서 기본적으로 알아야 할 것은 어느 정도 공부한 것 같습니다. 물론 지연 로딩이나 API 포워딩 같은 것들을 좀 더 공부해야 하겠지만 본 연재에서는 다루지 않을 생각이구요... 이 글을 읽는 여러분의 숙제로 남겨 두겠습니다.
다음 이야기는 섹션 테이블에 관한 이야기입니다. 수작업으로 만드는 PE를 좀 더 빨리 완성하기 위해 익스포트 테이블 전에 섹션 테이블을 먼저 알아보도록 할 것입니다. 익스포트 테이블은 우리가 만든 PE 파일이 잘 실행되는 것을 보고 즐기면서 천천히 알아보도록 하겠습니다. ^^ 그럼 오늘도 즐핵하세요.
출처 - http://zesrever.tistory.com/60
리버싱 2017. 1. 10. 16:36
여섯번째 이야기입니다. 아마 많은 분들이 기대하시던 내용일 것이라 생각하는데요, 잘 설명할 수 있을지 걱정입니다.이번 이야기는 임포트(import)에 관한 것입니다. 이번 이야기가지금까지의 다른 것들보다 다소 복잡한 것 사실이지만 흔히 생각하는 것처럼 매우 어렵지는 않습니다. 어차피 사람이 만든건데 이해 못할 정도는 아니겠죠. 그럼 시작해볼까요?
[그림 1] 임포트 테이블, ILT, IAT
임포트 테이블(임포트 디렉토리)
임포트 테이블의 구성
[그림 1]에서 볼 수 있듯이 임포트 테이블은 IMAGE_IMPORT_DESCRIPTOR 타입의 엔트리로 구성된 배열로 임포트한 DLL에 대한 정보를 담고 있습니다. [그림 1]에서는 USER32.DLL과 KERNEL32.DLL을 임포트한 모습을 예로 들었습니다. [그림 1]을 살펴보면 임포트 테이블의 각 엔트리가 임포트한 DLL에 하나에 대한 정보를 담고 있음을 확인할 수 있습니다. 또한 마지막 엔트리는 임포트 테이블의 끝을 나타내기 위해 NULL 로 채워져 있습니다. 이는 PE 파일에서 임포트한 DLL 개수에 대한 정보를 따로 관리하지 않음을 의미합니다. 쉽게 이야기해서 PE 파일 내에 임포트한 DLL 개수를 저장하고 있는 필드는 없다는 것이죠. 어쨌든 이러한 이유로 임포트 테이블의 전체 엔트리 개수는 "임포트한 DLL + 1"개가 됩니다.
임포트 테이블을 구성하고 있는 IMAGE_IMPORT_DESCRIPTOR는 아래와 같이 선언되어 있습니다. 그림과 비교해서 살펴보세요.총 5개의 멤버로 구성되어 있습니다.
typedef struct _IMAGE_IMPORT_DESCRIPTOR {
union {
DWORD Characteristics; /* 현재는 사용하지 않습니다. */
DWORD OriginalFirstThunk; /* 이 유니언은 항상 OriginalFirstThunk로만
사용됩니다.*/
} ;
DWORD TimeDateStamp;
DWORD ForwarderChain;
DWORD Name;
DWORD FirstThunk;
} IMAGE_IMPORT_DESCRIPTOR;
OriginalFirstThunk : ILT(Import Lookup Table)를 가르키는 RVA 값입니다. [그림 1]에서 볼 수 있듯이 ILT는 IMAGE_THUNK_DATA로 구성된 배열입니다. IMAGE_THUNK_DATA는 4bytes 타입의 유니언으로 상황에 따라 IMAGE_IMPORT_BY_NAME을 가르키기도 하고, 함수의 주소를 가르키기도 하며, 오디널 값으로 사용되기도 하며 포워더로 사용되기도 합니다. 복잡하죠? 일단 IMAGE_THUNK_DATA가 어떻게 선언되었는지부터 살펴보도록 하겠습니다. [그림 1]과 [그림 2], [그림 3]을 참고하여 아래의 주석을 반복해서 읽어보시면 IMAGE_THUNK_DATA에 대해서 이해하시는 데 도움이 될 것입니다.
typedef struct _IMAGE_THUNK_DATA32
{
union
{
DWORD ForwarderString;
DWORD Function; //[그림 1],[그림 2]를 보면 IAT가 바인딩되기 전에는
// ILT와 마찬가지로 IMAGE_IMPORT_BY_NAME 구조체
// 를 가르키고 있다가, 바인딩 후에는 실제 함수의 주소를
// 가르키고 있는 것을 볼 수 있습니다. 이처럼
// IMAGE_THUNK_DATA가 함수의 주소를 담고 있으면
// Function의 의미로 사용된 것입니다. 참고로 IAT를
// 구성하는 IMAGE_THUNK_DATA는 바인딩 되기 전후의
// 의미가 다른데, 바인딩 전에는 주로 AddressOfData
// 또는 Ordinal의 의미로 사용되다가 바인딩 후에는
// Function의 의미로 사용됩니다. ILT의 경우는 IAT와
// 달라서 바인딩 전후의 모습이 변경되지 않습니다.
// 또한 ILT를 구성하는 IMAGE_THUNK_DATA는
// Function의 의미로 사용되지 않습니다.
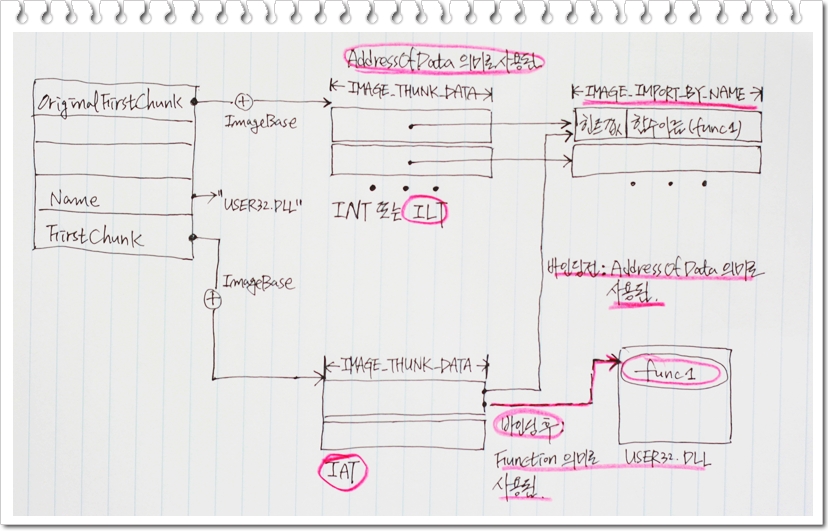
[그림 2] IMAGE_THUNK_DATA 사용(1)
DWORD Ordinal; // [그림 1]에는 ILT를 구성하는 IMAGE_THUNK_DATA
// 가 IMAGE_IMPORT_BY_NAME 구조체를 가르키는 모습만
// 나와있지만 실제로는 [그림 3]처럼 Ordinal 값을 저장
// 하고 있을 수도 있습니다. Ordinal에 대해서는
// 익스포트 섹션에 대해서 알아볼 때 다시 이야기하도록
// 하겠습니다. 다만 지금 기억해두어야 할 것은 대부분의
// 경우 ILT를 구성하는 IMAGE_THUNK_DATA는
// IMAGE_IMPORT_BY_NAME을 가르키는 RVA값
// (AddressOfData)을 저장하거나, Oridinal 값을
// 저장하고 있다는 사실입니다. (IAT를 구성하는
// IMAGE_THUNK_DATA도 바인딩되기 전에는 ILT와 동일한
// 모습을 가집니다) 좀 더 쉽게 이야기하면 ILT는 임포트
// 한 함수에 대한 Ordinal 값을 저장하고 있는 배열이거나
// 임포트한 함수에 대한 이름을 저장하고 있는
// IMAGE_IMPORT_BY_NAME 구조체의 RVA값으로 이루어진
// 배열이라는 이야기죠. IMAGE_THUNK_DATA가
// AddressOfData로 사용되었는지, 아니면 Ordinal로
// 사용되었는지는 MSB의 값으로 판단합니다. 최상위 비트
// 값이 1이면 ordinal로 사용된 것이며, 0이면
// AddressOfData로 사용된 것입니다.
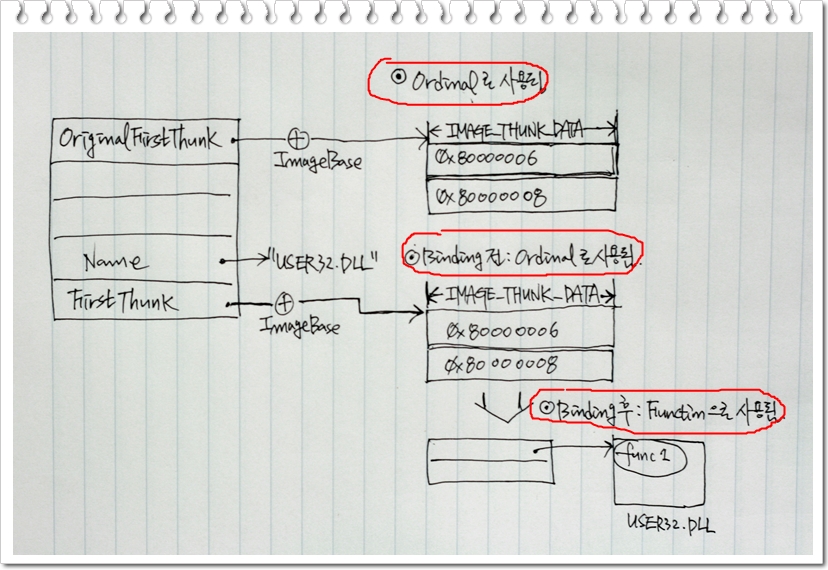
[그림 3] IMAGE_THUNK_DATA(2)
DWORD AddressOfData; // [그림 1],[그림 2]를 보면 ILT를 구성하고 있는
// IMAGE_THUNK_DATA와 IAT를 구성하고 있는
// IMAGE_THUNK_DATA가 바인딩 전에는 모두
// IMAGE_IMPORT_BY_NAME 구조체를 가르키고 있는
// 것을 알 수 있습니다. 이처럼 IMAGE_THUNK_DATA
// 가 IMAGE_IMPORT_BY_NAME을 가르키면
// 바로 AddressOfData의 의미로 사용된 것입니다.
// IMAGE_IMPORT_BY_NAME은 임포트할 함수의 이름을
// 저장하고 있는 구조체입니다.
} u1;
} IMAGE_THUNK_DATA32
IMAGE_THUNK_DATA의 사용에 대해 정리하면 아래와 같습니다.
- OriginalFirstThunk가 가르키는 ILT의 구성 요소로 사용된 IMAGE_THUNK_DATA는 IMAGE_IMPORT_BY_NAME의 주소값을 저장하는 AddressOfData의 의미로 사용되거나, ordinal 값을 저장하는 용도로 사용된다.
- FirstThunk가 가르키는 IAT의 구성 요소로 사용된 IMAGE_THUNK_DATA는 바인딩 전에는 IMAGE_IMPORT_BY_NAME의 주소값을 저장하는 AddressOfData의 의미로 사용되거나, ordinal 값을 저장하는 용도로 사용된다. 바인딩 후에는 실제 함수의 주소를 나타내는 Function의 의미로 사용된다.
- IMAGE_THUNK_DATA가 ordinal 값으로 사용되는 경우 최상위 비트 즉 MSB의 값은 항상 1이다.
TimeDateStamp : 바인딩 전에는 0으로 설정되며 바인딩 후에는 -1로 설정됩니다.
ForwarderChain : 바인징 전에는 0으로 설정되면 바인딩 후에는 -1로 설정됩니다.
Name : 위의 [그림 1],[그림 2],[그림 3]에 나타난 것처럼 임포트한 DLL의 이름을 가르키는 포인터 값입니다.(RVA값)
FirstThunk : IAT(Import Address Table)의 주소(RVA)를 가지고 있습니다. IAT 역시 ILT처럼 IMAGE_THUNK_DATA 배열이며 바인딩 전에는 ILT와 완벽하게 동일한 모습을 가집니다. 하지만 일단 PE 파일이 메모리에 로드된 후에는 로더가 임포트 테이블의 각 엔트리의 네임 정보를 확인한 후 해당 DLL의 익스포트 테이블을 참조하여 함수의 실제 주소를 알아냅니다. 그리고 나서 IAT를 실제 함수 주소로 업데이트 하게 됩니다.
별거 없네요. ^^; 대충 임포트 테이블의 모습과 임포트 과정이 눈에 보이시나요? 임포트 과정에 대해서는 이번 이야기의 마지막에 다시 한번 정리해보겠습니다. 그 전에 임포트 테이블의 위치에 대해서 잠깐 알아보도록 하죠.
임포트 테이블의 위치
임포트 테이블은 보통 임포트 섹션의 시작점에 위치합니다. 또한 각 섹션에 메모리 상의 위치나 파일 상태에서의 위치는 나중에 알아볼 섹션 테이블에 기록되어 있습니다. 이러한 이유에서 인지 몇 몇 문서나 책에서는 파일 상태에서 임포트 테이블의 위치를 찾을 때 섹션 테이블에서 임포트 섹션의 시작 주소를 찾는 방법을 사용하곤 하더군요. 하지만 이 방법은 정확한 방법이 아닙니다. 임포트 테이블이 반드시 임포트 섹션에 위치하는 것이 아니기 때문입니다. 실제로 임포트 섹션을 생성하지 않고 데이터 섹션에 임포트 테이블을 두는 경우도 종종 볼 수 있습니다. 이러한 경우에는 섹션 헤더에 포함된 정보만으로는 임포트 테이블을 찾을 수가 없는 것은 당연하겠죠. 로더의 입장에서 섹션 헤더의 정보는(섹션의 파일상/메모리 상의 위치와 사이즈 정보) 섹션 헤더에 기록된 파일의 위치에서부터 지정된 사이즈 만큼의 데이터를 메모리 상의 지정된 위치로 복사하는데 필요할 뿐 입니다. 그 이상도 그 이하도 아니죠. 더구나 로더는 디스크 상에 임포트 테이블이 어디에 위치하는지 알 필요가 없습니다. 디스크 상에서 임포트 테이블을 찾아 따로 로딩하는게 아니기 때문입니다. 섹션을 로딩하는 과정에서 섹션 데이터의 일부인 임포트 테이블은 자연스럽게 메모리 상에 위치하게 되는 것이죠. 이러한 이유로 메모리에 로드되기 전 즉 파일 상태에서의 임포트 테이블의 위치를 직접적으로 가르키는 정보는 PE 파일 어디에도 저장되어 있지 않습니다. 그럼에도 불구하고 필요에 따라 파일 상에서 임포트 테이블을 찾아야 한다면 그 방법은 데이터 디렉토리에서 찾을 수 있습니다.좀 더 자세히 알아볼까요? 데이터 디렉토리의 두번째 엔트리인 IMAGE_DIRECTORY_ENTRY_IMPORT에는 임포트 테이블이 시작되는 가상 주소의 RVA값과 사이즈가 저장되어 있습니다. 파일 상태에서야 임포트 테이블의 주소를 알 필요가 없었지만, PE 파일이 메모리에 완전히 로드된 다음에는 임포트 테이블을 찾아 임포팅에 필요한 작업을 해주어야 하기 때문에 이러한 정보를 유지하고 있는 것이죠. 어쨌든 임포트 테이블의 RVA 값을 알 수 있다면 파일 상태에서의 임포트 테이블의 위치도 어렵지 않게 알 수 있습니다. 아래 [그림 4]를 봐주세요.
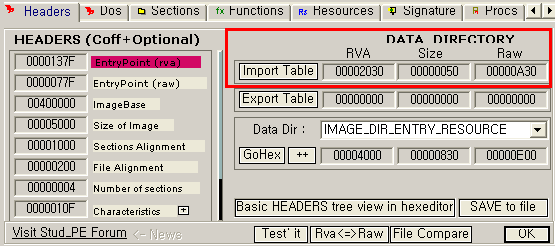
[그림 4] StudPE로 살펴본 Import Table 정보
[그림 4]의 빨간 박스 부분을 살펴보면 재미있게도 PE 파일에는 존재하지 않는 정보가 보입니다. "Raw"라는 항목인데요 PE 파일에서 "raw"라는 단어는 메모리에 로드되기 전의 상태를 의미합니다. [그림 4]에서의 "Raw"는 RawOffset 즉 파일 상에서의 위치를 의미하는 것이겠죠. 지난 이야기에서 알아본 바와 같이 데이터 디렉토리에는 VirtualAddress와 Size 정보 밖에는 없습니다. 그렇다면 StudPE는 어떠한 방법으로 파일 상에서의 임포트 테이블의 위치를 알 수 있었을까요? [그림 5]을 봐주세요.
[그림 5] StudPE로 살펴본 섹션 테이블 정보
[그림 5]에서 살펴본 임포트 테이블의 RVA값은 0x2030 입니다. 따라서 임포트 테이블은 [그림 5]에 나타난 섹션 중 .rdata 섹션에 위치하고 있음을 알 수 있습니다. .rdata 섹션(RVA 0x2000)의 RawOffset 즉 파일 상에서의 위치가 0xA00 이므로, 임포트 테이블(RVA 0x2030)의 파일 상의 위치는 당연히 0xA30이 되겠죠. 생각보다 쉽네요. 지금까지의 내용을 정리해 보겠습니다. - 임포트 섹션이 존재하는 경우 임포트 테이블은 대부분 임포트 섹션의 시작점에 위치한다. 하지만 반드시 시작점에 있어야 하는 것은 아니며 임포트 섹션내 아무 곳에나 위치하는 것이 가능하다
- 임포트 테이블은 임포트 섹션에만 존재해야 하는 것은 아니다. 다시 말해 임포트 섹션을 생성하지 않고 데이터 섹션등에 임포트 테이블을 두는 것이 가능하다.
- 섹션 헤더에 포함된 임포트 섹션에 대한 정보는 로딩 과정 중 파일 상에서 임포트 섹션을 식별하고 메모리에 로딩하기 위해 사용할 뿐이다. 임포트 섹션에 대한 섹션 헤더 정보는 임포트 과정과는 무관하다.
- PE 파일이 메모리에 로딩되고 나면 임포트 어드레스 테이블(IAT)을 수정해 주어야 한다. 따라서 로더는 메모리 상에서 임포트 테이블(IAT의 주소 정보를 가지고 있음)의 위치를 알 수 있어야 하는데, 이 정보는 데이터 디렉토리의 두번째 엘리먼트인 IMAGE_DIRECTORY_ENTRY_IMPORT 에 저장되어 있다.
- 로더가 파일 상태에서의 임포트 테이블의 위치를 알 필요는 없기 때문에 PE 파일 포맷 내에 임포트 테이블의 RawOffset 값을 직접 저장하고 있는 필드는 존재하지 않는다.
- 파일 상태에서 임포트 테이블의 주소는 섹션 헤더 정보와 데이터 디렉토리에 기록된 정보를 비교하여 확인할 수 있다.
임포트 테이블을 메모리상에서 또는 파일 상에서 어떻게 찾아야 하는지 감이 좀 잡히셨나요? [그림 1]의 그림이 메모리상에서 임포트 테이블의 위치를 나타내고 있다는 사실도 이해되시죠? 이제 임포트에 대한 이야기를 마무리 할 시간이 된 것 같습니다.
임포트 과정
지금부터는 [그림 1]을 봐주시면 됩니다. 임포트와 관련되어 알아두어야 할 구조체는 임포트 테이블을 구성하는 IMAGE_IMPORT_DESCRIPTOR와 ILT와 IAT를 구성하는 IMAGE_THUNK_DATA 그리고 임포트할 함수의 이름을 저장하고 있는 IMAGE_IMPORT_BY_NAME 뿐입니다. 사실 그 다지 복잡할 것이 없는 구조이죠. 각 구조체간의 관계는 [그림 1]을 통해 정리하시면 되겠습니다.
지금까지의 내용만으로도 충분히 임포트 과정을 이해할 수 있을 것이라 생각합니다만, 그래도 한 번 더 정리해 보도록 하겠습니다.
1. PE 파일을 메모리에 로드한 후 데이터 디렉토리의 두번째 엔트리인 IMAGE_DIRECTORY_ENTRY_IMPORT로 부터 임포트 테이블의 주소를 구한다.
2. 임포트 테이블을 구성하는 각각의 IMAGE_IMPORT_DESCRIPTOR로 부터 임포트 할 DLL의 이름을 알아낸다.
3. 해당 DLL을 위한 공간을 확보하고 DLL을 메모리에 맵핑시킨다.
4. ILT(Import Lookup Table)로 부터 임포트할 함수의 이름 또는 ordinal 값을 알아낸다.
5. 위의 정보를 이용하여 임포트할 DLL의 익스포트 테이블로 부터 실제 함수의 주소를 알아낸다.
6. 알아낸 함수의 주소를 IAT에 기록한다.
-.-; 비교적 간단하지 않나요? IAT를 업데이트 하는 것은 로더의 몫이므로 우리는 바인딩 전의 모습만 정확하게 만들어 주면 되겠습니다. 그런데 작업하기 전에 한가지를 더 알아야 하겠군요. 바로 익스포트에 관련된 정보입니다.
To be Continue ...
출처 - http://zesrever.tistory.com/54
리버싱 2017. 1. 10. 16:33
다섯번째 이야기입니다. 이번 이야기는 좀 짧을 것 같네요. ^^; Data Directory 자체보다는 Data Directory가 가르키는 자료 구조들이 중요하죠. 어쨌든, 자~ 빠.아져 볼.까요?
Data Directory
데이터 디렉토리는 PE 헤더의 마지막에 위치한 128bytes 사이즈의 배열입니다.(여기에 대해서는 사실 확인 작업이 좀 필요할 것 같습니다. 누차 밝혀온 것 처럼 데이터 디렉토리는 옵션이어서 존재하지 않을 수도 있고 존재하는 경우 16개의 엔트리를 가져야 한다고 했습니다. 이호동님께서 저술하신 "Windows 시스템 실행 파일의 구조와 원리"의 76page 표2-4와 80page의 설명을보면 데이터 디렉토리의 엘리먼트 개수는 무조건 16이라고 못박아 놨더군요. 하지만 최근의 인터넷 상의 논의들을 살펴보면 반드시 16개일 필요는 없는 것 같습니다. 제가 직접 확인해보지 못한 관계로 사실로 규정하기는 어렵지만, 사실 실험 자체가 어려운 것은 아니라 곧 확인하고 연재 마치기 전에 결과를 말씀드리도록 하겠습니다. ) 각 배열 구성 요소(이하 엘리먼트)들은 IMAGE_DATA_DIRECTORY 타입을 가지는데 아래와 같이 정의 되어 있습니다.
typedef struct _IMAGE_DATA_DIRECTORY {
DWORD VirtualAddress;
DWORD Size;
} IMAGE_DATA_DIRECTORY, *PIMAGE_DATA_DIRECTORY;
Optional Header의 뒷부분에 있던 NumberOfRvaAndSize 라는 이름의 필드가 데이터 디렉토리의 엘리먼트 수를 저장하고 있다고 했던 것 기억나시죠? 위 구조체를 보면 필드의 이름에 이유가 있음을 알 수 있을 것입니다.
데이터 디렉토리의 각 엘리먼트는 익스포트 테이블, 임포트 테이블 등 PE 파일에서 중요한 역할을 담당하는 개체들의 위치(VirtualAddress)와 크기(Size)에 대한 정보를 가지고 있습니다. 아래 데이터 디렉토리의 전체적인 모양을 그려두었습니다.
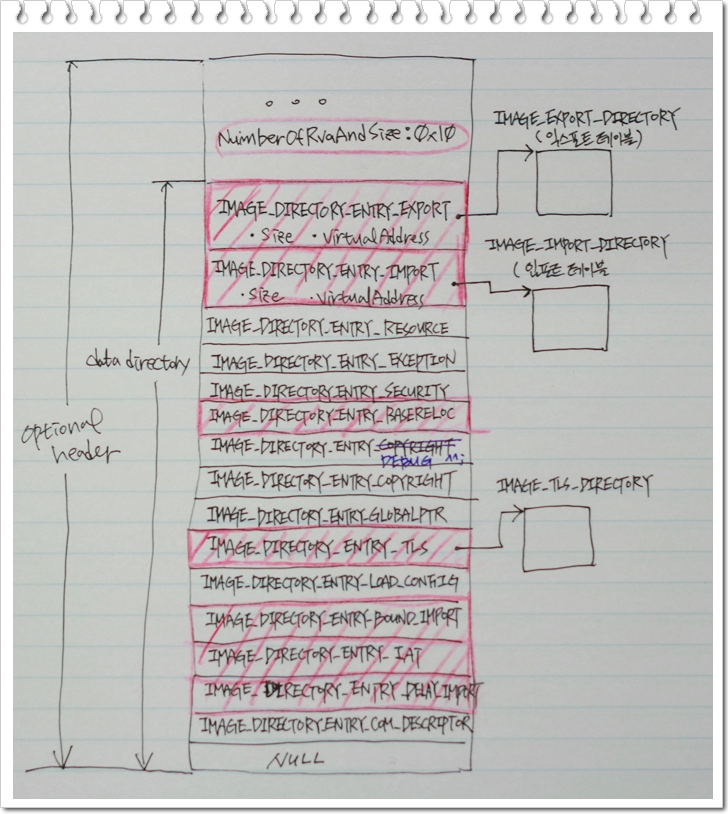
위 그림에 나타나있는 데이터 디렉토리내의 엘리먼트의 데이터 타입은 이름만 다르고 실제 모양은 모두 같습니다. 예를 들어 IMAGE_DIRECTORY_ENTRY_EXPORT도 IMAGE_DATA_DIRECTORY 로 정의되어 있으며 IMAGE_DIRETORY_ENTRY_IMPORT도 IMAGE_DATA_DIRECTORY로 정의되어 있습니다. 또한 0-15번까지의 엔트리만 유효한 값을 가지고 있으며 맨 마지막 엘리먼트는 데이터 디렉토리의 끝을 나타내기 위해 8byte 전체가 0x00으로 채워져 있습니다. (이것만 봐도 데이터 디렉토리의 엘리먼트가 꼭 16개가 아니라도 될 것 같다는 생각이 듭니다. 16개로 고정되어 있는 것이라면 끝을 나타내는 엘리먼트가 필요없겠죠)
15개의 엘리먼트 모두를 알아두어야 하는 것은 아닙니다. 일단 색칠되어 있는 부분들은 알아야 하는데 처음 공부하는 분들은 첫번째 엘리먼트(EXPORT), 두번째 엘리먼트(IMPORT), 열번째 엘리먼트(TLS) 정도만 공부하면 되겠습니다. 좀 더 익숙해지면 지연로딩에 관련된 항목들도 공부해야 하는데 처음부터 완벽할 필요는 없죠. ^^;
IMAGE_DIRECTORY_ENTRY_EXPORT : 익스포트 테이블의 메모리 상에서의 시작점과 크기에 대한 정보를 가지고 있습니다. 익스포트 테이블은 대부분 DLL에 존재합니다. 익스포트 테이블에 대한 자세한 이야기는 뒤에서 다루도록 하겠습니다.
IMAGE_DIRECTORY_ENTRY_IMPORT : 임포트 테이블의 메모리 상에서의 시작점과 크기에 대한 정보를 가지고 있습니다. 아마 가장 먼저 공부해야 하고 가장 잘 알아야 하는 부분일 것 같습니다. 리버싱을 하다보면 메뉴얼 언패킹을 하는 경우가 있는데, 이 때 이 엘리먼트가 가르키는 임포트 테이블에 대한 지식이 매우 유용하게 사용되기 때문이죠. 여섯번째 이야기가 바로 임포트 테이블에 관한 것입니다. ^^;
IMAGE_DIRECTORY_ENTRY_BASERELOC : 재배치와 관련된 데이터 구조에 대한 시작점과 크기 정보를 가지고 있습니다. 재배치는 일반 EXE 파일과는 무관하며 DLL과 연관되어 있습니다. 역시 자세한 이야기는 뒤에서 살펴보도록 하죠 ^^;
IMAGE_DIRECTORY_ENTRY_TLS : 리버서의 입장에서 TLS는 TLS callback 함수를 이용한 안티 리버싱 테크닉 때문에 알아두어야 합니다. 자세한 이야기는 여기를 참고하세요.
PE 제작하기 4 : 데이터 디렉토리 채우기
Step 1: 데이터 디렉토리를 위한 공간 128bytes를 추가합니다. MyFirstPE를 열어 Ctrl+0(숫자)을 누른후 128bytes를 추가하면 되겠습니다. 완성된 모습은 아래와 같습니다.

끝났습니다. ㅠ.ㅠ; 어이없죠? 사실 우리는 MessageBox를 임포트해서 사용할 것이기 때문에 두번째 데이터 디렉토리와 열세번째 데이터 디렉토리를 채워줘야 하는데요... 이 작업은 여섯번째 이야기에서 하려고 합니다. 아무래도 임포트를 이해해야 하기 때문에...
맺음말
^^; 지금은 오후 9시입니다. 허무해 하신 분들을 위해 빨리 작업해서 이 밤이 다가기 전에 여섯번째 글을 올리도록 하겠습니다. 즐핵하세요~
출처 - http://zesrever.tistory.com/59
리버싱 2017. 1. 10. 16:31
네번째 이야기입니다.점점 복잡해지기 시작하네요. 그렇다고 매우 어렵거나 이해하기 어려운 정도의 수준은 아니니까 편한 마음으로 읽어보시기 바랍니다. 지난 세번째 이야기에서는 PE Header 중 FileHeader 부분까지 알아보았습니다. 이번 이야기는 PE 파일의 구성 요소 중에서도 가장 중요한 OptionalHeader에 대해서 알아보려고 합니다.
[그림 1] Optional Header
Optional Header
한번쯤 구글 신에서 PE 파일에 대한 기도를 올려보신 분들은 익히 들어서 알고 계시겠지만 Optional Header는 그 이름과는 다르게 절대로 옵션이 아닙니다. Optional Header는 PE 파일의 논리적 구조에 대한 매우 중요한 정보를 담고 필수 적인 구성 요소입니다. [그림 1]에서 볼 수 있듯이 PE 헤더의 마지막 구성 요소인 Optional Header는 30개의 필드와 1개의 데이터 디렉토리로 구성되어 있습니다. 필드 수부터 압박을 느끼게 하는 군요. 하지만 매우 다행스럽게도 지금까지 알아본 다른 헤더와 마찬가지로 전체 필드를 모두 알아야 하는 것은 아닙니다. Optional Header를 구성하는 30개의 필드 중 알아두어야 하는 필드는 대략 열 몇개 정도입니다. 먼저 알아두어야 할 필드들을 하나씩 살펴보도록 하겠습니다.
- Magic(2bytes) : Optional Header의 시작 위치에 존재하는 필드로 Optional Header를 구분하는 시그너춰로 사용됩니다. 이 값은 0x10B로 고정되어 있습니다.
- AddressOfEntrypoint(4bytes) : 흔히 엔트리 포인트라고 부르는 필드로 PE 파일이 메모리에 로드된 후 맨 처음 실행되어야 하는 코드의 주소를 담고 있습니다. 주소값이므로 당연히 4bytes 사이즈를 가지겠죠. 주의할 점은 이 필드에는 Virtual Address가 아닌 RVA 값 즉 ImageBase로 부터의 offset 이 기록된다는 사실입니다. 일반적으로 엔트리 포인트는 .text 섹션(실행 코드를 담고 있는 메모리 영역)의 시작점인 경우가 대부분이기 때문에 이 값은 후에 알아볼 .text 섹션 헤더의 VirtualAddress 값과 일치하는 경우가 많습니다. (섹션 헤더에 있는 VirtualAddress는 해당 섹션의 메모리 상의 시작점을 가르킵니다.) 이 필드에 대해서는 이번 이야기의 후반부에 PE를 제작할 때 좀 더 자세히 알아보게 될 것입니다.
- ImageBase(4bytes) : 여러 차례 언급되었던 내용이죠. 로더는 PE 파일을 로드할 때 ImageBase값을 참조하여 가급적이면 ImageBase부터 로드하려고 시도합니다. EXE 파일의 경우 가상 메모리 공간에 가장 처음 로드되므로 항상 ImageBase에 로드됩니다. 하지만 DLL의 경우 ImageBase로 지정된 주소 공간이 다른 모듈에 의해서 이미 사용 중인 상황이 발생할 수 있습니다. 이러한 경우 로더는 해당 DLL을 다른 곳에 로드하고 재배치를 작업을 수행하게 됩니다. 대부분의 링커는 이 값을 0x00400000(EXE의 경우), 0x10000000(DLL의 경우) 로 설정합니다. 이 값은 링커 옵션 중 BASE 옵션을 이용하여 수정이 가능합니다.
- SectionAlignment(4bytes) : Alignment(정렬)는 아키텍쳐와 깊은 연관 관계를 가지고 있는 개념으로 퍼포먼스에 많은 영향을 끼칩니다. 자세한 내용은 구글신에게 기도를 드려보시고 응답이 없으시면 따로 질문해주세요. 네번째 이야기는 좀 내용이 많아 alignment에 대한 개념은 생략하겠습니다. 어쨌든 Section Alignment는 각 섹션이 메모리 상에서 차지해야 하는 최소의 단위로 이해하시는 것이 정신 건강에 좋습니다. 예를들어 Section Alignment의 값이 4096이고 .text 섹션의 크기가 100bytes라면 실제로 메모리 상에서 .text 섹션은 4096bytes를 차지하게 된다는 것이죠. 만약 .text 섹션이 5000bytes라면 어떻게 될까요? Section Alignment는 단위라 했으므로 총 2개 단위 즉 8192 bytes만큼을 차지하게 될 것입니다. 더불어 이러한 이유때문에 각 섹션은 Section Alignment x n의 위치에서 시작하게 됩니다.[그림 2]를 참고하세요. PE에 대한 공식/비공식적인 문서를 살펴보면 Section Alignment 먼트는 page 사이즈 즉 4096보다 작을 수 없다고 되어 있습니다. 재미있는 사실은 이러한 진술과는 무관하게 linker 옵션 중 ALIGN 옵션을 이용하면 4096보다 작은 값을 지정할 수 있다는 것이구요. 실제로 제한적인 상황에서는 Section Alignment 값이 4096보다 작아도 실행하는데는 지장이 없다는 것입니다. 여기까지의 내용이 복잡하면 지금은 이렇게만 알아두면 되겠습니다.
- 메모리 상에서 각 섹션은 Section Alignment x n 번지에서 시작한다.
- 메모리 상에서 하나의 섹션은 Section Alignment x m 사이즈를 가진다.
- 일반적으로 Section Alignment의 값은 페이지 사이즈와 동일한 4096 값을 사용한다.
- FileAlignment : SectionAlignment가 메모리 상에서의 섹션 정렬과 관련있었다면 FileAlignment는 디스크 상에서의 섹션 정렬과 관련있는 필드입니다. 개념은 SectionAligment와 동일합니다. 이 값은 512부터 65535사이의 2의 n승 형태의 값을 사용하도록 약속되어 있습니다. 512, 1024, 2048 ... 뭐 이런식이죠. 우리는 512를 사용할 것입니다. (만약 이 값이 SectionAlignment와 동일하다면 디스크 상의 PE 파일의 모습이나 메모리 상의 PE 파일 모습은 예외적인 상황을 제외하면 100% 같습니다.
- SizeOfImage : 메모리 상에 로드된 PE 파일의 총 사이즈를 의미합니다. 이 값은 SectionAlignment x n의 형태가 됩니다. 자세한 계산 방법은 직접 PE 제작을 하면서 알아보도록 하죠.
- SizeOfHeader : 디스크 상에서의 헤더의 총 사이즈를 의미합니다. 이 부분은 그림을 보고 이해하는 것이 더 좋을 것 같군요. ^^; 아래 [그림 2]를 봐주세요.
[그림 2] PE 파일 각 구성 요소의 사이즈
[그림 2]는 잘 이해해 두는 것이 좋을 것 같습니다. 실제 PE 파일을 제작하기 위해서 꼭 필요한 지식입니다. 위 그림을 보면 SizeOfHeader는 DOS header에서 패딩을 포함한 section header의 끝까지의 사이즈를 의미함을 알 수 있습니다. 이 값은 파일 상태에서 계산한 것으로 항상 FileAlignment x n 값을 가집니다. 실제 PE 파일이 메모리에 로드되면 SizeOfHeaders의 값이 SectionAlignment x n 형태로 변경되어야 하겠지만 이 값 자체는 로더에 의해서만 사용되는 값이라서 메모리에 로드된 후에도 변경되지 않고 그대로 유지됩니다.
- MajorSubsystemVersion, MinorSubsystemVersion : Win32 애플리케이션의 경우 버전을 4.0으로 해야 합니다. 따라서 대부분의 경우 MajorSubsystem 값은 4, MinorSubsystem 값은 0이 됩니다.
- SizeOfStackReserve, SizeOfStackCommit : 이 값은 Stack 영역으로 예약된 메모리의 사이즈와 할당된 메모리의 사이즈 값을 가집니다. 보통 스택 영역으로는 1page를 할당하며 16page를 예약해 둡니다. 따라서 대부분의 경우 SizeOfStackReserve 값은 0x10000, SizeOfStackCommit 값은 0x1000이 됩니다.
- SizeOfHeapReserve, SizeOfHeapCommit : Heap 사이즈에 대한 정보라는 점만 빼고 위와 같습니다.
- Subsystem : Console용 애플리케이션인 경우 Windows CUI(0x3)을 GUI용 애플리케이션인 경우 Windows GUI(0x2)값을 가져야 합니다.
PE 제작하기 3 : Optional Header 만들기(Data Directory 제외, 다음글에서 다룹니다)
중요한 필드들의 정보를 알아보았습니다. 이제 OptionalHeader를 직접 만들어 보도록 하겠습니다. 먼저 OptionalHeader가 어떤 모양으로 선언되어 있는지 살펴보도록 하겠습니다.
typedef struct _IMAGE_OPTIONAL_HEADER {
//
// Standard fields.
//
WORD Magic;
BYTE MajorLinkerVersion;
BYTE MinorLinkerVersion;
DWORD SizeOfCode;
DWORD SizeOfInitializedData;
DWORD SizeOfUninitializedData;
DWORD AddressOfEntryPoint;
DWORD BaseOfCode;
DWORD BaseOfData;
//
// NT additional fields.
//
DWORD ImageBase;
DWORD SectionAlignment;
DWORD FileAlignment;
WORD MajorOperatingSystemVersion;
WORD MinorOperatingSystemVersion;
WORD MajorImageVersion;
WORD MinorImageVersion;
WORD MajorSubsystemVersion;
WORD MinorSubsystemVersion;
DWORD Win32VersionValue;
DWORD SizeOfImage;
DWORD SizeOfHeaders;
DWORD CheckSum;
WORD Subsystem;
WORD DllCharacteristics;
DWORD SizeOfStackReserve;
DWORD SizeOfStackCommit;
DWORD SizeOfHeapReserve;
DWORD SizeOfHeapCommit;
DWORD LoaderFlags;
DWORD NumberOfRvaAndSizes;
IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
} IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
컥~ 정말 많습니다. 뭐 안될 것 있겠습니까? 일단 부딪혀보도록 하죠.
Step 1: 먼저 데이터 디렉토리를 제외한 나머지 필드들을 채워나갈 것이므로 96bytes 사이즈의 빈 공간을 생성합니다. 그 다음 Magic 넘버(2bytes)를 기록해야 하겠습니다. 앞에 설명한 대로 0x10B로 채우면 됩니다. 리틀엔디언 잊지 마시구요. 그 다음에는 MajorLinkerVersion과 MinorLinkerVersion을 채워야 하겠습니다. 위 구조체 선언에서 알 수 있는 것처럼 각 각 1byte를 차지하고 있습니다. 고맙게도 이 필드는 0으로 채워도 실행에는 아무런 지장이 없습니다. 0으로 채우도록 합니다.

Step 2: SizeOfCode와 SizeOfInitializedData, SizeOfUninitializedData를 채울 차례군요. 먼저 이 필드들의 값은 Windowx XP에서 실험해 본 결과 실행과는 별 상관없어 보입니다. 따라서 이 값을 0으로 채워도 무방하겠습니다.(물론 이 필드로부터 Code 사이즈등을 읽어내는 프로그램이 있다거나 ntdll.dll에 구현된 로더가 이 값을 참조하도록 수정된다면 이야기가 달라지겠죠) SizeOfCode는 IMAGE_SCN_CNT_CODE 속성을 가진 섹션들의 총 사이즈를 담고 있는 값입니다. FileAlignment x n 형태의 값을 가지게 됩니다. 이미 언급한대로 0으로 채워도 무방하지만 조금더 성의를 보여 0x200(512bytes, 나중에 FileAlignment 값으로 512를 사용할 것입니다. 또한 우리가 사용할 코드는 메시지 박스 하나 띄우는 코드라 512bytes 안에 충분히 들어갈 것 입니다.) SizeOfInitializedData와 SizeOfUninitizedData는 각각 IMAGE_SCN_CNT_INITIALIZED_DATA 속성과 IMAGE_SCN_CNT_UNINITIALIZED_DATA 속성을 가지는 섹션의 총 사이즈입니다. 실행과 별 관계없으므로 설명을 간략하게 하기 위해 일단 0으로 채우도록 하겠습니다.
Step 3: 으흠.. 첫번째 고비를 만났습니다. ^^; AddressOfEntryPoint 값을 채워넣어야 하겠습니다. 반드시 그럴 필요는 없지만 일반적으로 AddressEntryOfEntryPoint는 코드 섹션(.text)의 시작점을 가르키는 경우가 대부분입니다. MyFirstPE.exe 역시 .text 섹션의 시작점을 AddressOfEntryPoint로 삼을 것입니다. 그렇다면 이미지 상태의 PE 파일(메모리에 로드된 PE파일)에서 첫번째 섹션의 시작점을 계산해보면 되겠군요.(코드 섹션인 .text를 MyFirstPE.exe의 첫번째 섹션으로 등록할 것입니다. 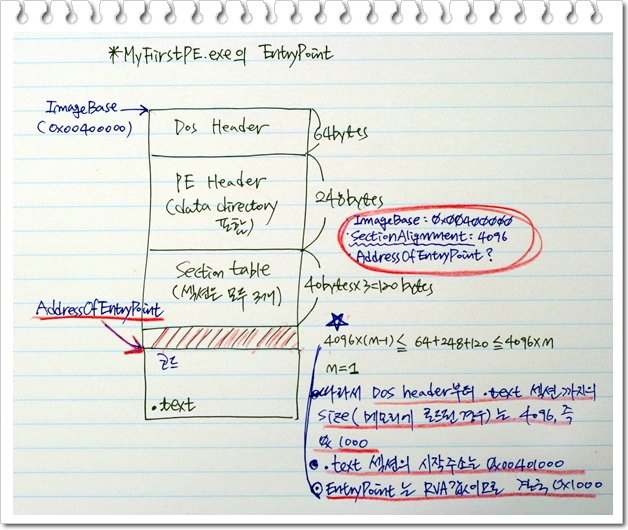 물론 .text 섹션이 반드시 첫번째 섹션일 필요는 없습니다.) 옆의 그림을 봐주세요.옆의 그림을 이해하는데 가장 중요한 사실은 이미지 상태의 PE 파일에서 각 섹션은 SectionAlignment x n 번지에서 시작해야 한다는 것입니다. ImageBase값을 0x00400000 설정할 것이므로 그 다음 alignment 지점은 0x00401000이 되겠군요. 또한 DOS header부터 section table까지의 총 사이즈가 0x1000 bytes를 초과하지 않으므로 0x00401000이 이미지 상태에서 .text 섹션의 시작 주소가 됩니다. AddressOfEntryPoint는 RVA 값이므로 0x00401000 - 0x00400000 = 0x1000이 됩니다. Alignment에 대한 개념만 확실하면 그리 어렵지 않은 문제죠. 이제 AddressOfEntryPoint의 값을 0x1000으로 설정해 주세요.
Step 4: BaseOfCode와 BaseOfData를 채워나갈 차례입니다. PE를 공부하다보면 가끔 의아할 때가 있는데요 이 필들들도 그러한 느낌을 받게 하는군요. 이 필드들은 매우 중요해 보이지만 실제로 ntdll.dll에 구현되어 있는 로더는 이 필드를 사용하지 않는 것 같습니다. 모두 0x0으로 채워도 실행에는 아무런 문제가 없습니다. 그래도 표준을 따른다는 의미로 정상적인 값으로 채워보도록 하죠. 이 필드는 코드 섹션의 시작점과 데이터 섹션의 시작점을 가르키는 RVA 값입니다. 우리의 경우 BaseOfCode는 0x1000, BaseOfData는 0x2000 으로 하면 되겠습니다. (이해되지 않으면 Step 8의 그림을 참조하세요.)
Step 5: ImageBase는 0x00400000 으로 설정하겠습니다.
Step 6: SectionAlignment는 0x1000, FileAlignment는 0x200으로 채우도록 하겠습니다.
Step 7: MajorOperatingSystemVersion 부터 Win32VersionValue는 아래 그림과 같이 채워주세요. 자세한 내용은 구글신에게 기도롤... (Windowx XP에서 테스트해 본 결과 MajorSubsystemVersion 외에는 실행에 영향을 끼치지 않습니다. )
Step 8: SizeOfImage는 아래의 그림 하나로 설명이 될 것 같군요. ^^ 0x4000으로 채웁니다.
Step 9: SizeOfHeaer값을 채울 차례입니다. 설명은 앞에서 했습니다. 0x200(512)으로 채웁니다.
Step 10: 이번에는 Checksum 값이네요. 다행스럽게도 이 값은 사용되지 않습니다. 0x0으로 채웁니다.
Step 11: Subsystem입니다. 우리는 메시지 박스를 띄울 것이므로 Win32 GUI로 해야 겠습니다. 이 값을 0x2로 채웁니다.
Step 12: DllCharacteristics 입니다. 이 값은 DLL 초기화 함수(DllMain)를 언제 호출해야 하는지를 나타내는 flag 값입니다. 이 값은 아래와 같이 정의되어 있습니다만, 실제로 0x0으로 설정하여도 정상적으로 잘 동작합니다.(DllMain 함수는 실제로 아래의 값과 관계없이 항상 호출되는 것 같습니다.)
| 1 | Call when DLL is first loaded into a process's address space | | 2 | Call when a thread terminates | | 4 | Call when a thread starts up | | 8 | Call when DLL exits |
일단 0x0으로 채우겠습니다.
Step 13: SizeOfStackReserve, SizeOfStackCommit, SizeOfHeapReserve, SizeOfHeapCommit은 앞에서 설명한 대로 각각 16page(0x10000), 1page(0x1000) 값으로 채웁니다.
Step 14: LoaderFlags : 지금은 사용하지 않는 필드입니다. Thanks.. 0x0 으로 채웁니다.
Step 15: 드디어 마지막입니다. NumberOfRvaAndSizes 차례군요. Windowx XP에서 실행한 결과 실행과는 별 관계없는 값이기는 합니다만, 마지막이고 하니 즐거운 마음으로 알아보죠. 이 필드는 쉽게 이야기하면 데이터 디렉토리 엔트리 개수라고 보시면 됩니다. 데이터 디렉토리가 옵션이기 때문에 필요한 필드죠. 우리는 데이터 디렉토리가 필요하므로 이 값은 0x10 즉 16으로 설정하면 되겠습니다.
(나중에 알아볼 기회가 있겠지만 LoaderFlags와 NumberOfRvaAndSizes는 안티 리버싱에 사용됩니다.)
맺음말
좀 긴 글이었던 것 같습니다. 그림도 많고. ^^; 포기하지 마시고 끝까지 고고싱~ 입니다. 다음글은 Data Directory에 관한 것입니다. 그럼 즐핵~ 하세요.
출처 - http://zesrever.tistory.com/58
리버싱 2017. 1. 10. 16:29
세번째 이야기입니다. 이번에는 PE 헤더에 대해서 알아보도록 하겠습니다. PE 헤더는 좌측의 [그림 1]과 같이 크게 3부분으로 이루어져 있습니다. 첫번째 부분은 PE signature 로 이 값은 "50 45 00 00" 으로 고정되어 있습니다. 두번째 부분은 20bytes 고정 사이즈를 가지는 파일 헤더(IMAGE_FILE_HEADER) 입니다. 세번째 부분은 옵셔널 헤더(IMAGE_OPTIONAL_HEADER)로 보통은 224bytes 사이즈를 가지지만 원칙적으로 사이즈는 가변적입니다.
[그림 1] PE 헤더의 구조
보다 자세하게 알아보도록 하겠습니다. 다음은 PE 헤더(IMAGE_NT_HEADERS)의 정의입니다.
typedef struct _IMAGE_NT_HEADERS {
DWORD Signature;
IMAGE_FILE_HEADER FileHeader;
IMAGE_OPTIONAL_HEADER32 OptionalHeader;
} IMAGE_NT_HEADERS32, *PIMAGE_NT_HEADERS32;
PE Signature(Signature)
이미 언급한 대로 4byte 사이즈의 데이터로 이 값은 항상 "50 45 00 00(PE\0\0)"으로 고정되어 있습니다.
FileHeader(IMAGE_FILE_HEADER)
20bytes 사이즈의 구조체입니다. 파일 헤더는 주로 PE 파일의 물리적 모양에 대한 정보를 가지고 있습니다. 파일 헤더는 모두 7개의 필드로 구성되어 있는데 이 중에서 알아두어야 할 필드는 모두 4개 입니다. 구조체 선언을 먼저 살펴보도록 하겠습니다.
typedef struct _IMAGE_FILE_HEADER {
WORD Machine;
WORD NumberOfSections;
DWORD TimeDateStamp;
DWORD PointerToSymbolTable;
DWORD NumberOfSymbols;
WORD SizeOfOptionalHeader;
WORD Characteristics;
} IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
위 필드 중 알아두어야 할 것은 [그림 1]에 명시되어 있는 Machine, NumberOfSections, SizeOfOptionalHeader, Characteristics 뿐입니다. 나머지 필드는 무시하여도 좋으며 직접 생성 시 모두 0으로 채울 것입니다.
- Machine은 CPU ID를 나타내는 데 IA32의 경우 이 값은 0x14c가 되어야 하며 IA64인 경우 0x200이 되어야 합니다.
- NumberOfSections은 말 그대로 섹션의 개수를 의미합니다. 리버싱 중 섹션을 생성하거나 제거할 때는 반드시 이 값을 변경해 주어야 합니다.
- SizeOfOptionalHeader는 파일 헤더 뒤에 오는 옵셔널 헤더의 사이즈를 의미합니다. 이 필드의 존재 자체만으로도 옵셔널 헤더의 사이즈가 고정되어 있지 않다는 사실을 알 수 있습니다. 옵셔널 헤더의 사이즈에 영향을 끼치는 것은 옵셔널 헤더에 포함되어 있는 데이터 디렉토리입니다. 일반적인 경우 데이터 디렉토리가 포함된 옵셔널 헤더는 224bytes를 차지하지만 데이터 디렉토리는 필요없는 경우 생략이 가능하기 때문에 데이터 디렉토리를 포함하지 않는 옵셔널 헤더는 96bytes(데이터 디렉토리의 사이즈는 128bytes 입니다.) 사이즈를 가지게 됩니다.
- Characteristics는 말 그대로 PE 파일의 속성을 의미합니다. 이 필드는 PE 파일이 EXE 파일인지 DLL 파일인지, 재배치가 가능한가와 같은 정보를 담게 됩니다. 일반적인 실행 파일의 경우 0x10F 값을 가집니다. 이는 PE 파일이 EXE 파일이며 재배치 정보를 가지고 있지 않음을 의미합니다. 여기서 잠깐 재배치란 옵셔널 헤더에 지정되어 있는 ImageBase에 PE 파일을 로드할 수 없는 경우 로드 가능한 주소에 PE 파일을 로드하고 실행 코드 내에서 절대 주소 값 등을 변경하는 작업입니다. EXE 파일의 경우 가상 메모리 공간에 가장 먼저 로드되므로 항상 ImageBase에 로드가 가능하여 재배치가 절대로 발생하지 않습니다. 반면 DLL은 상황에 따라 ImageBase에 로드될 수 없는 경우가 발생하기 때문에 (ImageBase에 이미 다른 DLL 등이 로드된 경우) 재배치가 발생할 수 있습니다. MS의 재배치로 인한 성능 저하를 막기 위해 윈도우의 주요 DLL의 ImageBase 값을 세밀하게 조정해 놓았다는 것도 기억해 두면 좋을 것 같습니다.
PE 조립하기 2: PE Signature + FileHeader 생성
옵셔널 헤더는 다음 글에서 알아보도록 하겠습니다. 이번 글에서는 파일 헤더까지만 생성해 보도록 하죠. 먼저 두번째 이야기에서 생성한 MyFirstPE.bin을 WinHex로 열어야 하겠죠.
Step 1. PE 시그너춰와 FileHeader를 위한 공간을 추가합니다. 각각 4bytes와 20bytes이므로 총 24bytes 공간을 추가하면 되겠습니다. WinHex의 경우 Ctrl+0을 누르면 추가 공간을 할당할 수 있습니다. 그림은 생략합니다.
Step 2. [그림 2]에서 처럼 PE 시그너춰를 입력합니다.
[그림 2] PE 시그너춰 입력 (클릭 후 확대해서 보세요)
Step 3. FileHeader를 완성해야 합니다. 제일 먼저 Machine 값을 입력합니다. Machine 값은 IA32일 경우 0x14c로 입력하면 되겠습니다. 입력할 때는 리틀 엔디언임을 고려해서 입력해야 하며 Machine은 2bytes 사이즈를 가지므로 차례대로 4c 01을 입력하면 되겠습니다.
[그림 3] Machine 필드 채움(클릭 후 확대해서 보세요)
Step 4. NumberOfSections 필드를 채울 차례군요. 이 필드는 총 2bytes입니다. 우리가 최종적으로 생성할 실행 파일은 코드를 저장하기 위한 .text 섹션과 상수 데이터를 저장하기 위한 .rdata 섹션 그리고 임포트 한 API에 대한 정보를 담고 있는 .idata 섹션 이렇게 3개의 섹션을 가지게 될 것입니다. 그러므로 이 필드는 리틀 엔디언 방식임을 고려해서 차례대로 03 00 으로 채우면 되겠습니다.
[그림 4] NumberOfSections 필드 채움(클릭 후 확대해서 보세요)
Step 5. TimeDateStamp와 PointerToSymbolTable, NumberOfSymbols 필드를 채웁니다. 이 필드는 각각 4bytes 사이즈를 가집니다. 일단 심볼과 관련된 두 개의 필드(PointerToSymbolTable, NumberOfSymbols)는 거의 사용되지 않는 필드이며 0으로 채워도 무방합니다. TimeDateStamp는 PE 파일이 생성된 시간을 1970년 1월 1일 00시를 기준으로하여 초단위로 기록해야 하는데 Windows XP에서 실험한 결과로는 역시 사용되지 않는 필드인 것 같습니다. 즉 0으로 채워도 실행하는 데는 아무런 지장이 없습니다. 이 필드 역시 0으로 채우겠습니다.
[그림 5] TimeDateStamp, PointerToSymbolTable, NumberOfSymbols 필드 채움
Step 6. SizeOfOptionalHeader를 채울 차례입니다. Optional header는 데이터 디렉토리가 있는 경우 224 bytes, 데이터 디렉토리가 필요없는 경우 96bytes라고 이미 말한 바 있습니다. 우리는 임포트 섹션을 사용해야 하는데 이 경우 IAT 테이블에 대한 정보가 데이터 디렉토리에 기록되어야 하므로 (이에 대해서는 다음 글에서 알아볼 것입니다) 데이터 디렉토리가 필요합니다. 따라서 우리가 만드는 PE 파일의 Optional header 사이즈는 224bytes(0xE0)가 됩니다. 이 필드의 사이즈는 2bytes 이므로 차례대로 "E0 00"으로 채우면 되겠습니다.
[그림 6] SizeOfOptionalHeader 필드 채움
Step 7. 이제 마지막입니다. ^^; Characteristics 필드를 채울 차례군요. 2bytes 사이즈를 가지구요, 대체로 일반적인 애플리케이션은 0x10F 값을 가진다는 사실을 앞에서 알아보았습니다. 0x10F는
Relocation Stripped, Executable Image, Line number stipped, 32bit machine expected 속성을 체크한 결과입니다. ^^; 자세한 내용은 Google 신에게 기도를 드려보세요~ (책임회피성발언...^^)
그렇다면 차례대로 "0F 01"을 채워나가면 되겠군요.
[그림 7] Characteristics 필드 채움
맺음말
그럭저럭 해볼만하지 않은가요? ^^; 다음 이야기는 PE 헤더 중 OptionalHeader에 관한 것입니다. 그럼 즐핵~하세요.
출처 - http://zesrever.tistory.com/57
|






 code.bin
code.bin